本文转载自微信公众号「KK架构师」,作者wangkai。转载本文请联系KK架构师公众号。
一、阅读 HDFS 源码的缘由
HDFS 是大数据的最基础的设施了,几乎所有的离线存储都在 HDFS 上。
但是在大规模 HDFS 集群中,下面的问题通常会让我们无比头疼:
- 元数据的量级超过亿级之后,NameNode 的内存也会变得非常巨大,启动和维护都变的异常困难;
- 如何保障 HDFS 的高可用?
- NameNode 里面发生长时间的 GC 之后,导致 NameNode 进程退出,该如何解决?
- 如何优化 DataNode 的锁粒度,让其性能更高效?
以上种种问题,都需要我们阅读源码,甚至要修改它的源码才能解决。
所以虽然阅读源码非常痛苦,但是这个坎还是得过的。
二、如何阅读 Hadoop 这样的百万行代码的开源项目
首先 hadoop 是用 java 写的,所以一些 java 基础知识必不可少,比如锁,线程,设计模式,java 虚拟机,java io,不求很深入,基础得知道。
其次,不能一行行的读代码,这样很容易迷失在无边际的代码中,逃不出来,最后很容易就放弃了。
最后,以具体场景来驱动代码阅读。比如本文就是以 NameNode 的启动过程,来驱动代码阅读的。并且把关键的流程节点和类用流程图记录下来。
三、源码走读
找到 NameNode 类
从 main 方法开始,创建 NameNode
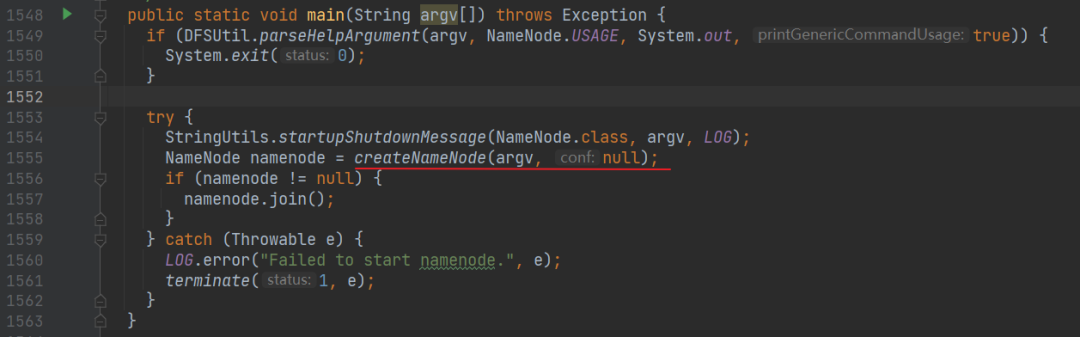
进入这个方法:

有很多的 switch case ,由于我们启动命令是 hadoop-daemon.sh start namenode,所以直接运行到 default 里面:
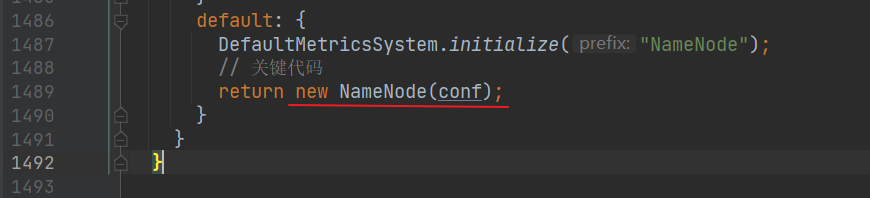
这是个比较重要的方法,实例化:
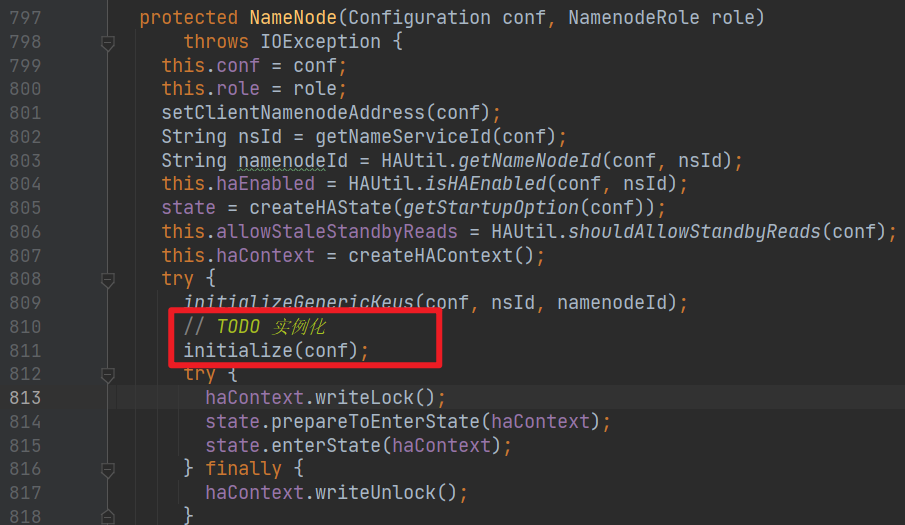
实例化方法里,有个比较重要的操作,startHttpServer(conf),启动 50070 端口,就是我们 50070 那个界面:
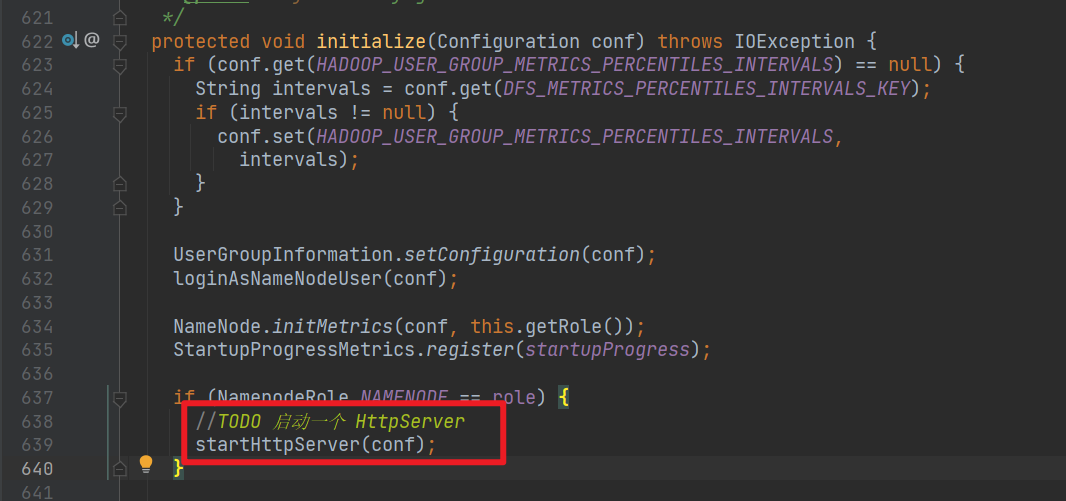
进去,使用 ip 和 端口创建了 HttpServer

再来看这个 start 方法

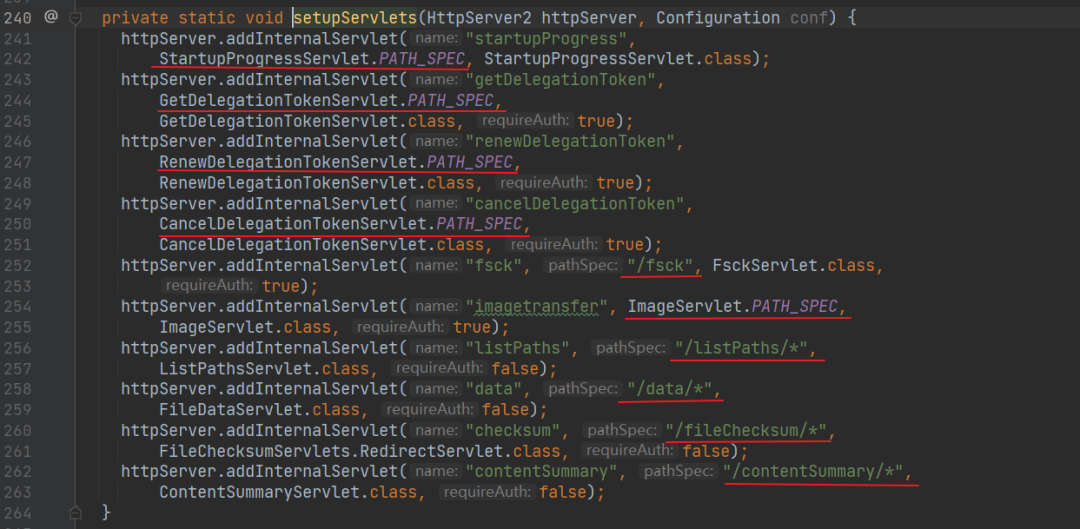
进入 start 方法,发现创建了一个 HttpServer2,这是 Hadoop 自己封装的服务

