一、前言
大家好,我是崔艳飞。工作中有时需要把A表中的经纬度点,从B表中匹配一个最近的点出来,用Mapinfo也可以实现,但处理速度慢,特别是数据量大时根本处理不动,此时用Python就能轻松实现,还能显示处理进度,详细如下。
二、项目目标
用Python实现两张表间最近点的计算。
三、项目准备
软件:PyCharm
需要的库:pandas, xlrd,os
四、项目分析
1)如何选择并读取要处理的Excel文件?
利用os、xlrd,选择要读取处理的Excel文件。
2)如何计算两个经纬度点的距离?
利用pandas库读取两张表的内容,再定义函数计算两个经纬度点的距离。
3)如何循环计算并保存最近一个点的数据?
利用For循环,对两张表的内容进行循环读取,通过If判断保留最近的距离点数据。
4)如何保存结果?
利用to_excel保存,得到最近点的数据。
五、项目实现
1、第一步导入需要的库
- import pandas as pd
- import xlrd
- import os
2、第二步选择并读取要处理的Excel文件
- path="D:/a/"
- #获取文件夹下所有EXCEL名
- bb = path + 'result.xlsx'
- writer = pd.ExcelWriter(bb,engine='openpyxl')
- xlsx_names = [x for x in os.listdir(path) if x.endswith(".xlsx")]
- # 获取第一个EXCEL名
- xlsx_names1 = xlsx_names[0]
- aa = path + xlsx_names1
- #打开第一个EXCEL
- first_file_fh=xlrd.open_workbook(aa)
- # 获取SHEET名
- first_file_sheet=first_file_fh.sheets()
3、第三步循环计算并保存最近一个点的数据
- for i in range(h1):
- w1=df1.loc[i,'纬度']
- j1 = df1.loc[i,'经度']
- d1 = df1.loc[i, :]
- d0=10000000000000000000000000.0000
- print("原小区第%d个。" %(i+1))
- test_dict = {'距离': [d0]}
- d3 = pd.DataFrame(test_dict)
- for l in range(h2):
- w2=df2.loc[l, '纬度']
- j2=df2.loc[l,'经度']
- d=haversine(j1, w1, j2, w2)
- if d<d0:
- d0=d
- d2 = df2.loc[l, :]
- test_dict = {'距离': [d0]}
- d3 = pd.DataFrame(test_dict)
- else:continue
4、第四步保存计算后的文件
- resultdata1.to_excel(excel_writer=writer, sheet_name='原小区', encoding="utf-8", index=False)
- resultdata2.to_excel(excel_writer=writer, sheet_name='最近小区', encoding="utf-8", index=False)
- resultdata3.to_excel(excel_writer=writer, sheet_name='距离', encoding="utf-8", index=False)
- writer.save()
- writer.close()
六、效果展示
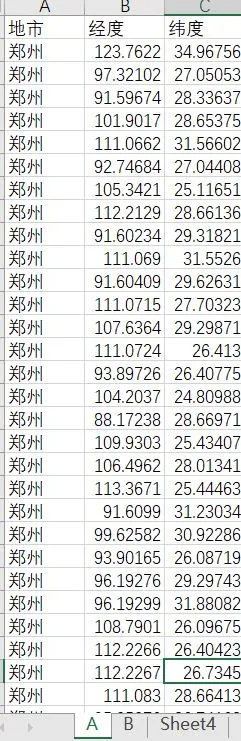
1、处理前数据:
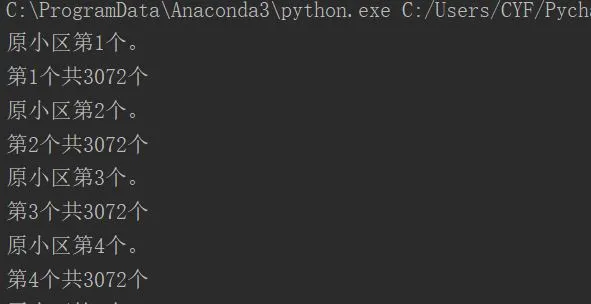
2、处理进度显示:
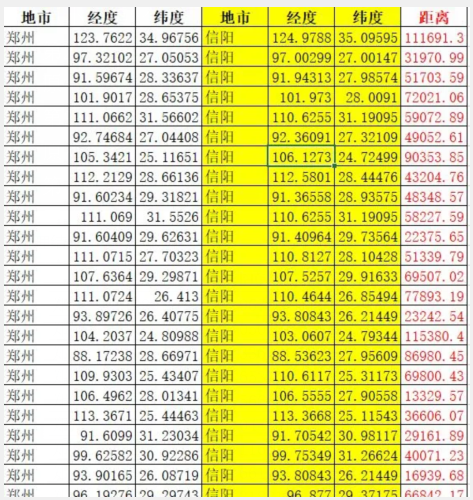
3、处理结果:
七、总结
本文介绍了如何利用Python计算两个经纬度点间的距离,并在两张表间进行最近点计算,这本来是Mapinfo的分内之事,但数据量大时就处理不动了,Python处理速度快,还能对数据进行预处理,正是由于可以自己优化代码,可以无限提高运行速度,比如数据切块处理,有兴趣的同学可以进一步研究下。