最近遇到不少同学在使用NVIDIA GPU产品和SDK学习Deep Learning,经常会看到这些词语,也很容易混淆。今天我们就来撸一撸。
在讲这些概念之前,我们先扫盲一下啥叫深度学习(Deep Learning)吧。
深度学习是机器学习的一个分支,其特点是使用几个,有时上百个功能层。深度学习已经从能够进行线性分类的感知器发展到添加多层来近似更复杂的函数。加上卷积层使得小图像的处理性能有了提升,可以识别一些手写数字。现在,随着大型图像数据集的可用性和高性能并行计算卷积网络正在大规模图像上得到应用,从而实现了以前不实用的广泛应用。

在这里,我们看到一些实际应用的深度学习是如何被使用的。
深度学习擅长的一个领域是图像分类和目标检测,可以用于机器人和自动车辆以及其他一些应用程序。对于机器人来说,目标检测是很重要的,因为它使机器人智能地使用视觉信息与环境交互。深度学习也用于人脸识别,可以通过视觉来验证个人的身份信息,常见于智能手机。但深度学习不仅仅是图像处理,还可以用来做自然语言处理,比如智能音箱和语音辅助搜索。其他应用还包括医学图像、解释地震图像判读和内容推荐系统。

很多应用可以利用云端强大的性能,但有些应用就不能,比如一些应用程序需要低延迟,如机器人或自动汽车,响应时间和可靠性是至关重要的。还有应用程序需要高带宽,比如视频分析,我们不断地流数据从几个摄像机传输给远程服务器是不实际的。还有些应用比如医疗成像,涉及到病人数据的隐私。另外对于无人飞机,也无法使用云。对于这些应用我们需要在传感器本身或者附近,就近处理,这就是为什么NVIDIA Jetson平台是一个很好的边缘计算平台。
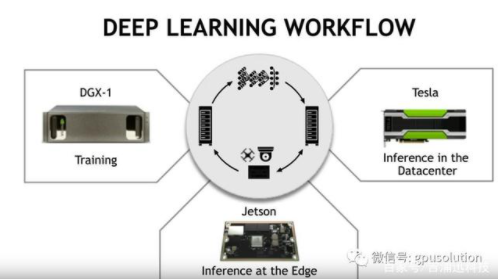
典型的Jetson平台的工作流程是在GPU服务器或者工作站上进行训练, 然后将训练的数据模型在Jetson上做边缘推理。Nvidia通过为所有主要的深度学习软件框架集成CUDA加速,使得训练模型变得容易。这些软件框架简化了开发和部署深度学习应用程序的过程。

这些框架大多有细微的差别,但每个框架通常都提供了构建神经网络的方法和训练神经网络的算法。虽然有许多不同的框架,每个框架都有自己的好处,
TF-Tensorflow
Tensorflow就是深度学习框架之一
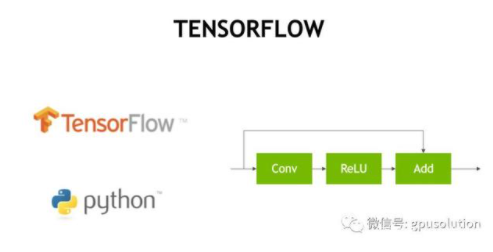
TensorFlow是种流行的深度学习框架,由谷歌公司开源。在TensorFlow里,神经网络被定义成一系列相关的操作构成的图,这些操作可能是卷积,也可能是矩阵乘法,还可能是其它的任意对每层的元素进行变换的操作。虽然在训练的过程中,网络层中的参数会发生变化,但网络结构不会。

