声音分类是音频深度学习中应用最广泛的方法之一。它包括学习对声音进行分类并预测声音的类别。这类问题可以应用到许多实际场景中,例如,对音乐片段进行分类以识别音乐类型,或通过一组扬声器对短话语进行分类以根据声音识别说话人。
在本文中,我们将介绍一个简单的演示应用程序,以便理解用于解决此类音频分类问题的方法。我的目标不仅仅是理解事物是如何运作的,还有它为什么会这样运作。
音频分类
就像使用MNIST数据集对手写数字进行分类被认为是计算机视觉的“Hello World”类型的问题一样,我们可以将此应用视为音频深度学习的入门问题。
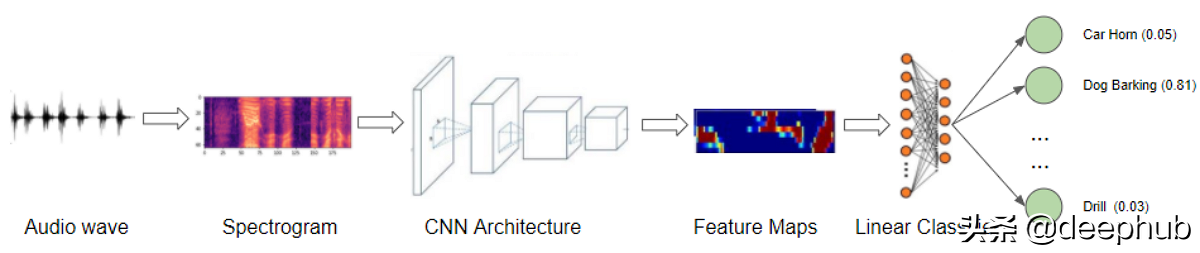
我们将从声音文件开始,将它们转换为声谱图,将它们输入到CNN加线性分类器模型中,并产生关于声音所属类别的预测。
有许多合适的数据集可以用于不同类型的声音。这些数据集包含大量音频样本,以及每个样本的类标签,根据你试图解决的问题来识别声音的类型。
这些类标签通常可以从音频样本文件名的某些部分或文件所在的子文件夹名中获得。另外,类标签在单独的元数据文件中指定,通常为TXT、JSON或CSV格式。
演示-对普通城市声音进行分类
对于我们的演示,我们将使用Urban Sound 8K数据集,该数据集包含从日常城市生活中录制的普通声音的语料库。这些声音来自于10个分类,如工程噪音、狗叫声和汽笛声。每个声音样本都标有它所属的类。
下载数据集后,我们看到它由两部分组成:
“Audio”文件夹中的音频文件:它有10个子文件夹,命名为“fold1”到“fold10”。每个子文件夹包含许多。wav的音频样本。例如“fold1/103074 - 7 - 1 - 0. - wav”
“Metadata”文件夹中的元数据:它有一个文件“UrbanSound8K”。它包含关于数据集中每个音频样本的信息,如文件名、类标签、“fold”子文件夹位置等。类标签是10个类中的每个类从0到9的数字类ID。如。数字0表示空调,1表示汽车喇叭,以此类推。
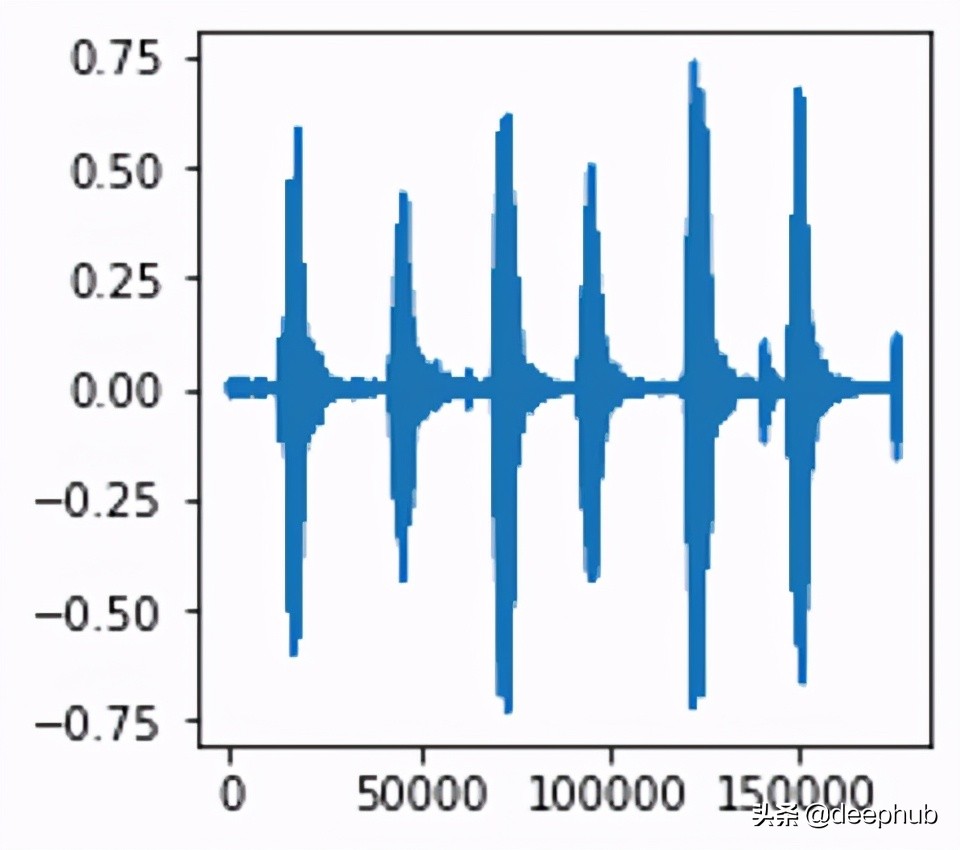
一般音频的长度约为4秒。下面是其中一个例子:
数据集创建者的建议是使用10折的交叉验证,以便计算指标并评估模型的性能。 但是,由于本文的目标主要是作为音频深度学习示例的演示,而不是获得最佳指标,因此,我们将忽略分折并将所有样本简单地视为一个大型数据集。
