本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
315晚会让大家意识到人脸识别有多可怕。在大洋彼岸,全球最具影响力的AI数据集也开始行动了。
近日,ImageNet数据集决定:给所有人脸打码,保护被收录者隐私。

ImageNet管理者之一Olga Russakovsky与李飞飞团队合作,一起“纠察”数据集中所有包含人脸的图像。
ImageNet总共有1000多个标签,其中只有3个标签与人相关,而很多看似与人脸无关的标签下,反而可能有大量人脸照片。
因此,研究团队通过亚马逊Rekognition的自动人脸识别以及众包方式,在150万张图片中,找出了243198张包含人脸的图片。
这些图片中的562626张人脸都已被模糊处理。
给人脸打码会影响AI模型效果吗?这恐怕是“炼丹”人士最关心的问题了。
在修改数据集之后,普林斯顿大学的博士生杨凯峪对这个问题进行了一番研究。
偏差不大,但结果微妙
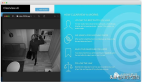
研究者使用模糊处理后的数据集进行目标检测和场景检测基准测试。
在AlexNet、VGG、ResNet等15种主流网络模型上测试后发现,Top-1准确率最多下降1%,平均仅下降0.66%,Top-5准确率平均下降0.42%。
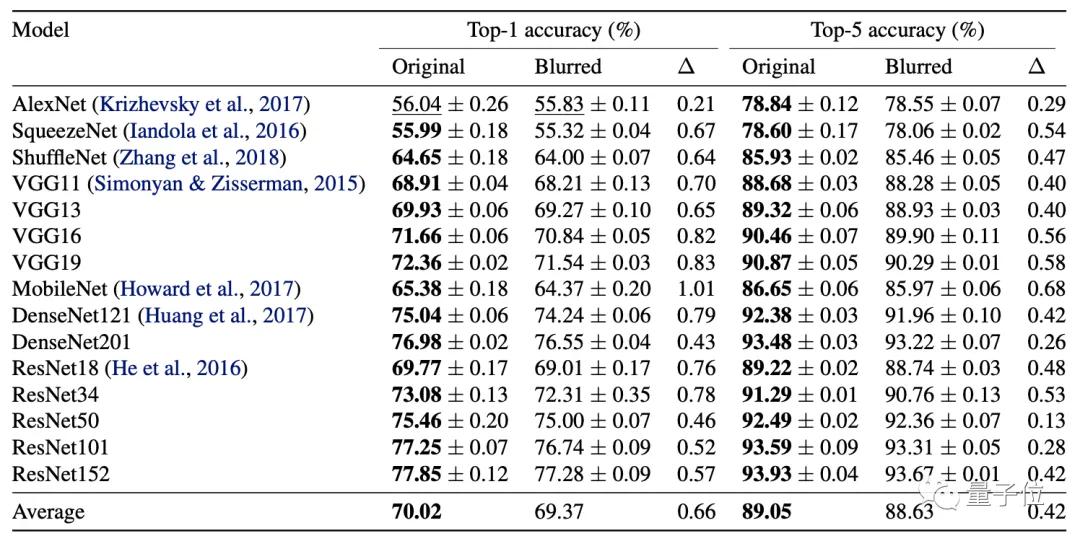
根据图片中模糊区域比例的不同,Top-1准确率下降程度随着模糊比例的增大,最高超过4%。
某些类别中离模糊人脸更近的目标,例如口琴或面具,会导致更高的分类错误率。

令人费解的是,一些没有人脸的照片反而会有很大的准确率波动,比如“哈士奇”、“爱斯基摩犬”分类。

其中,爱斯基摩犬的识别准确率出现大幅下降,而哈士奇的识别准确率反而大幅上升。

连作者也觉得很奇怪,因为这两个类别中的大多数图像都没有人脸。具体原因如何只有等待后续研究了。
MIT科学家Aleksander Madry认为,模糊人脸的数据集训练的AI有时候很奇怪,数据中的偏差非常微妙,但可能会带来严重的后果。
向隐私和偏见说不
2020年,在计算机科学道德伦理学术会议FAccT上,ImageNet数据集删除了“人”子树中2702个同义集,因为这些类别中含有令人反感、贬义或污秽的表述。例如一些种族和性别歧视的内容。
虽然ImageNet此次对隐私问题做出了重大改变,但来自UnifyID的首席科学家Vinay Prabhu指出该数据集还有许多严重问题。
去年7月,Prabhu发表的一篇论文指出,ImageNet、Tiny Images等图片数据集中不仅存在危害隐私的状况,甚至还有一些不可描述的图片。
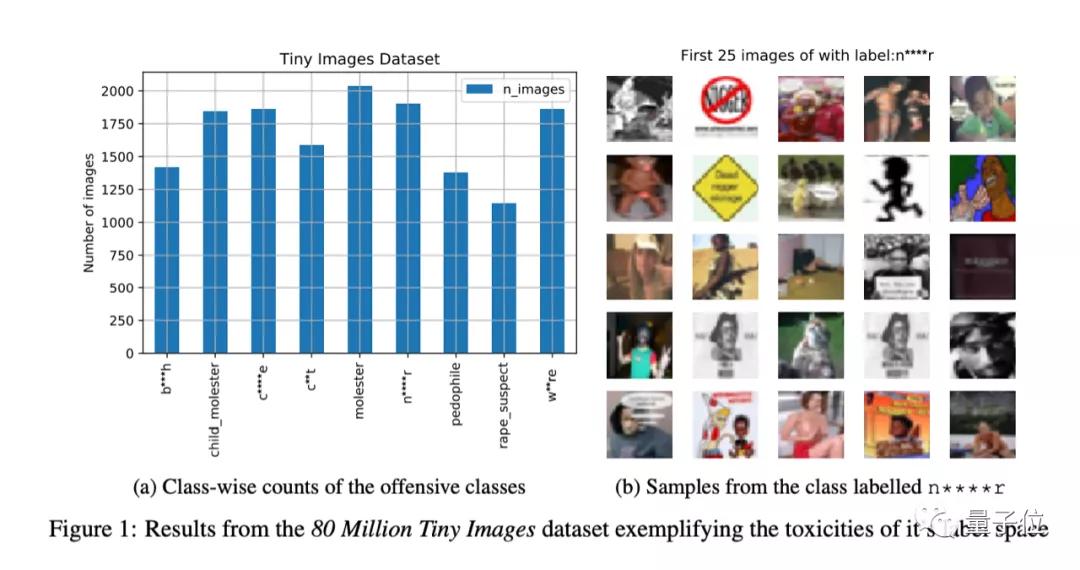
在那篇论文中,Prabhu建议,对数据集中的人脸做模糊处理,并且要做到在参与者明确同意后才能收集图片,不要为这类数据集创建数据共享许可证。
他曾给连续10个月给ImageNet团队发送邮件反馈此问题,直到去年4月才收到李飞飞的回复。
而此次ImageNet团队的论文并没有引用他,在接受《连线》杂志采访时,Prabhu表示对ImageNet团队没有承认他所做的工作感到失望。
Russakovsky回复称,论文的更新版本将会把Prabhu的研究加入引文中。
2019年,微软悄悄删除了包含1000万张图片的人脸数据集MS Celeb,这些照片都未征得本人同意。

此前用公共摄像头搜集的数据集,如杜克大学的MTMC、斯坦福大学的Brainwash,近年来都被悉数删除。
在公众隐私意识觉醒、法律逐渐完善的背景下,AI数据集到了必须要保护用户隐私的时候了。