












港中文 MMLab 团队的这项研究证实了二维 GAN 可以隐式地学得物体的三维结构。研究者提出的方法可以看作一种新的三维形状生成方法。他们提出了一种新的无监督三维重建方法「Shape-from-GAN」,不依赖传统方法的对称性假设,并首次在开放式的建筑等数据集上实现三维重建。该研究已被接收为 ICLR 2021 Oral 论文。
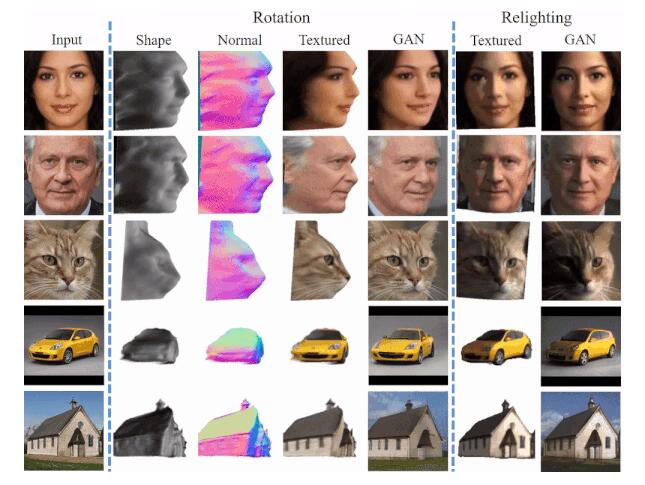
如今,StyleGAN 等对抗生成网络已经能够对多种物体生成逼真的二维图片。然而或许你不知道,这些 GAN 其实知道所生成物体的三维形状。对二维 GAN 生成的图像,我们已经可以准确重建其三维结构,并实现旋转和重光照等图像编辑效果,如下图所示:
这就是来自香港中文大学、南洋理工大学和香港大学的研究者提出的用二维 GAN 实现无监督三维重建的方法 GAN2Shape。这种「Shape-from-GAN」的范式不需要依赖传统方法的对称性假设,适用于多种物体类别,并超越以往方法达到了 SOTA。目前,该论文已被 ICLR 2021 接收为 Oral 论文。论文代码也已经开源。

论文链接:
https://openreview.net/pdf?id=FGqiDsBUKL0
项目链接:
https://github.com/XingangPan/GAN2Shape
研究动机
近年来,生成对抗网络(GAN)在图像生成任务上取得了巨大的成功。而当我们热衷于用它创造二维图像世界时,一个事实是这些二维图片其实是三维物体在二维图像平面的投影。
例如,下图展示了 StyleGAN[1] 可以实现人脸的视角变化(在有人脸视角标注的监督下)。因此,当我们在 GAN 的图像空间穿梭时,理想情况下这些图像应当符合物体本身的三维结构。