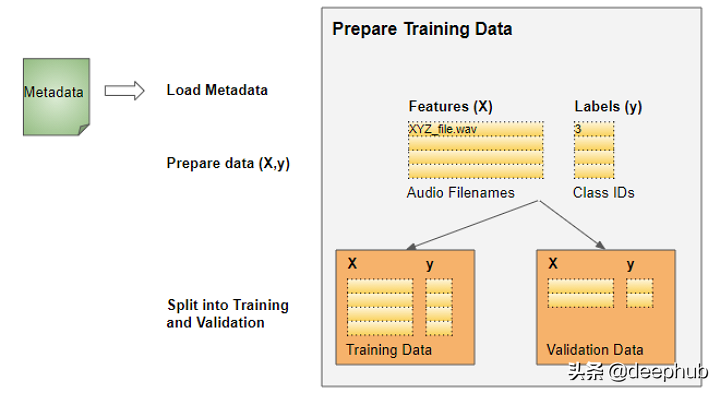
准备训练数据
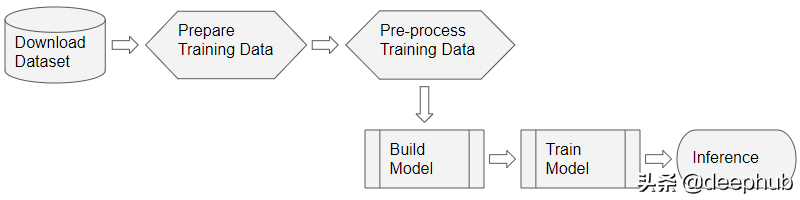
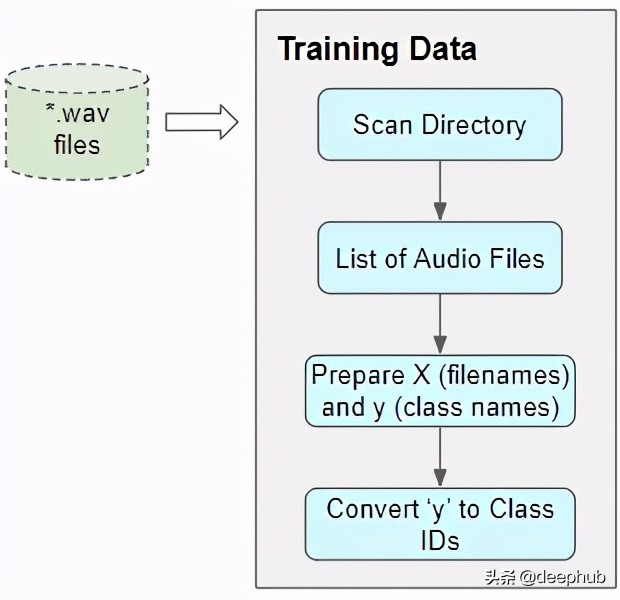
对于大多数深度学习问题,我们将遵循以下步骤:
这个数据集的数据整理很简单:
特性(X)是音频文件路径
目标标签(y)是类名
由于数据集已经有一个包含此信息的元数据文件,所以我们可以直接使用它。元数据包含关于每个音频文件的信息。
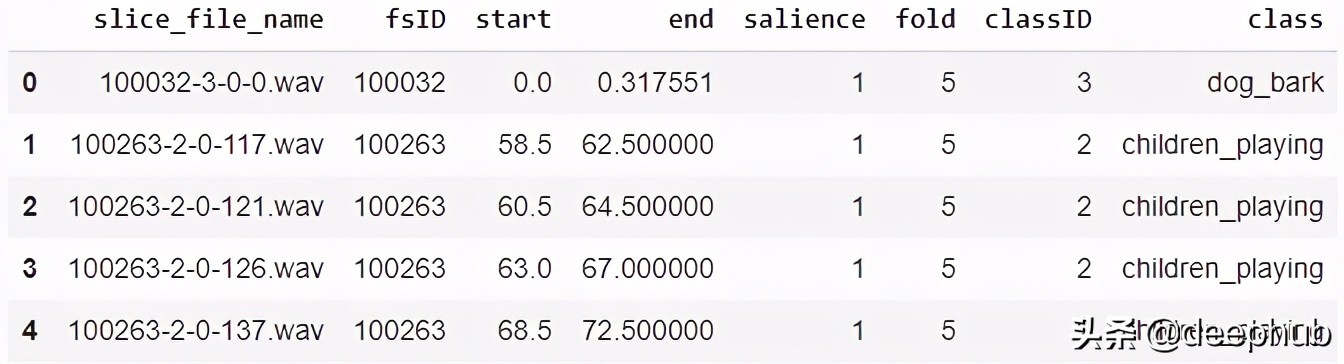
由于它是一个CSV文件,我们可以使用Pandas来读取它。我们可以从元数据中准备特性和标签数据。
- # ----------------------------
- # Prepare training data from Metadata file
- # ----------------------------
- import pandas as pd
- from pathlib import Path
- download_path = Path.cwd()/'UrbanSound8K'
- # Read metadata file
- metadata_file = download_path/'metadata'/'UrbanSound8K.csv'
- df = pd.read_csv(metadata_file)
- df.head()
- # Construct file path by concatenating fold and file name
- df['relative_path'] = '/fold' + df['fold'].astype(str) + '/' + df['slice_file_name'].astype(str)
- # Take relevant columns
- df = df[['relative_path', 'classID']]
- df.head()
我们训练的需要的信息如下:

当元数据不可用时,扫描音频文件目录
有了元数据文件,事情就简单多了。我们如何为不包含元数据文件的数据集准备数据呢?
