Facebook AI推出了全新的视频理解架构TimeSformer,这也是第一个完全基于Transformer的视频架构。视频剪辑上限可达几分钟,远远超过当下最好的3D CNN,且成本更低。
TimeSformer即Time-Space Transformer,这是第一个完全基于Transformer的视频架构,近年来已经成为许多自然语言处理(NLP)应用程序的主要方法,包括机器翻译和通用语言理解。

论文链接:
https://arxiv.org/pdf/2102.05095.pdf
TimeSformer 在几个难度系数比较高的动作识别基准上获得了最好的效果,包括 Kinetics-400动作识别数据集。此外,与现代3D 卷积神经网络(CNN)相比,TimeSformer 的训练速度提高了大约3倍,推理所需计算量不到原来的十分之一。这是支持需要实时或按需处理视频的应用程序的重要一步。
此外,TimeSformer具有可伸缩性,可以用来训练更长的视频剪辑中的更大模型。这使得人工智能系统可以理解视频中更复杂的人类行为,例如涉及多个原子步骤的活动(修理汽车,准备食物等)。许多需要理解复杂人类行为的人工智能应用程序都能从中获益。
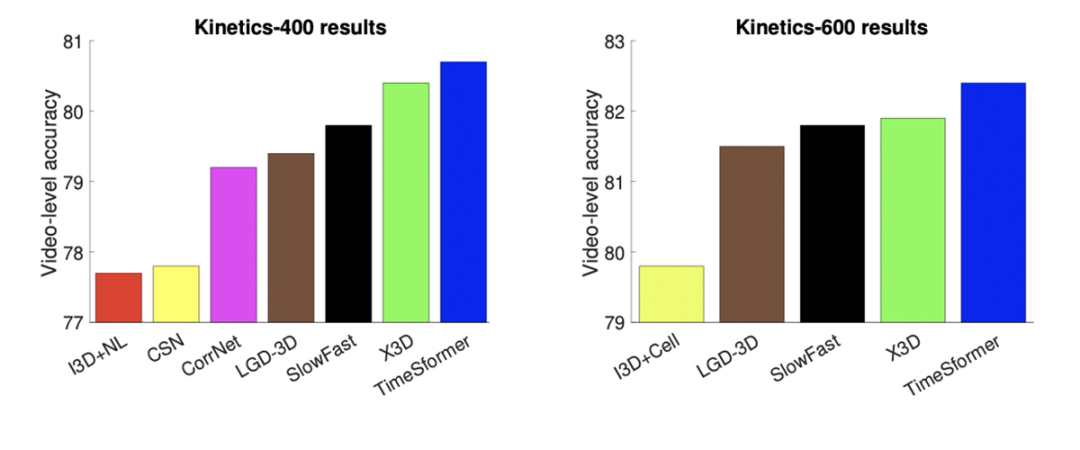
TimeSformer 与先进的3D 卷积神经网络在 Kinetics-400(左)和 Kinetics-600(右)动作识别基准上的视频分类精度。TimeSformer在两个数据集上都实现了最高的准确度。
分时空注意力
传统的视频分类模型利用3D 卷积滤波器。虽然这些滤波器在捕捉局部时空区域内的短期模式方面有效,但是它们不能对超出其接受域的时空依赖关系进行建模。
然而,TimeSformer完全建立在Transformer使用的自注意机制之上,这使得捕获整个视频的时空依赖性成为可能。
为了将Transformer应用于视频,TimeSformer将输入视频解释为从单个帧中提取的图像块的时空序列。这种格式类似于NLP中使用的格式,即Transformer将句子视为从单个单词计算出来的特征向量序列。
正如NLP Transformer通过将每个单词与句子中的所有其他单词进行比较来推断其含义一样,这一模型通过将每个patch与视频中的其他patch进行明确的比较来捕捉每个patch的语义。这使得捕获相邻patch之间的短期依赖以及远距离patch之间的长期相关成为可能。
传统的3D卷积神经网络由于需要在视频的所有时空位置上使用大量的滤波器,所以计算成本也很高。
TimeSformer 通过1)将视频分解成一小组不重叠的patch,2)应用一种自注意的形式,避免对所有patch进行详尽的比较,从而保持了较低的计算成本。我们称这种方案为「分时空注意力」。这个想法是依次应用时间注意力和空间注意力。
当应用时间注意力时,每个patch(例如,下图中蓝色正方形)仅与其他帧中同一空间位置的补丁(绿色的正方形)进行比较。如果视频包含 t 帧,则只对每个patch进行 t次时间的比较。
当应用空间注意力时,每个patch仅与同一框架内的patch(红色补丁)进行比较。因此,如果 n 是每一帧中的patch数,分时空注意力在每个patch中只能执行(t + n)次比较,而联合时空注意力穷举法则需要(t * n)次比较。此外,该研究发现分时空注意不仅比联合时空注意更有效率,而且更准确。

