













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
一张图片的焦距,能在老鼠玩具和日历尺之间自由切换:

甚至能完成图片上任一物体的对焦,呈现出不同物体在不同深度时的照片:

这张具有神奇魔力的图片,就是集成了“全部物体信息”的全息图。
生成这类全息图,往往需要大量计算才能完成。
然而,来自MIT的团队开发了一种新算法,不需要复杂仪器、也不需要等几个小时,生成这样一张全息图,只需要在智能手机上耗费不到1秒的时间。
要知道,就在去年11月份,三星的科学家们生成3D全息视频所用的处理器,尺寸还是太大,没能整合到手机上:

那么,这种快速生成3D全息图的方法,究竟是怎么做到的?
用神经网络快速“切蛋糕”
首先,全息图是什么?
举个例子,visa信用卡上的鸽子,就利用了全息图来做防伪标志。
全息图即“全部的信息”,这种图片包含物体的幅度和相位信息。
普通照相机,拍摄出来的照片只包含物体的幅度信息(亮暗),相位信息(远近)却无法直接保存。
这也是为什么,我们平时看见的2D照片“没有立体感”。
此前,计算机要想360°全方位生成全息图,通常得从多个角度进行干涉、衍射,再将相位信息拼合起来,与振幅信息叠加后生成图片。
多角度生成相位信息,就像是在一个球形蛋糕上精准地切割8刀,将之分成8块,对每块进行相位重现:
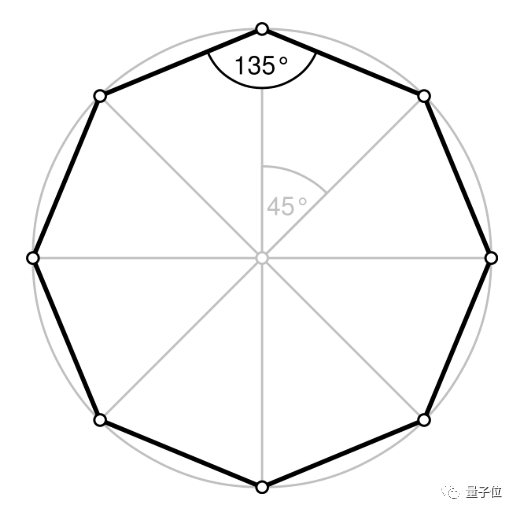
然而,这种方法所需要的计算量往往巨大,耗时很久,完全无法在智能手机上运行。
因此,MIT团队思考,能不能采用深度学习的方法,只通过3个角度,就把“蛋糕”分成8块,来生成全息图?

他们精挑细选出了4000张包含幅度、相位信息的图像,以及这些图像对应的3D全息图,用来训练神经网络。

整体思路大致如下:获取物体的相位信息后,生成点云,再结合残差神经网络,生成整体的全息图。
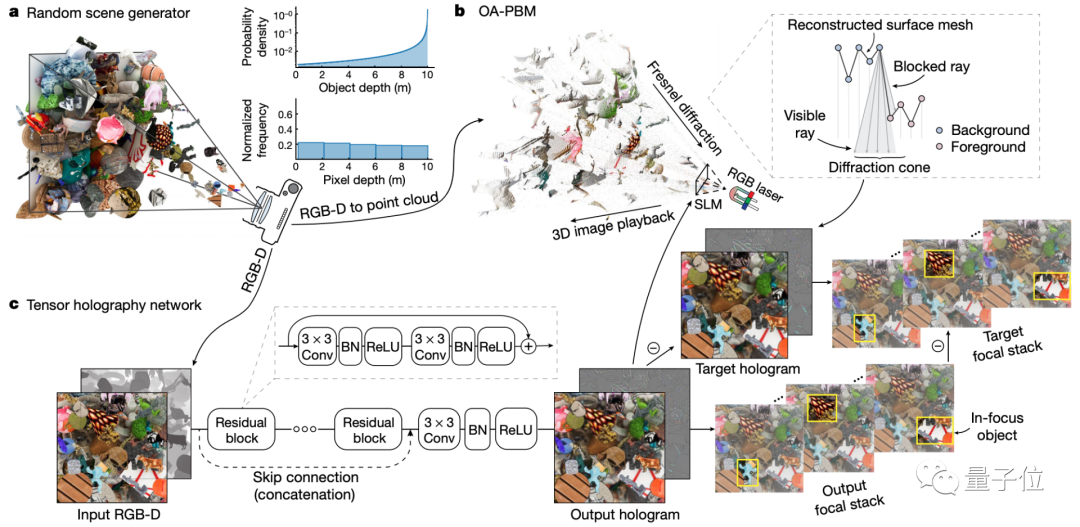
那么,这种全息图的效果如何呢?
可对焦任意物体,内存占用不到1MB
事实证明,利用神经网络进行预测,只需要不到640KB的内存就能生成全息图。
如果在消费级GPU上,这种神经网络模型,每秒能生成60张分辨率为1080p的彩色3D全息图。
而在智能手机如iPhone 11 Pro上,每秒能生成1.1张全息图;至于Google Edge TPU上,每秒则能生成2张全息图。
以动画角色大雄兔(Big Buck Bunny)为例,右下角是它的深度图。

从图中可见,利用神经网络(右)生成的全息图像,几乎和用原有方法(左)生成的全息图像一模一样。
而且,无论是远处的小黄花,还是近处的兔子眼睛,都能完美对焦。

表面上看起来是一样的话,具体到幅度和相位信息上如何呢?
从图中可见,利用神经网络预测的幅度和相位信息,也与真实值非常接近。
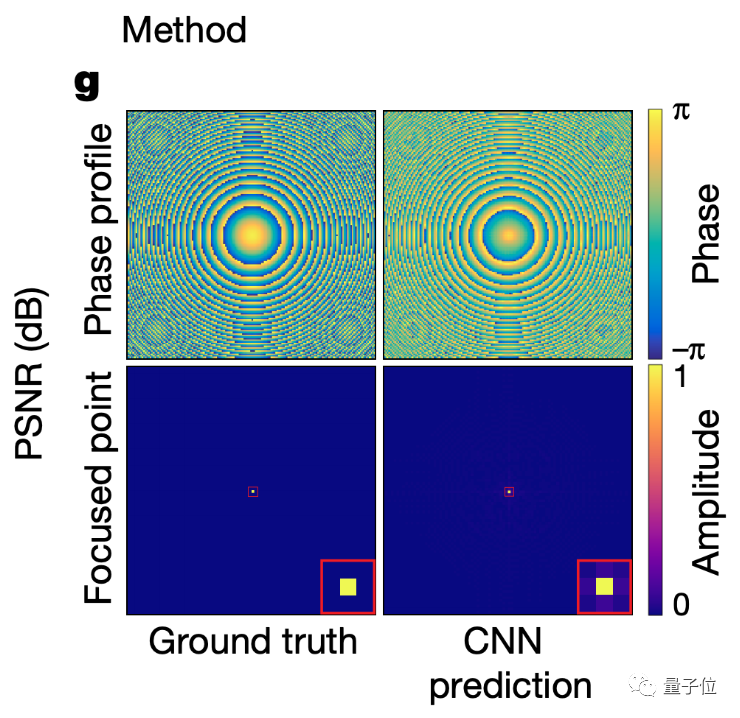
即使是现实中的照片,也与实际生成目标非常接近了。

当然,从细节来看的话,还是略微有一点差距。

相比于现有的VR和AR方案,3D全息图是3D可视化的另一个实现方案。
但在使用VR的时候,用户实际上是盯着2D显示屏,产生3D错觉,因此可能会产生视觉疲劳、头晕等症状。
而3D全息图则允许眼睛调整焦距,即交替地对前景和背景进行聚焦,能有效缓解这种症状。
下一步,团队计划添加眼球追踪技术,让用户的眼睛看向哪里,哪里就生成部分高清全息图。
在这种方案下,计算机只需要部分生成全息图,实时运用下,效果也能更快更好。
以及,索尼赞助了这项研究,所以……
作者介绍
论文一作史亮,2014年毕业于北航,硕士毕业于斯坦福,目前于MIT就读博士,研究方向包括VR/AR,以及机器学习和计算机图形学。
论文二作李北辰,2018年毕业于清华大学,目前于MIT就读博士,研究方向是机器学习在计算机图形学中的应用。
论文地址:
https://www.nature.com/articles/s41586-020-03152-0.pdf




