许多数据集仅包含安排在文件夹结构中的音频文件,类标签可以通过目录进行派生。为了以这种格式准备我们的培训数据,我们将做以下工作:
扫描该目录并生成所有音频文件路径的列表。
从每个文件名或父子文件夹的名称中提取类标签
将每个类名从文本映射到一个数字类ID
不管有没有元数据,结果都是一样的——由音频文件名列表组成的特性和由类id组成的目标标签。
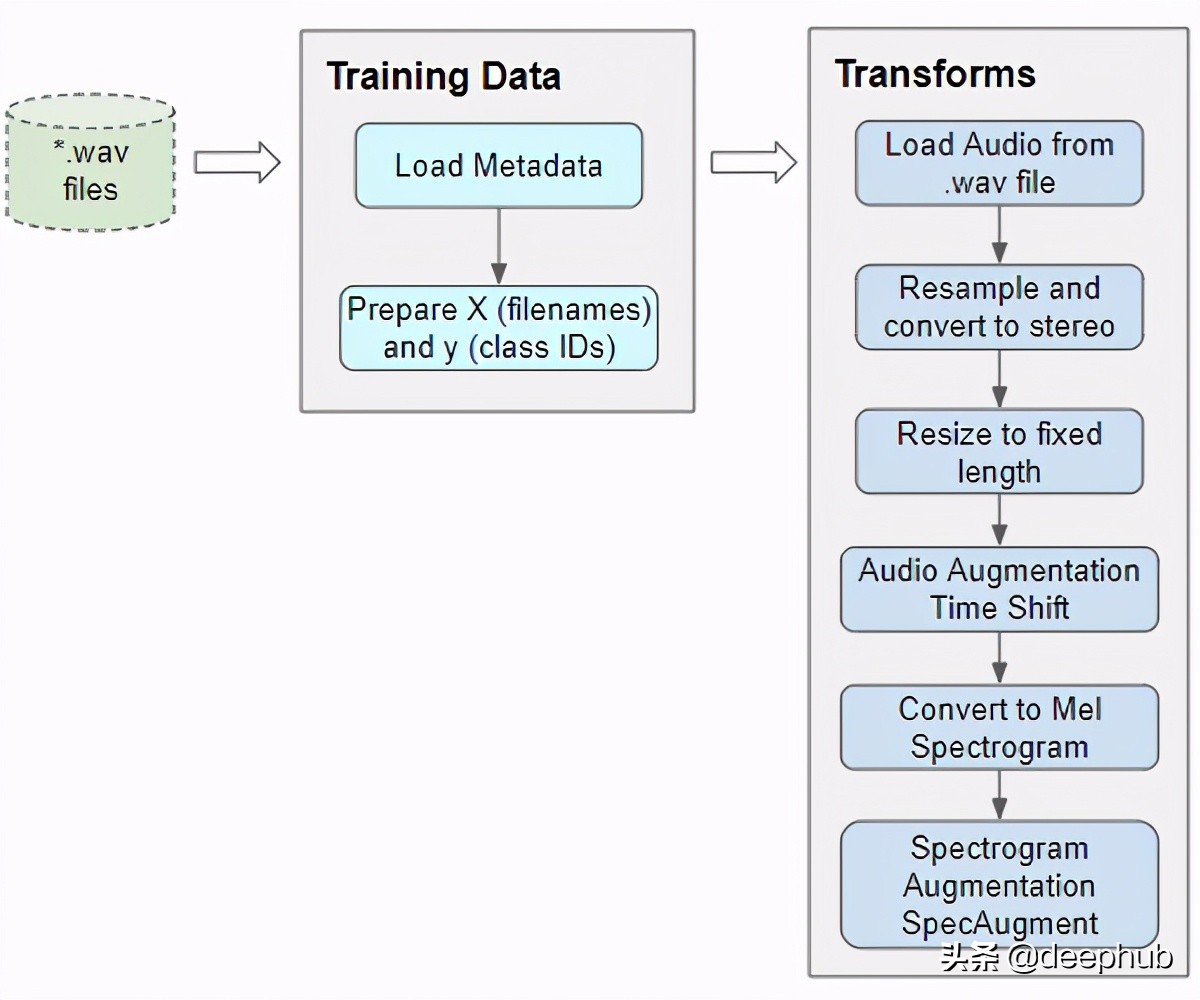
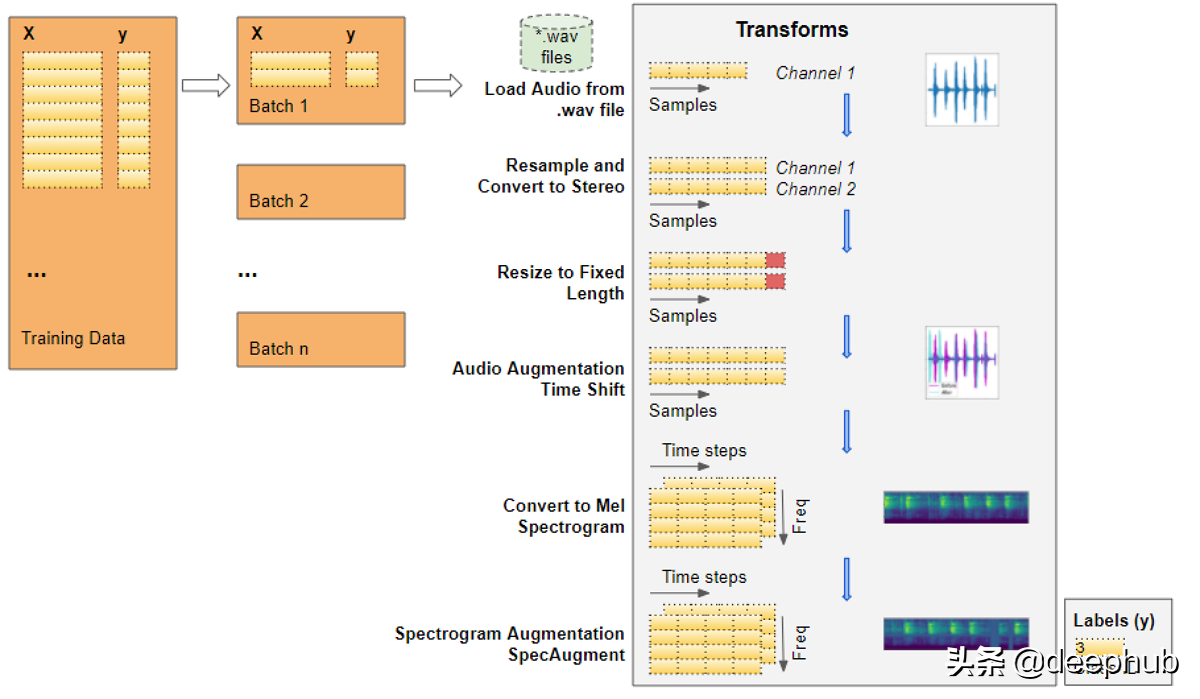
音频预处理:定义变换
这种带有音频文件路径的训练数据不能直接输入到模型中。我们必须从文件中加载音频数据并对其进行处理,使其符合模型所期望的格式。
当我们读取并加载音频文件时,所有音频预处理将在运行时动态完成。这种方法也类似于我们将要处理的图像文件。由于音频数据(或图像数据)可能非常大且占用大量内存,因此我们不希望提前一次将整个数据集全部读取到内存中。因此,我们在训练数据中仅保留音频文件名(或图像文件名)。。
然后在运行时,当我们一次训练一批数据时,我们将加载该批次的音频数据,并通过对音频进行一系列转换来对其进行处理。这样,我们一次只将一批音频数据保存在内存中。
对于图像数据,我们可能会有一个转换管道,在该转换过程中,我们首先将图像文件读取为像素并将其加载。然后,我们可以应用一些图像处理步骤来调整数据的形状和大小,将其裁剪为固定大小,然后将其从RGB转换为灰度(如果需要)。我们可能还会应用一些图像增强步骤,例如旋转,翻转等。
音频数据的处理非常相似。现在我们只定义函数,当我们在训练期间向模型提供数据时,它们将在稍后运行。
读取文件中的音频
我们需要做的第一件事是以“ .wav”格式读取和加载音频文件。 由于我们在此示例中使用的是Pytorch,因此下面的实现使用torchaudio进行音频处理,但是librosa也可以正常工作。
- import math, random
- import torch
- import torchaudio
- from torchaudio import transforms
- from IPython.display import Audio
- class AudioUtil():
- # ----------------------------
- # Load an audio file. Return the signal as a tensor and the sample rate
- # ----------------------------
- @staticmethod
- def open(audio_file):
- sig, sr = torchaudio.load(audio_file)
- return (sig, sr)
转换成立体声