TimeSformer 具有可伸缩性,可以在非常长的剪辑上运行(例如,跨越102秒时间范围的96帧序列) ,以便执行超长时间范围的建模。这与目前的3D CNN有很大不同,后者仅限于处理最多几秒的片段,而且是识别长时间活动的关键要求。
例如,看一段演示如何制作法式吐司的视频。人工智能模型一次分析几秒钟可能会识别一些原子动作(例如,打鸡蛋或者把牛奶倒进碗里)。但是对每个个体行为进行分类并不足以对复杂的活动进行分类(许多食谱都涉及到打蛋)。TimeSformer 可以在更长的时间范围内分析视频,揭示原子动作之间的清晰的依赖关系(例如,将牛奶和打碎的鸡蛋混合)。
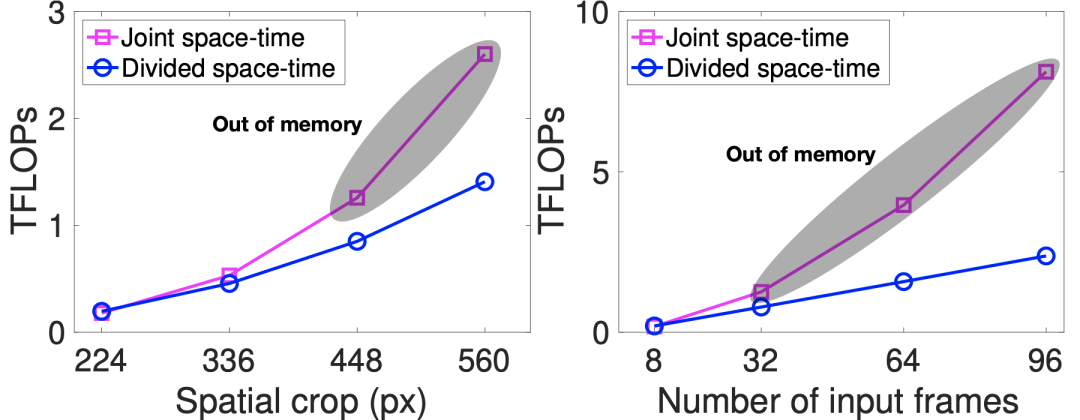
TimeSformer 的效率使得它能够训练高空间分辨率的模型(例如,帧高达560x560像素)和超长视频(高达96帧)。这些图表显示视频分类成本(TFLOPs)作为空间分辨率(左)和视频长度(右)的函数。通过这些图,我们可以观察到,分散的时空注意力比耗尽的时空联合注意力节省了大量的计算能力,特别是当应用于大帧或长视频时。在实际应用中,当空间帧分辨率达到448像素或帧数增加到32帧时,联合时空注意会导致 GPU 内存溢出,有效地使其不适用于大帧或长视频。

该图提供了 TimeSformer 学习的自注意力热度图的可视化。第一行显示原始帧,第二行根据自注意力对视频分类的重要性(被认为不重要的像素变暗)对每个像素的颜色进行加权。如图所示,TimeSformer 学习关注视频中的相关区域,以执行复杂的时空推理。
TimeSformer视频剪辑上限可达几分钟
为了训练视频理解模型,现在最好的3D CNN只能使用几秒钟长的视频片段。有了TimeSformer,我们可以训练更长的视频剪辑,最长可达几分钟。这可能极大地促进机器理解视频中复杂的长动作的研究,这对于许多理解研究人类行为的人工智能应用程序来说是重要的一步。
此外,TimeSformer的低推理成本是支持未来实时视频处理应用的一个重要步骤,如 AR/VR,或基于可穿戴摄像机拍摄的视频智能助手。TimeSformer降低了成本,这将使更多的研究人员能够解决视频分析问题,从而加快这一领域的进展。