













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
人脸识别领域,中国队再次传来捷报。
全球最大规模人脸数据集发布。
首次包含数百万ID和数亿图片。

这就是由芯翌科技与清华大学自动化系智能视觉实验室合作,所推出的 WebFace 260M,相关研究已被CVPR 2021接收。
并且,基于其所清洗的数据集 WebFace42M,在最具挑战IJBC测试集上,也已经达到了SOTA水平。
而它所带来的“全球之最”还不止于此。
以这项数据集为基础,芯翌科技在最新一期的NIST-FRVT榜单上,戴口罩人脸识别评测中斩获世界第一。
全球之最的人脸数据集,长什么样?
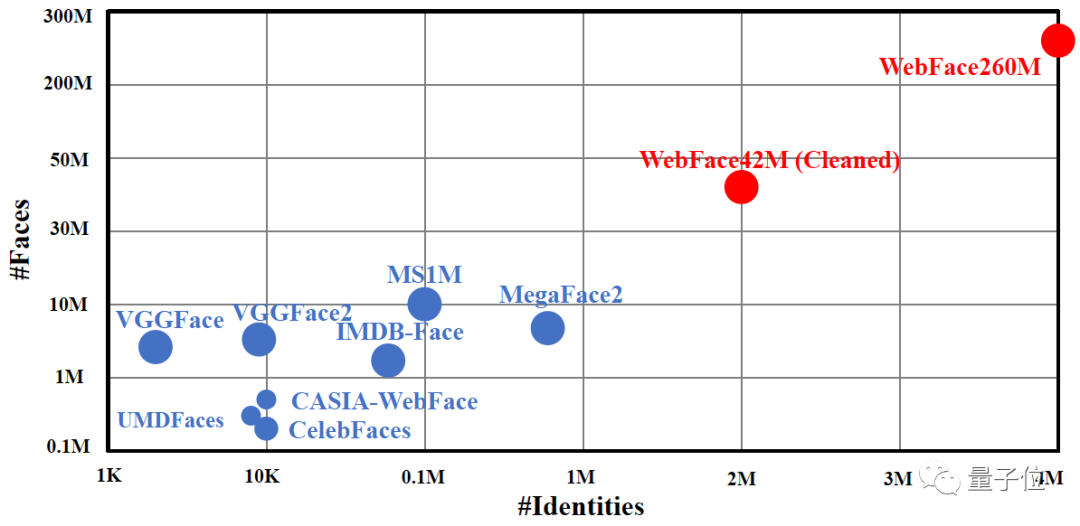
WebFace260M这个数据集,是完全基于全球互联网公开人脸数据。
它的问世,一举打破了此前人脸数据集的规模:
不仅规模最大,也是首次在人脸ID数目和图片数,分别达到了400万和2.6亿的规模。
此外,研究人员还提出了基于自训练全自动迭代的清洗流程 (Cleaning Automatically by Self-Training, CAST)。这种方法的灵感来自于对互联网人脸数据的观察和分析。
WebFace260M数据提供了粗糙的分类,可以基于此作为清洗算法的初始结构。另外,研究人员发现,在大规模含噪声人脸数据清洗中,嵌入特征显得十分重要,而这个特征可以通过同时迭代数据和模型得到增强。因此,整个清洗流程如下图所示:
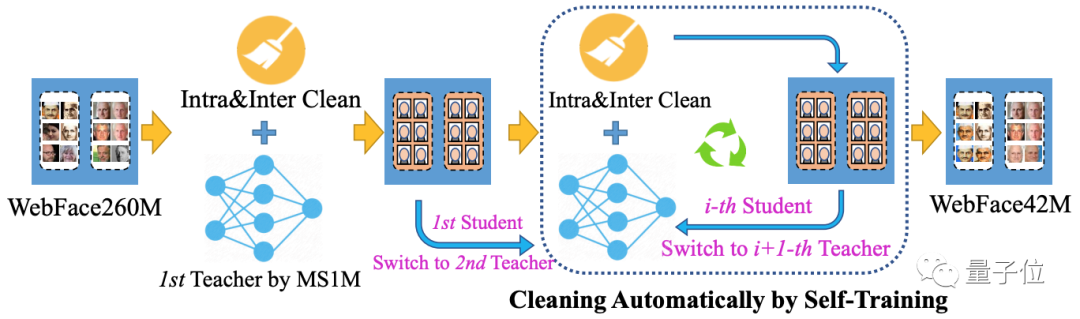
- 首先,利用名为MS1M的公开数据集训练一个“教师模型”,并对原始WebFace260M进行清洗。
- 其次,利用一个“学生模型”,在上一步清洗过的图像上进行训练。
- 最后,让“学生模型”切换为“教师模型”,并进行迭代,直到获得高质量的WebFace42M。
通过这种方式,在对WebFace260M进行清洗操作后,便得到了WebFace42M。
据介绍,它是目前全球规模最大、可直接用于训练的干净人脸数据集:
包含200万ID、4200万图片。
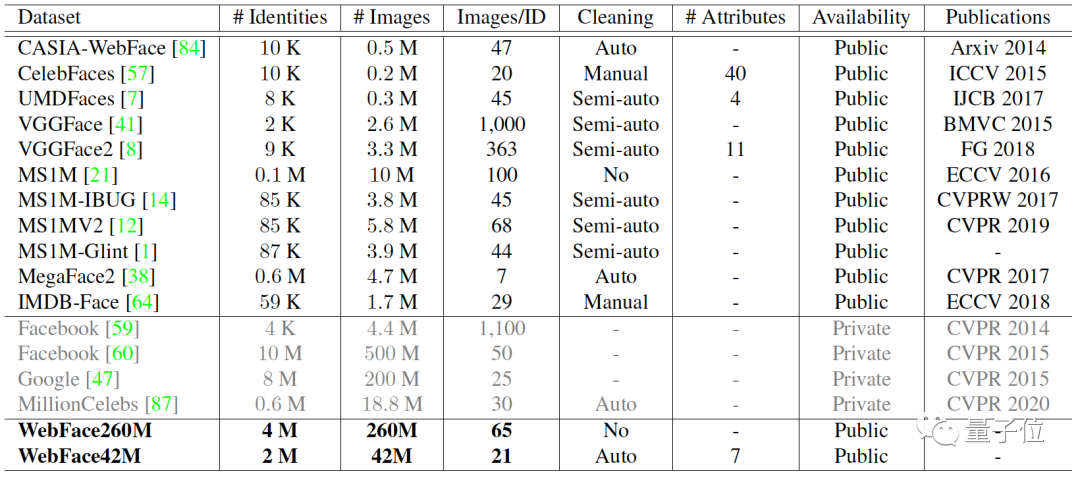
关于WebFace260M和WebFace42M的“世界之最”,一张表格的数据对比,便可一目了然:
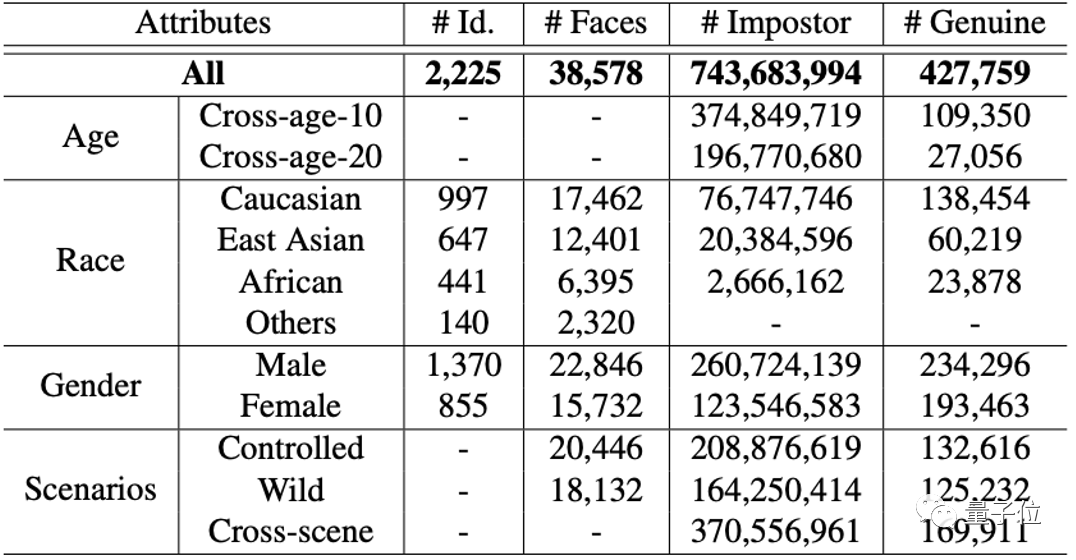
同时,针对目前人脸识别的评测问题,研究人员发布了更贴近实际应用的“时间受限人脸识别评测准则”-FRUITS (Face Recognition Under Inference Time conStraint),和分布更广泛、更具挑战性、分类更细致的人脸测试集,这将推动人脸识别评测更靠近真实场景。
同时,研究人员将持续维护、迭代和升级该测试集以及评测系统,持续助力行业技术发展。
这样的数据集,好用吗?
对于这个问题,答案是肯定,而且是得到了非常专业的实践和认可的那种。
以WebFace42M为例,它能够在目前公开的、最具挑战性的IJBC测试集上,达到新的SOTA,相对错误率还降低了40%。
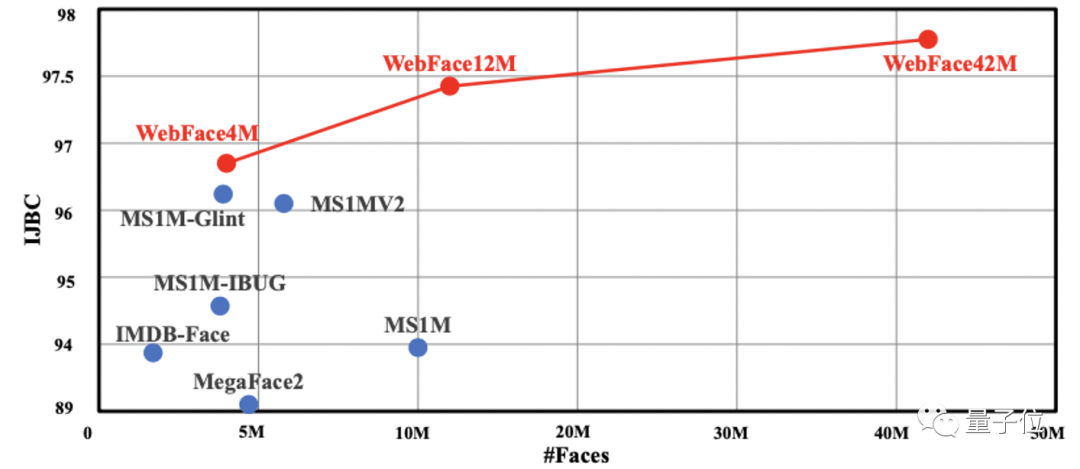
除此之外,有一个叫做NIST-FRVT的比赛,是由美国国家标准与技术研究院主办,素来有着“人脸识别黄金赛事”的别称。
因为它具有测评集非对外公开、提交频率严格限制、计算时间严格限制等诸多严苛要求,所以可以称得上是全球标准最严、最具权威的人脸识别算法评测。
那么当WebFace42M的数据,遇到如此棘手的赛事,又会擦出怎样的火花呢?