一些声音文件是单声道(即1个音频通道),而大多数则是立体声(即2个音频通道)。 由于我们的模型期望所有项目都具有相同的尺寸,因此我们将第一个通道复制到第二个通道,从而将单声道文件转换为立体声。
- # ----------------------------
- # Convert the given audio to the desired number of channels
- # ----------------------------
- @staticmethod
- def rechannel(aud, new_channel):
- sig, sr = aud
- if (sig.shape[0] == new_channel):
- # Nothing to do
- return aud
- if (new_channel == 1):
- # Convert from stereo to mono by selecting only the first channel
- resig = sig[:1, :]
- else:
- # Convert from mono to stereo by duplicating the first channel
- resig = torch.cat([sig, sig])
- return ((resig, sr))
标准化采样率
一些声音文件以48000Hz的采样率采样,而大多数声音文件以44100Hz的采样率采样。 这意味着对于某些声音文件,1秒音频的数组大小为48000,而对于其他声音文件,其数组大小为44100。 ,我们必须将所有音频标准化并将其转换为相同的采样率,以使所有阵列具有相同的尺寸。
- # ----------------------------
- # Since Resample applies to a single channel, we resample one channel at a time
- # ----------------------------
- @staticmethod
- def resample(aud, newsr):
- sig, sr = aud
- if (sr == newsr):
- # Nothing to do
- return aud
- num_channels = sig.shape[0]
- # Resample first channel
- resig = torchaudio.transforms.Resample(sr, newsr)(sig[:1,:])
- if (num_channels > 1):
- # Resample the second channel and merge both channels