在典型的工作流程中,开发人员通过在Python中进行tensorflow API调用来定义计算图形,Python调用创建一个图形数据结构,完全定义神经网络,然后开发人员可以使用明确定义的图形结构来编写训练或推理过程。
TLT-Transfer Learning Toolkit
除了定义新的神经网络之外,很容易重新使用已经由其他开发人员或研究人员定义和训练的现有网络,这些所谓的预训练网络可以按原样使用重新用于新任务,叫迁移学习。 在迁移学习的情况下,开发人员将从已保存的文件中加载预先训练的参数,然后使用新数据集运行训练过程,这种技术通常会导致更高的准确度,因为训练样本少于从头开始训练网络。
NVIDIA推出的NVIDIA Transfer Learning工具包(TLT)主打“无需AI框架方面的专业知识,即可为智能视频分析和计算机视觉创建准确而高效的AI模型。像零编码的专业人士一样发展。”
Transfer Learning Toolkit(TLT)是一个基于python的AI工具包,用于获取专门构建的预先训练的AI模型并使用您自己的数据进行自定义。迁移学习将学习到的特征从现有的神经网络提取到新的神经网络。当创建大型训练数据集不可行时,经常使用迁移学习。开发智能视觉AI应用程序和服务的开发人员,研究人员和软件合作伙伴可以将自己的数据用于微调经过预先训练的模型,而无需从头开始进行培训。
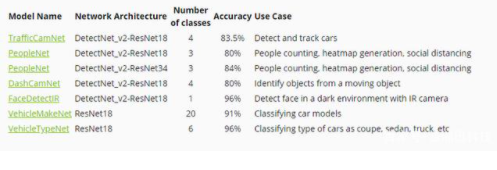
针对特定用例(例如建筑物占用分析,交通监控,停车管理,车牌识别,异常检测等),NVIDIA已经帮你准备好了预训练模型,避免开发者从头开始创建和优化模型的耗时过程,从而让你将工程工作从80周减少到大约8周,从而在较短的时间内实现更高的吞吐量和准确性。通过使用DeepStream部署视觉AI应用程序,您可以释放更大的流密度并进行大规模部署。
预先训练的模型可加速AI训练过程,并从头减少与大规模数据收集,标记和训练模型相关的成本。NVIDIA专门构建的预训练模型具有高质量的生产质量,可用于各种用例,例如人数统计,车辆检测,交通优化,停车管理,仓库运营等。
TRT-TensorRT
一旦网络完成,就可以直接部署模型。然而,如果模型使用tensorRT进行优化,那么通常会有显着的性能优势。TensorRT是由nvidia提供的,是一种优化神经网络推理的加速器。
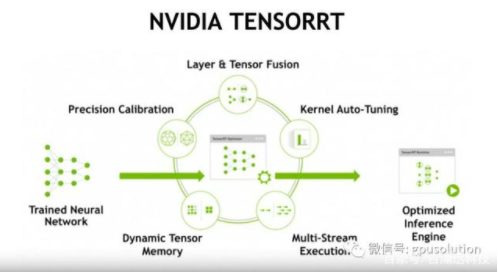
与tensorflow和其他框架不同,tensorRT不用于训练深度学习模型,而是在你完成训练时 使用tensorRT优化模型以进行部署,转换过程重新构建模型以利用高度优化的GPU操作,从而降低延迟并提高吞吐量。
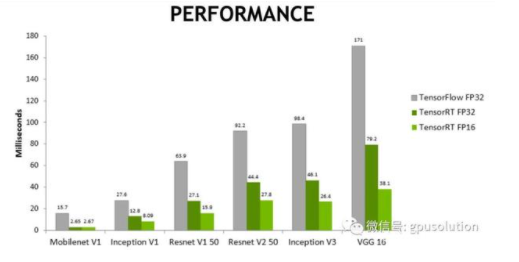
大家可以通过这个视频来了解如何用TensorRT来部署模型
DS-Deepstream
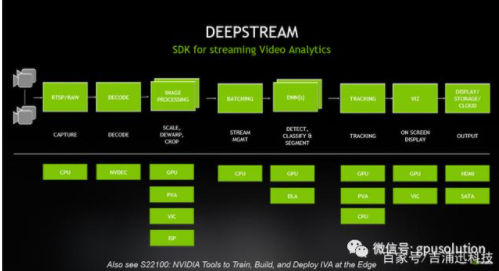
深度学习是全球视频分析应用增长的动力,开发者们越来越多的在基于计算机视觉应用中使用深度学习了。到2020年全球启用的摄像头达到10亿,这是一个难以置信的原始传感器数据量。有了这些数据,人们、社会团体和公司正在构建强大的应用,利用摄像头和streaming分析来做一些东西,比如机场的入境管理,制造中心和工厂的产线管理、停车管理,还有客流分析应用,这对构建智慧城市是很重要的。零售分析也是另外一个很重要的使用场景,对于商店来说可以帮助他们了解客户想买什么....还有其它的行业应用,这些都需要利用视频分析从而让人们具备更全面的洞察力。
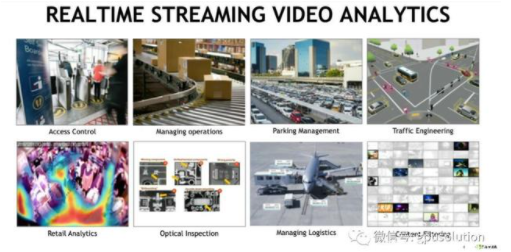
NVIDIA Deepstream SDK是一个通用的Steaming分析框架,可以让你从各个传感器中构建你自己的应用。它实际上是一个建立在GStreamer之上的SDK,GStreamer是一个开源的多媒体分析框架。NVIDIA将Deepstream作为SDK,旨在加速流视频分析所需的完整堆栈。它是一个模块化的SDK,允许开发人员为智能视频分析(IVA)构建一个高效的管道。您在这里看到的是一个典型的IVA管道,由Deepstream插件构建,它支持插件使用的底层硬件、管道的每个功能,并利用硬件体系结构移动数据,而无需任何内存拷贝。