早在去年10月份,仅用WebFace42M的数据,芯翌科技便在NIST-FRVT的榜单上取得了前三名的成绩。
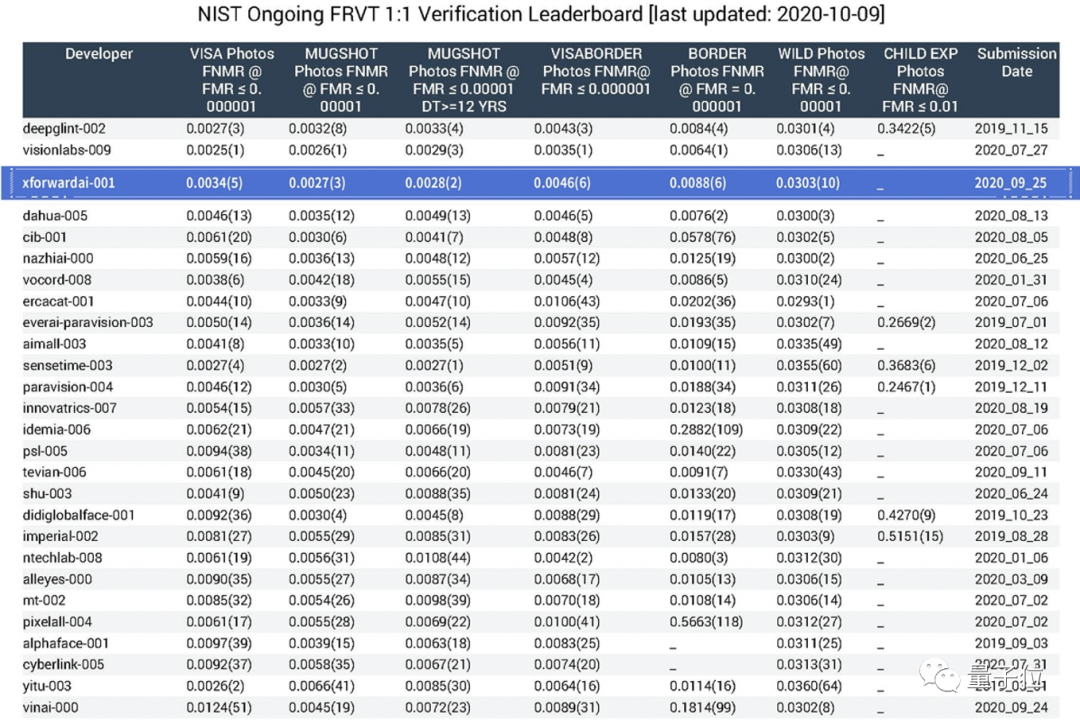
而在刚刚最新一期的NIST-FRVT榜单上,以WebFace42M为基础,在“戴口罩人脸识别评测”中又一次创造了“世界之最”——夺得比赛冠军。
而且从数据中不难看出,与第二名的成绩可以说是两个量级。
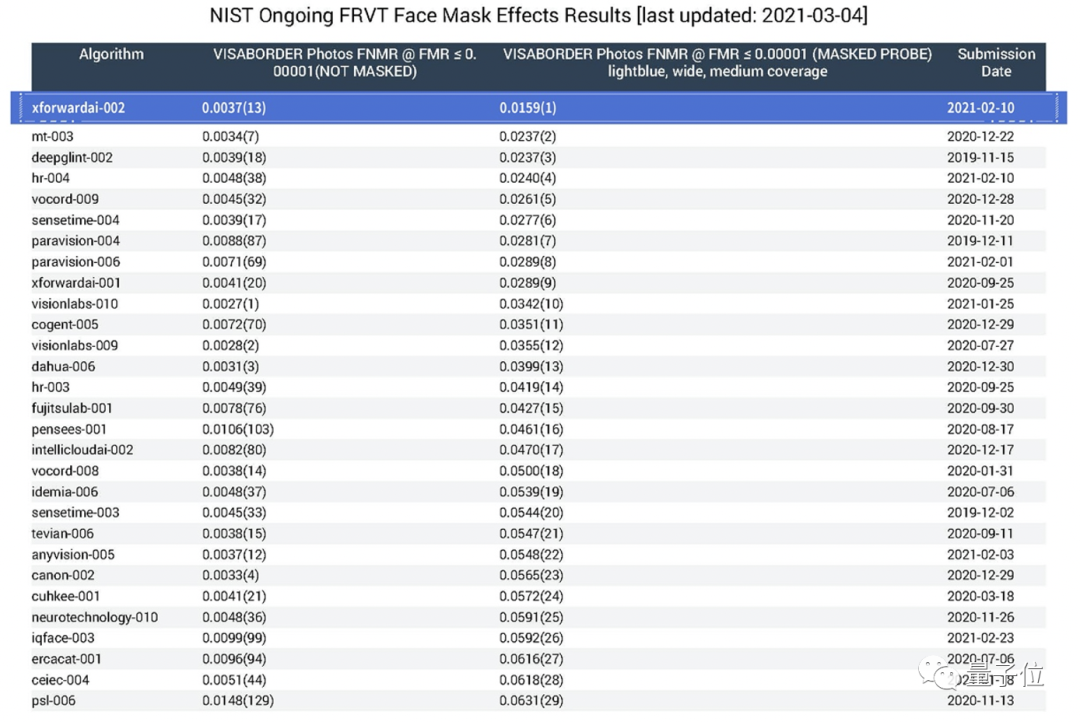
除此之外,在1:1人脸识别评测中,也取得了综合排名世界前三的成绩。
为什么要做这样的数据集?