- retwo = torchaudio.transforms.Resample(sr, newsr)(sig[1:,:])
- resig = torch.cat([resig, retwo])
- return ((resig, newsr))
调整为相同长度
然后,我们将所有音频样本的大小调整为具有相同的长度,方法是通过使用静默填充或通过截断其长度来延长其持续时间。 我们将该方法添加到AudioUtil类中。
- # ----------------------------
- # Pad (or truncate) the signal to a fixed length 'max_ms' in milliseconds
- # ----------------------------
- @staticmethod
- def pad_trunc(aud, max_ms):
- sig, sr = aud
- num_rows, sig_len = sig.shape
- max_len = sr//1000 * max_ms
- if (sig_len > max_len):
- # Truncate the signal to the given length
- sig = sig[:,:max_len]
- elif (sig_len < max_len):
- # Length of padding to add at the beginning and end of the signal
- pad_begin_len = random.randint(0, max_len - sig_len)
- pad_end_len = max_len - sig_len - pad_begin_len
- # Pad with 0s
- pad_begin = torch.zeros((num_rows, pad_begin_len))
- pad_end = torch.zeros((num_rows, pad_end_len))
- sig = torch.cat((pad_begin, sig, pad_end), 1)
- return (sig, sr)
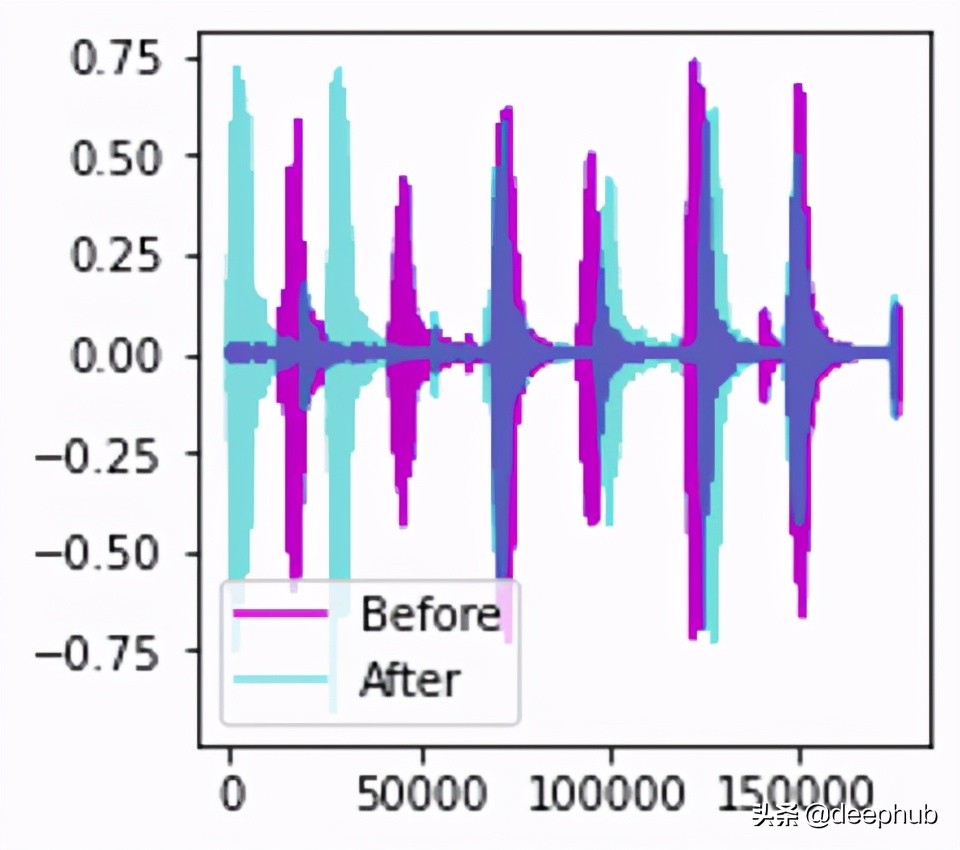
数据扩充增广:时移
接下来,我们可以通过应用时间偏移将音频向左或向右移动随机量来对原始音频信号进行数据增广。 在本文中,我将详细介绍此技术和其他数据增广技术。
- # ----------------------------
- # Shifts the signal to the left or right by some percent. Values at the end
- # are 'wrapped around' to the start of the transformed signal.
- # ----------------------------
- @staticmethod
- def time_shift(aud, shift_limit):
- sig,sr = aud
- _, sig_len = sig.shape
- shift_amt = int(random.random() * shift_limit * sig_len)
- return (sig.roll(shift_amt), sr)
梅尔谱图
我们将增广后的音频转换为梅尔频谱图。 它们捕获了音频的基本特征,并且通常是将音频数据输入到深度学习模型中的最合适方法。
- # ----------------------------
- # Generate a Spectrogram
- # ----------------------------
- @staticmethod
- def spectro_gram(aud, n_mels=64, n_fft=1024, hop_len=None):
- sig,sr = aud
- top_db = 80
- # spec has shape [channel, n_mels, time], where channel is mono, stereo etc
- spec = transforms.MelSpectrogram(sr, n_fft=n_fft, hop_length=hop_len, n_mels=n_mels)(sig)
- # Convert to decibels
- spec = transforms.AmplitudeToDB(top_db=top_db)(spec)
- return (spec)

数据扩充:时间和频率屏蔽
现在我们可以进行另一轮扩充,这次是在Mel频谱图上,而不是在原始音频上。 我们将使用一种称为SpecAugment的技术,该技术使用以下两种方法:
频率屏蔽-通过在频谱图上添加水平条来随机屏蔽一系列连续频率。
时间掩码-与频率掩码类似,不同之处在于,我们使用竖线从频谱图中随机地遮挡了时间范围。
- # ----------------------------
- # Augment the Spectrogram by masking out some sections of it in both the frequency
- # dimension (ie. horizontal bars) and the time dimension (vertical bars) to prevent
- # overfitting and to help the model generalise better. The masked sections are
- # replaced with the mean value.
- # ----------------------------
- @staticmethod
- def spectro_augment(spec, max_mask_pct=0.1, n_freq_masks=1, n_time_masks=1):
- _, n_mels, n_steps = spec.shape
- mask_value = spec.mean()
- aug_spec = spec
- freq_mask_param = max_mask_pct * n_mels
- for _ in range(n_freq_masks):
- aug_spec = transforms.FrequencyMasking(freq_mask_param)(aug_spec, mask_value)
- time_mask_param = max_mask_pct * n_steps
- for _ in range(n_time_masks):
- aug_spec = transforms.TimeMasking(time_mask_param)(aug_spec, mask_value)
- return aug_spec

自定义数据加载器
现在,我们已经定义了所有预处理转换函数,我们将定义一个自定义的Pytorch Dataset对象。
要将数据提供给使用Pytorch的模型,我们需要两个对象:
一个自定义Dataset对象,该对象使用所有音频转换来预处理音频文件并一次准备一个数据项。
内置的DataLoader对象,该对象使用Dataset对象来获取单个数据项并将其打包为一批数据。
- from torch.utils.data import DataLoader, Dataset, random_split
- import torchaudio
- # ----------------------------
- # Sound Dataset
- # ----------------------------
- class SoundDS(Dataset):
- def __init__(self, df, data_path):
- self.df = df
- self.data_path = str(data_path)
- self.duration = 4000
- self.sr = 44100
- self.channel = 2
- self.shift_pct = 0.4
- # ----------------------------
- # Number of items in dataset
- # ----------------------------
- def __len__(self):
- return len(self.df)
- # ----------------------------
- # Get i'th item in dataset
- # ----------------------------
- def __getitem__(self, idx):
- # Absolute file path of the audio file - concatenate the audio directory with
- # the relative path
- audio_file = self.data_path + self.df.loc[idx, 'relative_path']
- # Get the Class ID
- class_id = self.df.loc[idx, 'classID']
- aud = AudioUtil.open(audio_file)
- # Some sounds have a higher sample rate, or fewer channels compared to the
- # majority. So make all sounds have the same number of channels and same
- # sample rate. Unless the sample rate is the same, the pad_trunc will still
- # result in arrays of different lengths, even though the sound duration is
- # the same.
