【51CTO.com快译】我之前解释了如何借助谷歌语音识别API,使用Speech Recognition库将语音转换成文本。本文介绍如何使用Facebook Wav2Vec 2.0模型将语音转换成文本。
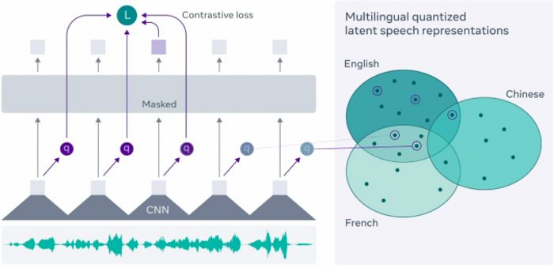
Facebook最近引入并开源了新框架:Wav2Vec 2.0,该框架用于自我监督学习来自原始音频数据的表示形式。Facebook研究人员声称,该框架使用仅10分钟长的转录语音数据,即可支持自动语音识别模型。
众所周知,Transformer在自然语言处理中扮演着重要角色。Hugging Face Transformer的最新版本是4.30,它随带Wav2Vec 2.0。这是Transformer包含的第一个自动语音识别语音模型。
模型架构不在本文的讨论范围之内。有关Wav2Vec模型架构的详细信息,请参阅此处。
不妨看看如何使用Hugging Face Transformer将音频文件转换成文本,附有几行简单的代码。
安装Transformer库
- # Installing Transformer
- !pip install -q transformers
导入必要的库
- # Import necessary library
- # For managing audio file
- import librosa
- #Importing Pytorch
- import torch
- #Importing Wav2Vec
- from transformers import Wav2Vec2ForCTC, Wav2Vec2Tokenizer
Wav2Vec2是一种语音模型,接受与语音信号的原始波形相对应的浮点数组。 Wav2Vec2模型使用连接时序分类(CTC)加以训练,因此须使用Wav2Vec2Tokenizer对模型输出进行解码(参阅:https://huggingface.co/transformers/model_doc/wav2vec2.html)。
读取音频文件
在这个例子中,我使用了电影《飓风营救》中主人公的对话音频片段“我会寻找你,我会找到你,我会杀了你”。
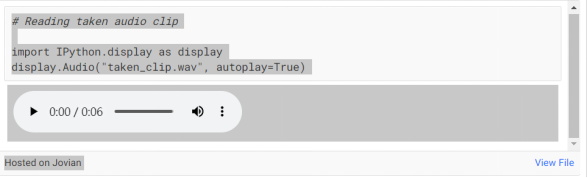
请注意,Wav2Vec模型已在16 kHz频率上进行了预训练,因此我们确保将原始音频文件也重新采样为16 kHz采样率。我使用在线音频工具转换将《飓风营救》的音频片段重新采样为16kHz。
使用librosa库加载音频文件,并提到我的音频片段大小为16000 Hz。它将音频片段转换成数组,并存储在“audio”变量中。
- # Loading the audio file
- audio, rate = librosa.load("taken_clip.wav", sr = 16000)
- # printing audio
- print(audio)
- array([0., 0., 0., ..., 0., 0., 0.], dtype=float32)
- # printing rate
- print(rate)
- 16000
导入预训练的Wav2Vec模型
- # Importing Wav2Vec pretrained model
- tokenizer = Wav2Vec2Tokenizer.from_pretrained("facebook/wav2vec2-base-960h")
- model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
下一步是获取输入值,将音频(数组)传递到分词器(tokenizer),我们希望tensor是采用PyTorch格式,而不是Python整数格式。return_tensors =“pt”,这就是PyTorch格式。
- # Taking an input value
- input_values = tokenizer(audio, return_tensors = "pt").input_values
获取logit值(非规范化值)
- # Storing logits (non-normalized prediction values)
- logits = model(input_values).logits
将logit值传递给softmax以获取预测值。
- # Storing predicted ids
- prediction = torch.argmax(logits, dim = -1)
将音频转换成文本
最后一步是将预测传递给分词器解码以获得转录。
- # Passing the prediction to the tokenzer decode to get the transcription
- transcription = tokenizer.batch_decode(prediction)[0]
- # Printing the transcription
- print(transcription)
- 'I WILL LOOK FOR YOU I WILL FIND YOU AND I WILL KILL YOU'
它与我们的音频片段完全匹配。
我们在本文中看到了如何使用Wav2Vec预训练模型和Transformers将语音转换成文本。这对于NLP项目特别是处理音频转录数据非常有帮助。
您可以在我的GitHub代码库中找到整段代码和数据。
原文标题:Speech to Text with Wav2Vec 2.0,作者:Dhilip Subramanian
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】