人脸识别,这项技术可以说是真的火。
火到已经步入人们日常生活,打卡、开门禁、解锁手机等等,都成了它大展拳脚的地方。
也正因如此,学术、工业界的科研工作者,在人脸识别的精度和速度上,形成了竞相追逐的状态。
而据研究表明,人脸数据集对于上述的影响是最大的。特别是在目前以深度学习为核心的人工智能研发模式下,软件开发会逐渐从传统的软件1.0,过渡到以数据为核心的“数据即代码,模型即软件”的软件2.0时代。
然而在数据集这块,目前的现状却是:
公开数据规模和实际人脸识别系统所需数据规模,差距过大。
怎么说?
例如在WebFace260M发布之前,公开的数据规模都是较小,此前规模最大的就是MegaFace2和MS1M。
MegaFace2拥有67.2万ID和470万图片,MS1M拥有10万 ID和1000万图片。
如此规模的公开数据,对于科研人员来说,是远远无法满足实际人脸识别系统的数据需求。
同时这也只是限制人脸识别技术发展的瓶颈之一,评测准则和测试集也是重要因素。
目前公开的人脸识别评测集,包括LFW、CFP、AgeDB、RFW、MegaFace、IJB系列等,在精度上基本已经比较饱和。
同时,还存在不同场景下表现不够细致的情况。
因此,WebFace260M和WebFace42M以及相关Benchmark的推出,在一定程度上可以说是拉近了公开数据集规模与实际应用产业界的这条鸿沟,进一步推动以深度学习为核心的人脸识别相关技术的进步,促进智能化行业的繁荣发展。
而比起规模的上突破,更大的意义应该在于“科技向善”、“数据生态”。
经过过去几年的发展,人脸识别以及人工智能技术取得了巨大的进步,也产生了显著的社会经济价值,但是也出现了很多由于技术发展带来的社会问题。
团队希望通过这个数据集的建立和相关工作,和产业界以及社会各界一起,构建人脸识别测试和应用标准,规范人脸识别应用市场,治理人脸识别应用乱象,科技向善,凸显人工智能技术的价值和温度。
更进一步来讲,在现今数字经济和智能化高速发展的当下,数字资源已然成为像水、电一样的必需品;同时又像石油一般的宝贵,需要有规划地去生产、使用、分享和交易等。
但现在目前的状况是,国内外普遍对此的重视程度不够,具体而言包括行业规范不标准、分享程度不足,也没有长期的规划,由此便反过来抑制了数字经济和智能化的发展进程。
目前国家层面非常鼓励和重视数据集的创新和规范,清华大学和芯翌科技的研究人员也积极响应国家的号召和政策的要求,希望和国家、政府机构、学术界以及产业界一起,打造智能化时代开放、共享、安全的数据生态。
网站地址:
https://www.face-benchmark.org
论文地址:
https://arxiv.org/abs/2103.04098

