然后绑定了很多 Servlet,每个 Servlet 都是一个功能

可以看到画红线的,就是每个功能的地址。如果想看每个功能怎么实现的,可以点进去 Servlet,看它的 doGet 或者 doPost 或者 doPut 方法。
看完了这个,再退回到 NameNode 类中,然后就是去加载元数据(先不细看)

然后是创建 RPC 服务端,启动一个服务端,给别的组件调用


看这个方法:

看这个地方,这个就是使用 hadoop 的 RPC ,来创建一个 RPC 服务端了。此时我们在 NameNodeRpcServer 类中。

创建了之后,再回到 NameNode 中,发现这个 NameNodeRpcServer 是 NameNode 类的一个属性,意思是,NameNode 委托这个类去启动了 NameNodeRpcServer,在设计模式中,属于组合。
然后我们再来看这个 NameNodeRpcServer ,实现了很多的协议:

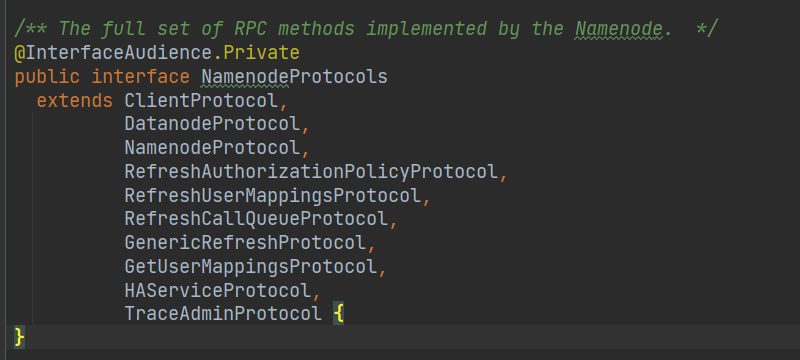
我们尝试在 ClientProtocol 中,找一找是否有创建目录的方法。

发现是有的,所以 NameNodeRpcServer 会去实现这个方法的。
到时候 NameNode 启动之后,就会往外提供服务了。
然后我们再回到 NameNode 类,看最后一些功能:
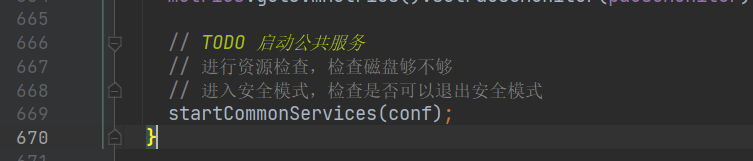
startCommonServices,主要做了两件事情,进行资源监察,检查磁盘够不够;检查是否可以退出安全模式。
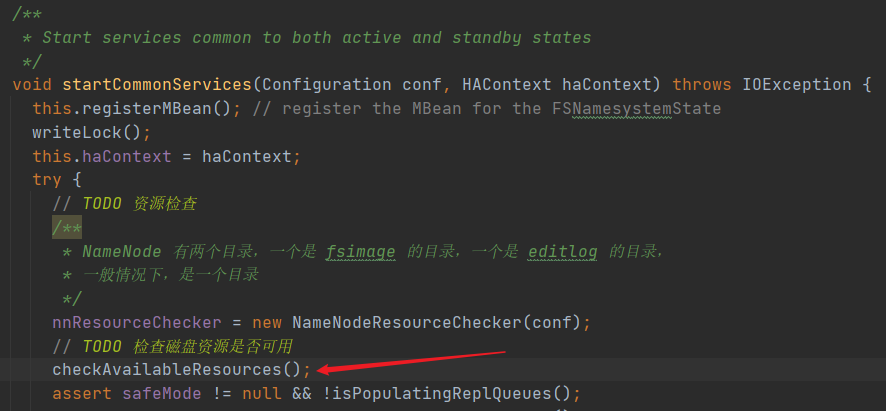
这个方法会检查配置文件中 fsimage 的目录 和 editlog 的目录磁盘资源是否充足。
最终会把磁盘是否足够的布尔值赋值给这个变量。
- private volatile boolean hasResourcesAvailable = false;
然后会判断是否进入安全模式:
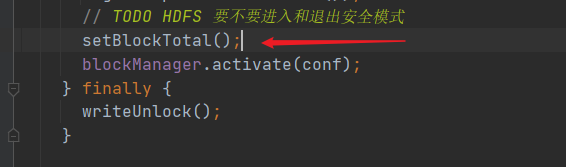
进入这个方法中:

这个 getCompleteBlocksTotal() 返回的是能正常使用的 Block 个数。
这个是怎么算的呢?
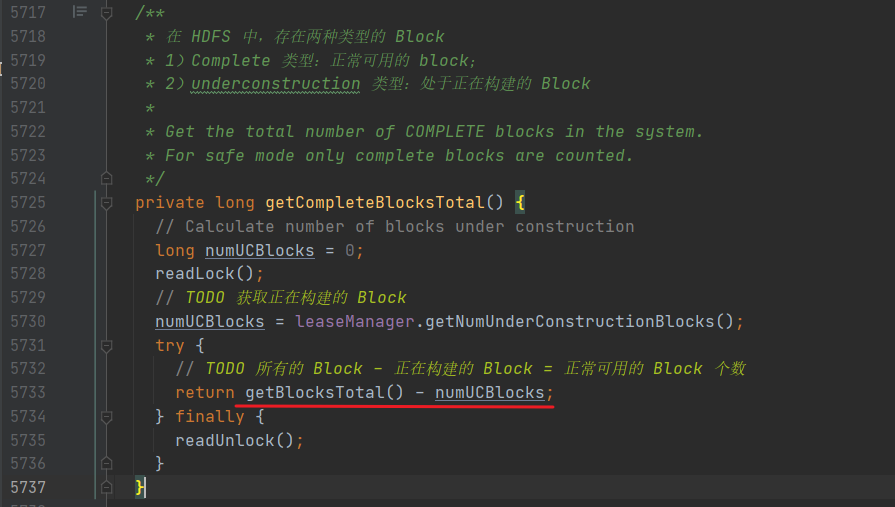
在 HDFS 中,存在两种类型的 Block,一种是 Complete 类型,即为正常可用的 Block;另一种是 underconstruction 类型,处于正在构建的 Block,相减,就是正常可用的 Block 个数了。
然后进入 checkMode 方法
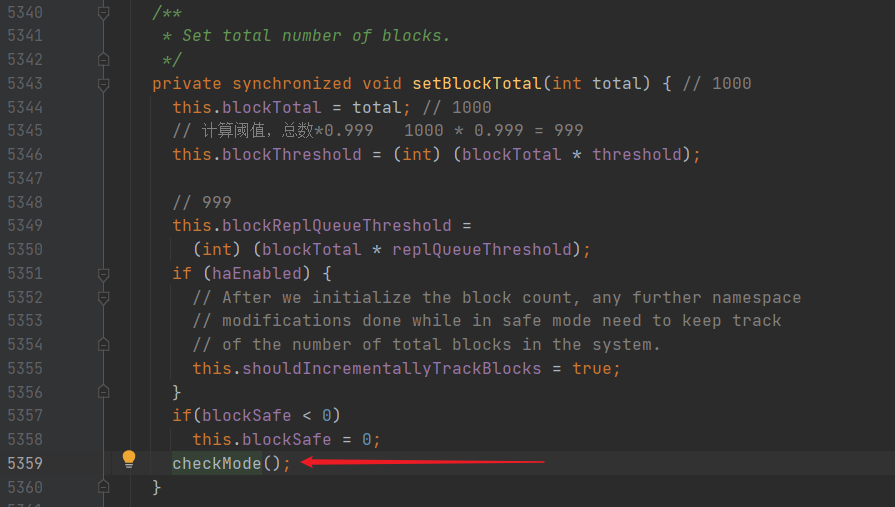
进去之后,有一个 needEnter() 方法,这个方法里,判断了是否进入安全模式
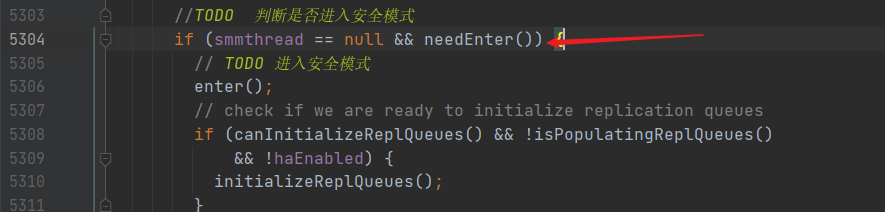
这里面有三个进入安全模式的条件:
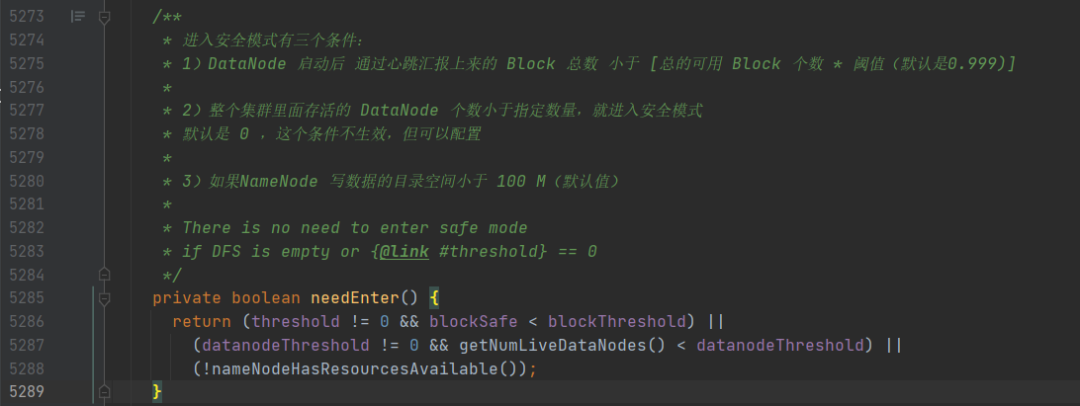
我们来看第一个条件:
- threshold != 0 && blockSafe < blockThreshold
threshold 默认配置是 0.999 ,不等于0;
blockSafe 可以在当前类中搜索一下。
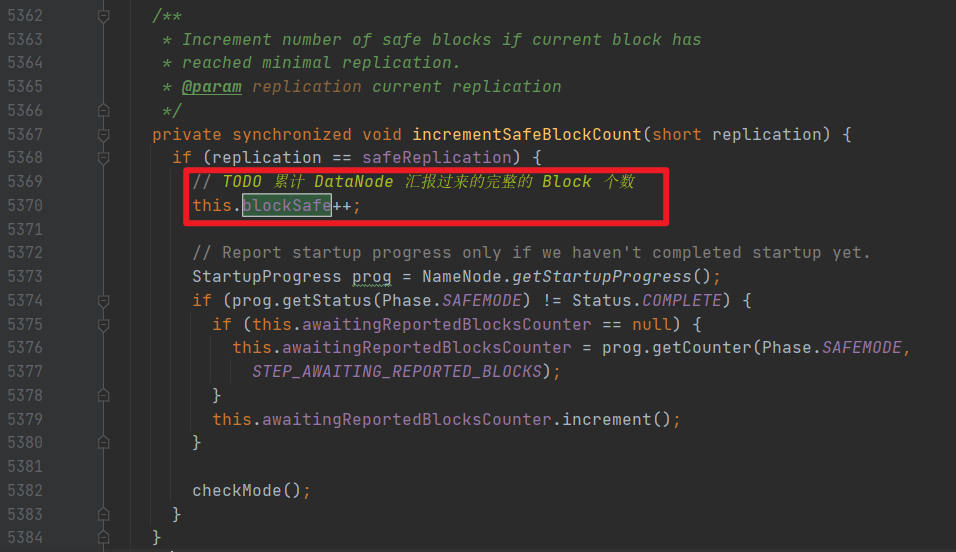
这个就表示,DataNode 每次心跳都要和 NameNode 汇报 自己的 Block 个数,每次汇报,这个值都会加 1.
如果 DataNode 汇报上来的 Block 个数小于所有可用的 Block 个数,就进入安全模式。
再来看第二个条件:
- datanodeThreshold != 0 && getNumLiveDataNodes() < datanodeThreshold
这个条件表示,所有可用的 DataNode 小于配置的个数,则进入安全模式。
但是 datanodeThreshold 的默认配置值是 0,所以这个条件不启用。
第三个条件:
- !nameNodeHasResourcesAvailable()
这个方法就是我们前面检查资源时,赋值出来的变量:
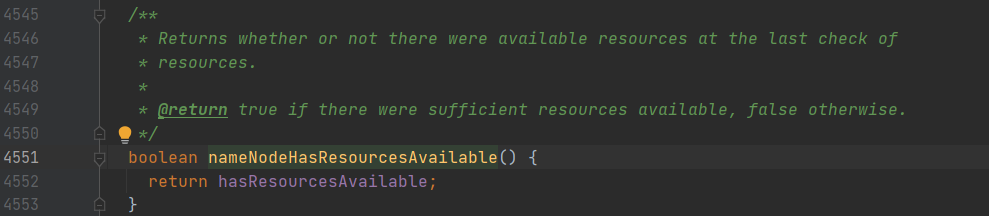
如果 NameNode 的 images 和 editlogs 所在的目录,磁盘空间不足,则进入安全模式。
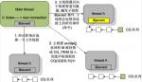
四、流程图
最后我们用一个流程图来总结一下 NameNode 启动流程:
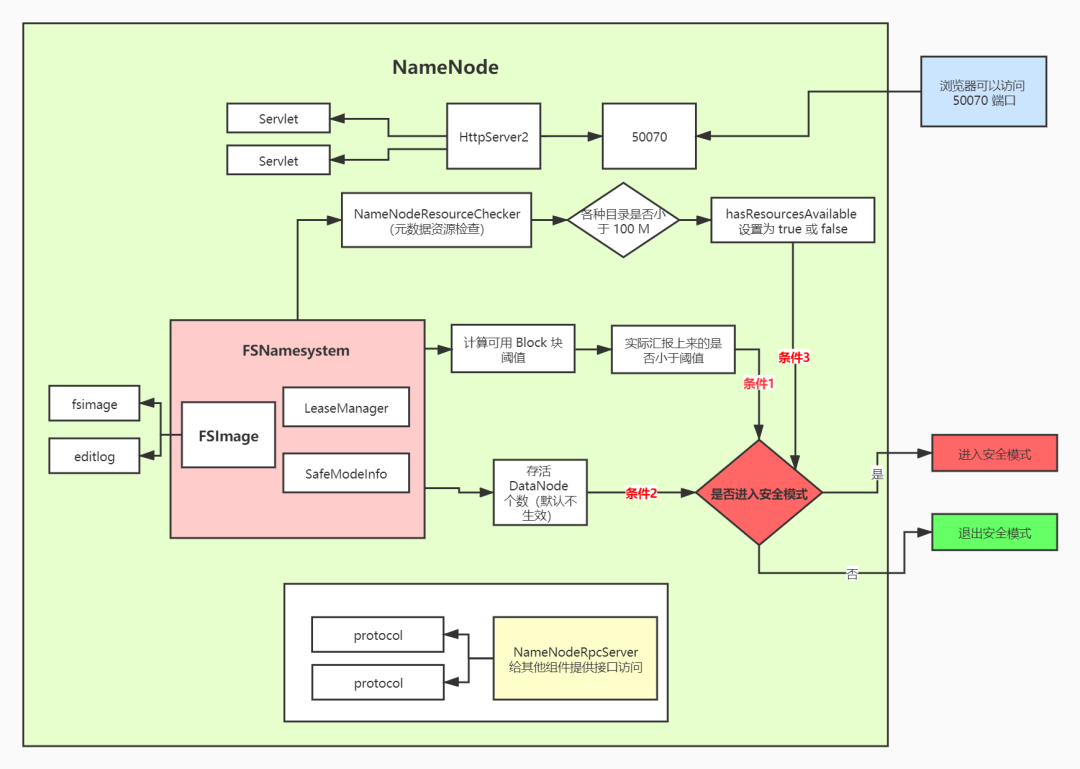
NameNode启动流程
五、小结
主要有三大块:
1、启动 HttpServer ,可以查看 50070 端口;
2、管理和加载元数据;
3、启动 RPCServer,使其他组件可以调用;
4、检查磁盘空间;
5、判断是否进入安全模式;