StyleGAN 可以实现人脸的视角变化
因此,一个有趣的问题是,我们能否通过挖掘二维 GAN 中的几何信息(视角与光照)来重建物体的三维形状?
方法:挖掘并利用 GAN 图像空间中的视角与光照信息
挖掘 GAN 中的几何信息并非易事,已有的方法难以对任意物体类别的 GAN 找到视角与光照变量在隐空间中对应的准确方向。为了解决此问题,研究者注意到大多数物体(如人脸、汽车等)具有较「凸」的三维形状。
因此,他们用椭球作为物体的形状先验。虽然此先验较弱,却能一定程度上反映出物体的视角与光照变化,从而可以用来引导在 GAN 图像空间中探索不同的视角与光照。
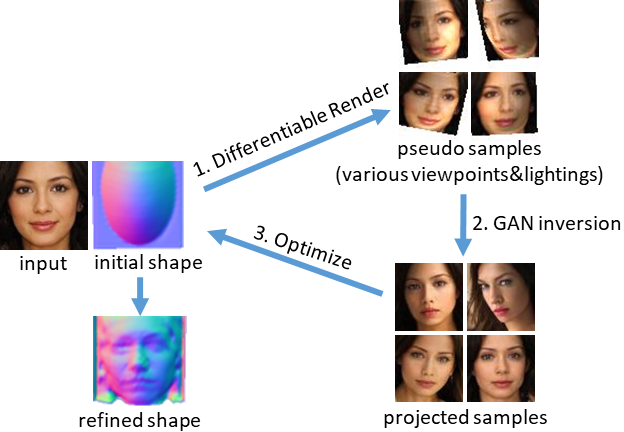
GAN2Shape 方法总览
基于这种思想,研究者设计了一种迭代式挖掘并利用 GAN 图像空间中视角与光照信息的策略,具体步骤如下:
第一步,用初始化的形状(即椭球)和可微渲染器渲染很多不同视角与光照条件下的「伪样本」(pseudo samples);
第二步,用预训练的 GAN 对伪样本进行重建,得到其在 GAN 图像空间的投影,即「投影样本」(projected samples)。这些投影样本会继承与伪样本类似的视角与光照,同时 GAN 的生成特性会将投影样本约束在真实图像空间中,从而消除伪样本中不真实的畸变与光影;
第三步,将投影样本作为可微渲染步骤的 ground truth,从而优化物体三维形状。由于投影样本中包含了 GAN 学得的物体三维信息,因此物体形状会更加准确,如上图中的人脸。
以上步骤结束后,我们可以用优化后的形状作为初始形状再重复以上步骤,迭代多次,从而逐步改善形状直至收敛。
值得一提的是,在上述第二步用 GAN 重建伪样本时,为了保证重建结果的真实性,研究者提出了一种用 StyleGAN2 的部分 mapping 网络对隐向量进行约束的方法,更多细节可参阅论文原文。
实验:二维 GAN 图像皆可三维化
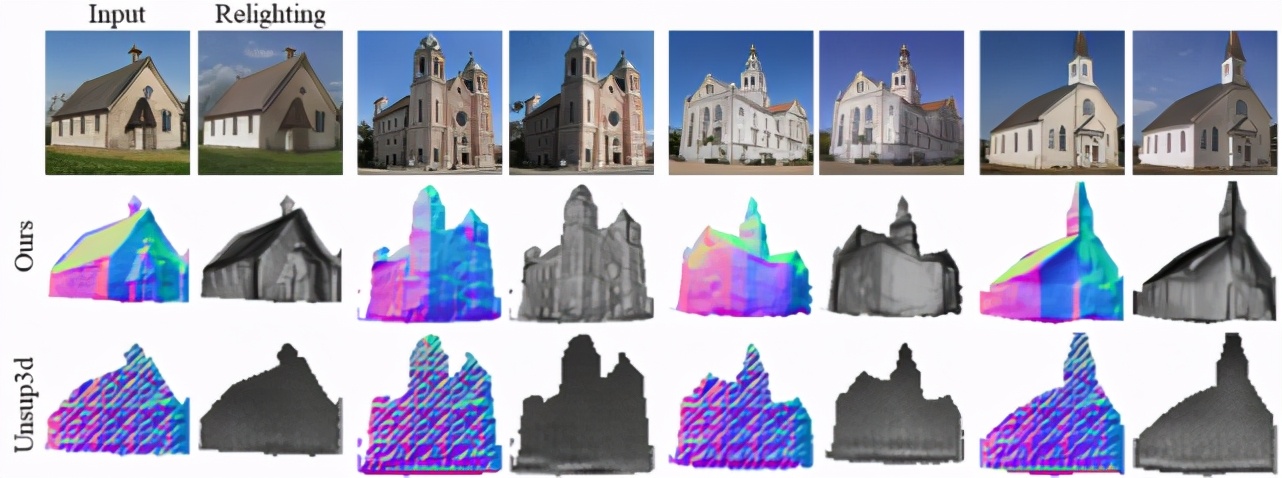
研究者将 GAN2Shape 分别应用于在人脸、猫脸、车以及建筑上训练的 StyleGAN2 [1],结果均可重建出合理的三维形状,如下图所示:

下图为 GAN2Shape 在建筑上的三维重建和重光照结果,以及与 Unsup3d [2] 的对比:
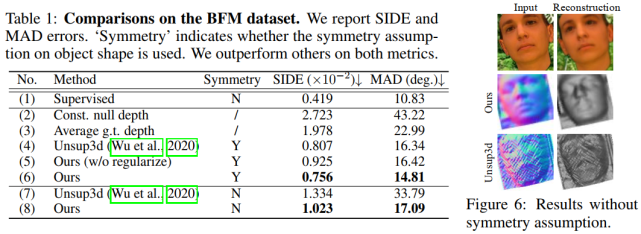
此外,该研究的定量结果同样显著超越了其它方法,并且在不使用传统方法人脸对称性假设的情况下仍然得到合理的三维重建结果。
由于该方法得到了物体三维形状和视角光照变化在 GAN 隐空间中的方向,因此可以对图像进行三维编辑,如下图所示:

三维图像编辑结果,包括物体旋转与重光照。
相较其他无监督用 GAN 实现人脸旋转的方法,研究者的方法更好地保存了人脸的 identity:

无监督人脸旋转方法对比。
更多三维重建与编辑结果如下图所示:























