本文转载自微信公众号「moon聊技术」,作者moon聊技术。转载本文请联系moon聊技术公众号。
简介
我们知道redis是一个非常常用的内存型数据库,数据从内存中读取是它非常高效的原因之一,那么但是如果有一天,「redis分配的内存满了怎么办」?遇到这个面试题不要慌,这种问题我们分为两角度回答就可以:
- 「redis会怎么做」?
- 「我们可以怎么做」?
增加redis可用内存
这种方法很暴力,也很好用,我们直接通过增加redis的可用内存就可以了, 有两种方式
「通过配置文件配置」
- //设置redis最大占用内存大小为1000M
- maxmemory 1000mb
通过在redis安装目录下面的redis.conf配置文件中添加以下配置设置内存大小
「通过命令修改」
- //设置redis最大占用内存大小为1000M
- 127.0.0.1:6379> config set maxmemory 1000mb
- redis支持运行时通过命令动态修改内存大小
这种方法是立竿见影的,reids 内存总归受限于机器的内存,也不能无限制的增长,那么如果没有办法再增加 redis 的可用内存怎么办呢?
内存淘汰策略
实际上Redis定义了「8种内存淘汰策略」用来处理redis内存满的情况:
1.noeviction:直接返回错误,不淘汰任何已经存在的redis键
2.allkeys-lru:所有的键使用lru算法进行淘汰
3.volatile-lru:有过期时间的使用lru算法进行淘汰
4.allkeys-random:随机删除redis键
5.volatile-random:随机删除有过期时间的redis键
6.volatile-ttl:删除快过期的redis键
7.volatile-lfu:根据lfu算法从有过期时间的键删除
8.allkeys-lfu:根据lfu算法从所有键删除
这些内存淘汰策略都很好理解,我们着重讲解一下lru,lfu,ttl是怎么去实现的
lru的最佳实践?
lru是Least Recently Used的缩写,也就是「最近很少使用」,也可以理解成最久没有使用。最近刚刚使用过的,后面接着会用到的概率也就越大。由于内存是非常金贵的,导致我们可以存储在缓存当中的数据是有限的。比如说我们固定只能存储1w条,当内存满了之后,缓存每插入一条新数据,都要抛弃一条最长没有使用的旧数据。我们把上面的内容整理一下,可以得到几点要求:
- 「1.保证其的读写效率,比如读写的复杂度都是O(1)」
- 「2.当一条数据被读取,将它最近使用的时间更新」
- 「3.当插入一条新数据的时候,删除最久没有使用过的数据」
所以我们要尽可能的保证查询效率很高,插入效率很高,我们知道如果只考虑查询效率,那么hash表可能就是最优的选择,如果只考虑插入效率,那么链表必定有它的一席之地。
但是这两种数据结构单独使用,都有它的弊端,那么说,有没有一种数据结构,既能够保证查询效率,又能够保证插入效率呢?于是 hash+链表这种结构出现了
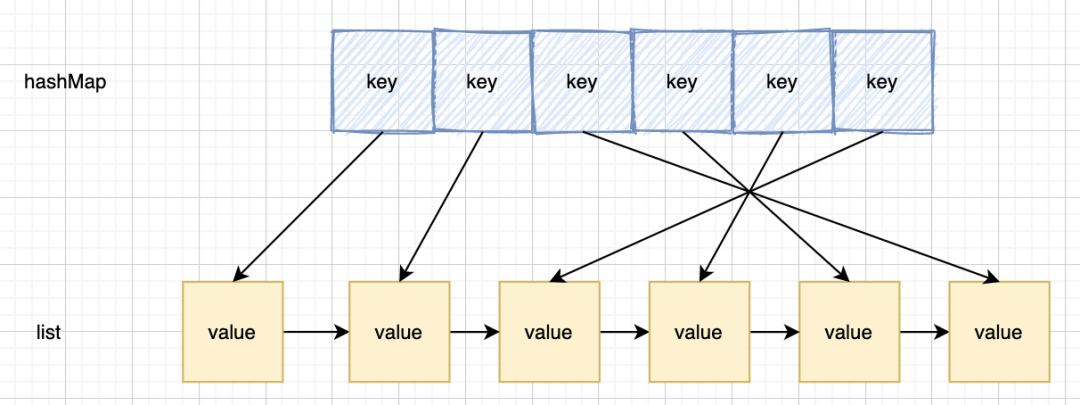
hash表用来查询在链表中的数据位置,链表负责数据的插入 当新数据插入到链表头部时有两种情况;
- 1.当链表满的时候,将链表尾部的数据丢弃。
- 这个比较简单,直接将链表尾部指针抹去,并且清除对应hash中的信息就好了
- 2.每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 这种情况我们发现,如果命中到链表中间节点,我们需要做的是
- 1).将该节点移到头节点
- 2).「将该节点的上一个节点的下一个节点,设置为该节点的下一个节点」,这里就会有一个问题,我们无法找到该节点的上一个节点,因为是单向链表,所以,新的模型产生了。
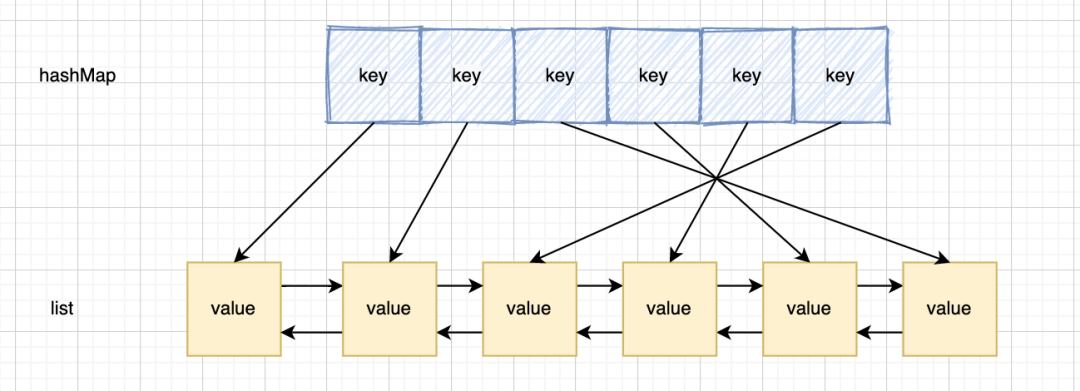
这时双向链表的作用也提现出来了。能直接定位到父节点。这效率就很高了。而且由于双向链表有尾指针,所以剔除最后的尾节点也十分方便,快捷
所以最终的解决方案就是采用「哈希表+双向链表」的结构
lfu的最佳实践?
LFU:Least Frequently Used,最不经常使用策略,在一段时间内,数据被「使用频次最少」的,优先被淘汰。最少使用(LFU)是一种用于管理计算机内存的缓存算法。主要是记录和追踪内存块的使用次数,当缓存已满并且需要更多空间时,系统将以最低内存块使用频率清除内存.采用LFU算法的最简单方法是为每个加载到缓存的块分配一个计数器。每次引用该块时,计数器将增加一。当缓存达到容量并有一个新的内存块等待插入时,系统将搜索计数器最低的块并将其从缓存中删除。
这里我们提出一种达到 O(1) 时间复杂度的 LFU 实现方案,它支持的操作包括插入、访问以及删除
如图:
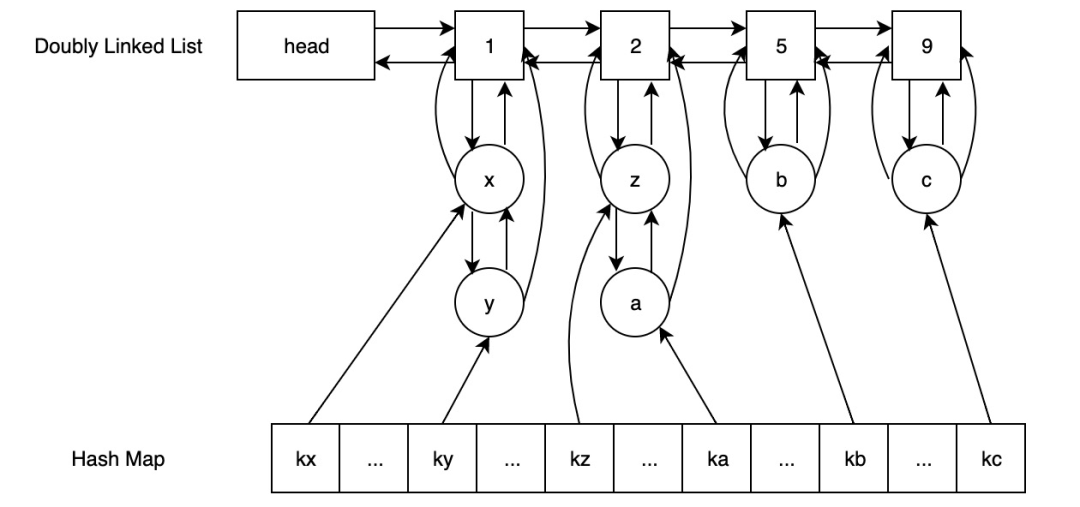
由两个双向链表+哈希表组成,上方的双向链表用来计数,下方的双向链表用来记录存储的数据,该链表的头节点存储了数字,哈希表的value对象记录下方双向链表的数据 我们这里按照插入的流程走一遍:
- 将需要存储的数据插入
- 在hash表中「存在」,找到对应的下方双向链表,将该节点的上一个节点和该节点的下一个节点相连(这里可能只有自己,直接移除就好),然后判断自己所在上方双向链表的计数是否比当前计数大1
- 「如果是」,则将自己移到该上方双向链表,并且「判断该双向链表下是否还有元素」,如果没有,则要删除该节点
- 「如果不是或者该上方双向列表无下个节点」则新加节点,将计数设为当前计数+1
- 在hash表「不存在」,将数据存入hash表,将数据与双向链表的头节点相连(这里有可能链表未初始化)
这样当查找,插入时效率都为O(1)
redis TTL 是怎么实现的?
TTL存储的数据结构
redis针对TTL时间有专门的dict进行存储,就是redisDb当中的dict *expires字段,dict顾名思义就是一个hashtable,key为对应的rediskey,value为对应的TTL时间。?dict的数据结构中含有2个dictht对象,主要是为了解决hash冲突过程中重新hash数据使用。



TTL 设置过期时间
TTL设置key过期时间的方法主要是下面4个:
- expire 按照相对时间且以秒为单位的过期策略
- expireat 按照绝对时间且以秒为单位的过期策略
- pexpire 按照相对时间且以毫秒为单位的过期策略
- pexpireat 按照绝对时间且以毫秒为单位的过期策略
- {"expire",expireCommand,3,"w",0,NULL,1,1,1,0,0},
- {"expireat",expireatCommand,3,"w",0,NULL,1,1,1,0,0},
- {"pexpire",pexpireCommand,3,"w",0,NULL,1,1,1,0,0},
- {"pexpireat",pexpireatCommand,3,"w",0,NULL,1,1,1,0,0},
expire expireat pexpire pexpireat
从实际设置过期时间的实现函数来看,相对时间的策略会有一个当前时间作为基准时间,绝对时间的策略会「以0作为一个基准时间」。
- void expireCommand(redisClient *c) {
- expireGenericCommand(c,mstime(),UNIT_SECONDS);
- }
- void expireatCommand(redisClient *c) {
- expireGenericCommand(c,0,UNIT_SECONDS);
- }
- void pexpireCommand(redisClient *c) {
- expireGenericCommand(c,mstime(),UNIT_MILLISECONDS);
- }
- void pexpireatCommand(redisClient *c) {
- expireGenericCommand(c,0,UNIT_MILLISECONDS);
- }
整个过期时间最后都会换算到绝对时间进行存储,通过公式基准时间+过期时间来进行计算。?对于相对时间而言基准时间就是当前时间,对于绝对时间而言相对时间就是0。?中途考虑设置的过期时间是否已经过期,如果已经过期那么在master就会删除该数据并同步删除动作到slave。?正常的设置过期时间是通过setExpire方法保存到 dict *expires对象当中。
- /*
- *
- * 这个函数是 EXPIRE 、 PEXPIRE 、 EXPIREAT 和 PEXPIREAT 命令的底层实现函数。
- *
- * 命令的第二个参数可能是绝对值,也可能是相对值。
- * 当执行 *AT 命令时, basetime 为 0 ,在其他情况下,它保存的就是当前的绝对时间。
- *
- * unit 用于指定 argv[2] (传入过期时间)的格式,
- * 它可以是 UNIT_SECONDS 或 UNIT_MILLISECONDS ,
- * basetime 参数则总是毫秒格式的。
- */
- void expireGenericCommand(redisClient *c, long long basetime, int unit) {
- robj *key = c->argv[1], *param = c->argv[2];
- long long when; /* unix time in milliseconds when the key will expire. */
- // 取出 when 参数
- if (getLongLongFromObjectOrReply(c, param, &when, NULL) != REDIS_OK)
- return;
- // 如果传入的过期时间是以秒为单位的,那么将它转换为毫秒
- if (unit == UNIT_SECONDS) when *= 1000;
- when += basetime;
- /* No key, return zero. */
- // 取出键
- if (lookupKeyRead(c->db,key) == NULL) {
- addReply(c,shared.czero);
- return;
- }
- /*
- * 在载入数据时,或者服务器为附属节点时,
- * 即使 EXPIRE 的 TTL 为负数,或者 EXPIREAT 提供的时间戳已经过期,
- * 服务器也不会主动删除这个键,而是等待主节点发来显式的 DEL 命令。
- *
- * 程序会继续将(一个可能已经过期的 TTL)设置为键的过期时间,
- * 并且等待主节点发来 DEL 命令。
- */
- if (when <= mstime() && !server.loading && !server.masterhost) {
- // when 提供的时间已经过期,服务器为主节点,并且没在载入数据
- robj *aux;
- redisAssertWithInfo(c,key,dbDelete(c->db,key));
- server.dirty++;
- /* Replicate/AOF this as an explicit DEL. */
- // 传播 DEL 命令
- aux = createStringObject("DEL",3);
- rewriteClientCommandVector(c,2,aux,key);
- decrRefCount(aux);
- signalModifiedKey(c->db,key);
- notifyKeyspaceEvent(REDIS_NOTIFY_GENERIC,"del",key,c->db->id);
- addReply(c, shared.cone);
- return;
- } else {
- // 设置键的过期时间
- // 如果服务器为附属节点,或者服务器正在载入,
- // 那么这个 when 有可能已经过期的
- setExpire(c->db,key,when);
- addReply(c,shared.cone);
- signalModifiedKey(c->db,key);
- notifyKeyspaceEvent(REDIS_NOTIFY_GENERIC,"expire",key,c->db->id);
- server.dirty++;
- return;
- }
- }
- setExpire函数主要是对db->expires中的key对应的dictEntry设置过期时间。
- /*
- * 将键 key 的过期时间设为 when
- */
- void setExpire(redisDb *db, robj *key, long long when) {
- dictEntry *kde, *de;
- /* Reuse the sds from the main dict in the expire dict */
- // 取出键
- kde = dictFind(db->dict,key->ptr);
- redisAssertWithInfo(NULL,key,kde != NULL);
- // 根据键取出键的过期时间
- de = dictReplaceRaw(db->expires,dictGetKey(kde));
- // 设置键的过期时间
- // 这里是直接使用整数值来保存过期时间,不是用 INT 编码的 String 对象
- dictSetSignedIntegerVal(de,when);
- }
redis什么时候执行淘汰策略?
在redis种有三种删除的操作此策略
- 定时删除:对于设有过期时间的key,时间到了,定时器任务立即执行删除
- 因为要维护一个定时器,所以就会占用cpu资源,尤其是有过期时间的redis键越来越多损耗的性能就会线性上升
- 惰性删除:每次只有再访问key的时候,才会检查key的过期时间,若是已经过期了就执行删除。
- 这种情况只有在访问的时候才会删除,所以有可能有些过期的redis键一直不会被访问,就会一直占用redis内存
- 定期删除:每隔一段时间,就会检查删除掉过期的key。
- 这种方案相当于上述两种方案的折中,通过最合理控制删除的时间间隔来删除key,减少对cpu的资源的占用消耗,使删除操作合理化。
巨人的肩膀
https://www.jianshu.com/p/53083f5f2ddc https://zhuanlan.zhihu.com/p/265597517