- reaud = AudioUtil.resample(aud, self.sr)
- rechan = AudioUtil.rechannel(reaud, self.channel)
- dur_aud = AudioUtil.pad_trunc(rechan, self.duration)
- shift_aud = AudioUtil.time_shift(dur_aud, self.shift_pct)
- sgram = AudioUtil.spectro_gram(shift_aud, n_mels=64, n_fft=1024, hop_len=None)
- aug_sgram = AudioUtil.spectro_augment(sgram, max_mask_pct=0.1, n_freq_masks=2, n_time_masks=2)
- return aug_sgram, class_id
使用数据加载器准备一批数据
现在已经定义了我们需要将数据输入到模型中的所有函数。
我们使用自定义数据集从Pandas中加载特征和标签,然后以80:20的比例将数据随机分为训练和验证集。 然后,我们使用它们来创建我们的训练和验证数据加载器。
- from torch.utils.data import random_split
- myds = SoundDS(df, data_path)
- # Random split of 80:20 between training and validation
- num_items = len(myds)
- num_train = round(num_items * 0.8)
- num_val = num_items - num_train
- train_ds, val_ds = random_split(myds, [num_train, num_val])
- # Create training and validation data loaders
- train_dl = torch.utils.data.DataLoader(train_ds, batch_size=16, shuffle=True)
- val_dl = torch.utils.data.DataLoader(val_ds, batch_size=16, shuffle=False)
当我们开始训练时,将随机获取一批包含音频文件名列表的输入,并在每个音频文件上运行预处理音频转换。 它还将获取一批包含类ID的相应目标Label。 因此,它将一次输出一批训练数据,这些数据可以直接作为输入提供给我们的深度学习模型。
让我们从音频文件开始,逐步完成数据转换的各个步骤:
文件中的音频被加载到Numpy的数组中(numchannels,numsamples)。大部分音频以44.1kHz采样,持续时间约为4秒,从而产生44,100 * 4 = 176,400个采样。如果音频具有1个通道,则阵列的形状将为(1、176,400)。同样,具有2个通道的4秒钟持续时间且以48kHz采样的音频将具有192,000个采样,形状为(2,192,000)。
每种音频的通道和采样率不同,因此接下来的两次转换会将音频重新采样为标准的44.1kHz和标准的2个通道。
某些音频片段可能大于或小于4秒,因此我们还将音频持续时间标准化为固定的4秒长度。现在,所有项目的数组都具有相同的形状(2,176,400)
时移数据扩充功能会随机将每个音频样本向前或向后移动。形状不变。
扩充后的音频将转换为梅尔频谱图,其形状为(numchannels,Mel freqbands,time_steps)=(2,64,344)
SpecAugment数据扩充功能将时间和频率掩码随机应用于梅尔频谱图。形状不变。
最后我们每批得到了两个张量,一个用于包含梅尔频谱图的X特征数据,另一个用于包含数字类ID的y目标标签。 从每个训练轮次的训练数据中随机选择批次。
每个批次的形状为(batchsz,numchannels,Mel freqbands,timesteps)
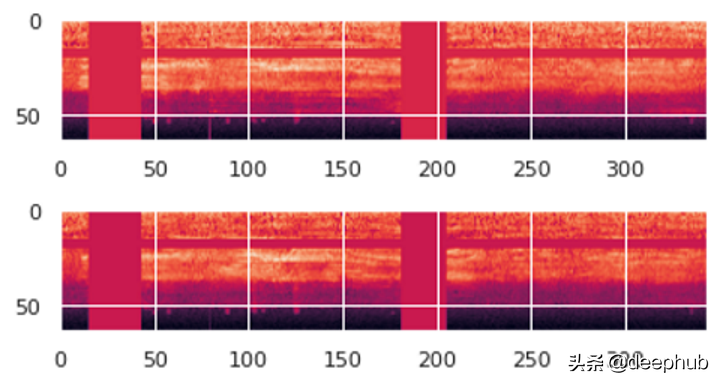
我们可以将批次中的一项可视化。 我们看到带有垂直和水平条纹的梅尔频谱图显示了频率和时间屏蔽数据的扩充。
建立模型
我们刚刚执行的数据处理步骤是我们音频分类问题中最独特的方面。 从这里开始,模型和训练过程与标准图像分类问题中常用的模型和训练过程非常相似,并且不特定于音频深度学习。
由于我们的数据现在由光谱图图像组成,因此我们建立了CNN分类架构来对其进行处理。 它具有生成特征图的四个卷积块。 然后将数据重新整形为我们需要的格式,以便可以将其输入到线性分类器层,该层最终输出针对10个分类的预测。
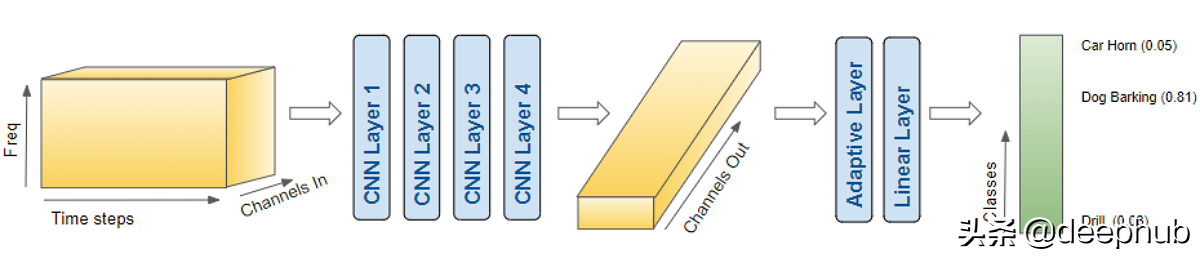
模型信息:
色彩图像以形状(batchsz,numchannels,Mel freqbands,timesteps)输入模型。(16,2,64,344)。
每个CNN层都应用其滤镜以提高图像深度,即通道数。 (16、64、4、22)。
将其合并并展平为(16,64)的形状,然后输入到“线性”层。
线性层为每个类别输出一个预测分数,即(16、10)
- import torch.nn.functional as F
- from torch.nn import init
- # ----------------------------
- # Audio Classification Model
- # ----------------------------
- class AudioClassifier (nn.Module):
- # ----------------------------
- # Build the model architecture
- # ----------------------------
- def __init__(self):
- super().__init__()
- conv_layers = []
- # First Convolution Block with Relu and Batch Norm. Use Kaiming Initialization
- self.conv1 = nn.Conv2d(2, 8, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2))
- self.relu1 = nn.ReLU()
- self.bn1 = nn.BatchNorm2d(8)
- init.kaiming_normal_(self.conv1.weight, a=0.1)
- self.conv1.bias.data.zero_()
- conv_layers += [self.conv1, self.relu1, self.bn1]
- # Second Convolution Block
- self.conv2 = nn.Conv2d(8, 16, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
- self.relu2 = nn.ReLU()
- self.bn2 = nn.BatchNorm2d(16)
- init.kaiming_normal_(self.conv2.weight, a=0.1)
- self.conv2.bias.data.zero_()
- conv_layers += [self.conv2, self.relu2, self.bn2]
- # Second Convolution Block
- self.conv3 = nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
- self.relu3 = nn.ReLU()
- self.bn3 = nn.BatchNorm2d(32)
- init.kaiming_normal_(self.conv3.weight, a=0.1)
- self.conv3.bias.data.zero_()
- conv_layers += [self.conv3, self.relu3, self.bn3]
- # Second Convolution Block
- self.conv4 = nn.Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
- self.relu4 = nn.ReLU()
- self.bn4 = nn.BatchNorm2d(64)
- init.kaiming_normal_(self.conv4.weight, a=0.1)
- self.conv4.bias.data.zero_()
- conv_layers += [self.conv4, self.relu4, self.bn4]
- # Linear Classifier
- self.ap = nn.AdaptiveAvgPool2d(output_size=1)
- self.lin = nn.Linear(in_features=64, out_features=10)
- # Wrap the Convolutional Blocks
- self.conv = nn.Sequential(*conv_layers)
- # ----------------------------
- # Forward pass computations
- # ----------------------------
- def forward(self, x):
- # Run the convolutional blocks
- x = self.conv(x)
- # Adaptive pool and flatten for input to linear layer
- x = self.ap(x)
- x = x.view(x.shape[0], -1)
- # Linear layer
- x = self.lin(x)
- # Final output
- return x
- # Create the model and put it on the GPU if available
- myModel = AudioClassifier()
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- myModel = myModel.to(device)
- # Check that it is on Cuda
- next(myModel.parameters()).device
训练
现在,我们准备创建训练循环来训练模型。
我们定义了优化器,损失函数和学习率的调度计划的函数,以便随着训练的进行而动态地改变我们的学习率,这样可以使模型收敛的更快。
在每轮训练完成后。 我们跟踪一个简单的准确性指标,该指标衡量正确预测的百分比。
# ----------------------------
# Training Loop
# ----------------------------
def training(model, train_dl, num_epochs):
# Loss Function, Optimizer and Scheduler
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.001,
steps_per_epoch=int(len(train_dl)),
epochs=num_epochs,
anneal_strategy='linear')
# Repeat for each epoch
for epoch in range(num_epochs):
running_loss = 0.0
correct_prediction = 0
total_prediction = 0
# Repeat for each batch in the training set
for i, data in enumerate(train_dl):
# Get the input features and target labels, and put them on the GPU
inputs, labels = data[0].to(device), data[1].to(device)
# Normalize the inputs
inputs_m, inputs_s = inputs.mean(), inputs.std()
inputs = (inputs - inputs_m) / inputs_s
# Zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step()
# Keep stats for Loss and Accuracy
running_loss += loss.item()
# Get the predicted class with the highest score
_, prediction = torch.max(outputs,1)
# Count of predictions that matched the target label
correct_prediction += (prediction == labels).sum().item()
total_prediction += prediction.shape[0]
#if i % 10 == 0: # print every 10 mini-batches
# print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 10))
# Print stats at the end of the epoch
num_batches = len(train_dl)
avg_loss = running_loss / num_batches
acc = correct_prediction/total_prediction
print(f'Epoch: {epoch}, Loss: {avg_loss:.2f}, Accuracy: {acc:.2f}')
print('Finished Training')
num_epochs=2 # Just for demo, adjust this higher.
training(myModel, train_dl, num_epochs)
推理
通常,作为训练循环的一部分,我们还将根据验证数据评估指标。 所以我们会对原始数据中保留测试数据集(被当作是训练时看不见的数据)进行推理。 出于本演示的目的,我们将为此目的使用验证数据。
我们禁用梯度更新并运行一个推理循环。 与模型一起执行前向传播以获取预测,但是我们不需要反向传播和优化。
- # ----------------------------
- # Inference
- # ----------------------------
- def inference (model, val_dl):
- correct_prediction = 0
- total_prediction = 0
- # Disable gradient updates
- with torch.no_grad():
- for data in val_dl:
- # Get the input features and target labels, and put them on the GPU
- inputs, labels = data[0].to(device), data[1].to(device)
- # Normalize the inputs
- inputs_m, inputs_s = inputs.mean(), inputs.std()
- inputs = (inputs - inputs_m) / inputs_s
- # Get predictions
- outputs = model(inputs)
- # Get the predicted class with the highest score
- _, prediction = torch.max(outputs,1)
- # Count of predictions that matched the target label
- correct_prediction += (prediction == labels).sum().item()
- total_prediction += prediction.shape[0]
- acc = correct_prediction/total_prediction
- print(f'Accuracy: {acc:.2f}, Total items: {total_prediction}')
- # Run inference on trained model with the validation set
- inference(myModel, val_dl)
结论
现在我们已经看到了声音分类的端到端示例,它是音频深度学习中最基础的问题之一。 这不仅可以用于广泛的应用中,而且我们在此介绍的许多概念和技术都将与更复杂的音频问题相关,例如自动语音识别,其中我们从人类语音入手,了解人们在说什么,以及将其转换为文本。