












「崩溃」与「卡顿」、「异常退出」等一样,是影响App稳定性常见的三种情况。相关数据显示,当iOS的崩溃率超过0.8%,Android的崩溃率超过0.4%的时候,活跃用户有明显下降态势。它不仅会造成关键业务中断、用户留存率下降、品牌口碑变差等负面影响,而且会直接带来卸载和流失。也同时给开发者带来不可小觑的资本损失。
那么,崩溃率低的App质量就高么?是否可以通过崩溃率直接判断App的稳定性?
首先,衡量一个App质量好坏时我们需要定义一个统一的口径,即哪些指标可以作为稳定性的评估口径?以友盟+的U-APM定义的稳定率这个概念为例,评价一个App的稳定性和质量,一般从以下三点综合考虑:
- 发生了崩溃,如java崩溃和Native崩溃,即用崩溃率这个指标来评估计算;
- 异常退出,如:low memory killer、任务列表中划掉、系统异常、断电、用户触发关机/重启等,即用异常率这个指标来评估计算。
- 崩溃,也就是程序出现异常,导致程序退出。包括:
- Java崩溃,也就是在Java代码中出现了未捕获异常,导致程序异常退出。如:空指针异常、数组越界异常等。
- Native异常,也就是在Native代码中,出现错误产生相应的signal信号,导致程序异常退出。如:访问非法地址、地址对其 问题等。
Java崩溃的捕获相对会简单一些,Native崩溃的捕获可能要求我们对系统底层知识要有一定的掌握。我们知道Android是基于Linux系统的,系统中的崩溃大多是由于编码错误或硬件错误导致的。当系统遇到不可恢复的错误时会通过异常中断的方式触发异常处理流程,这些中断的处理被统一为了信号量。当应用程序接收到某个信号量时会按照内核默认的动作处理,如Term、lgn、Core、Stop、Cont。同时我们也可以通过sigaction注册接收信号来指定处理动作,比如捕获崩溃信息等。当然捕获过程中也会有一些困难点,尤其在极端环境中,比如栈溢出时,由于栈空间已经被用完,造成我们的信号处理函数没法被调用,以至于无法捕获到崩溃信息,这时我们需要考虑使用signalstack,使我们的信号处理函数可以在堆里面分配到一块内存空间作为“可替换信号栈”来处理崩溃信息。
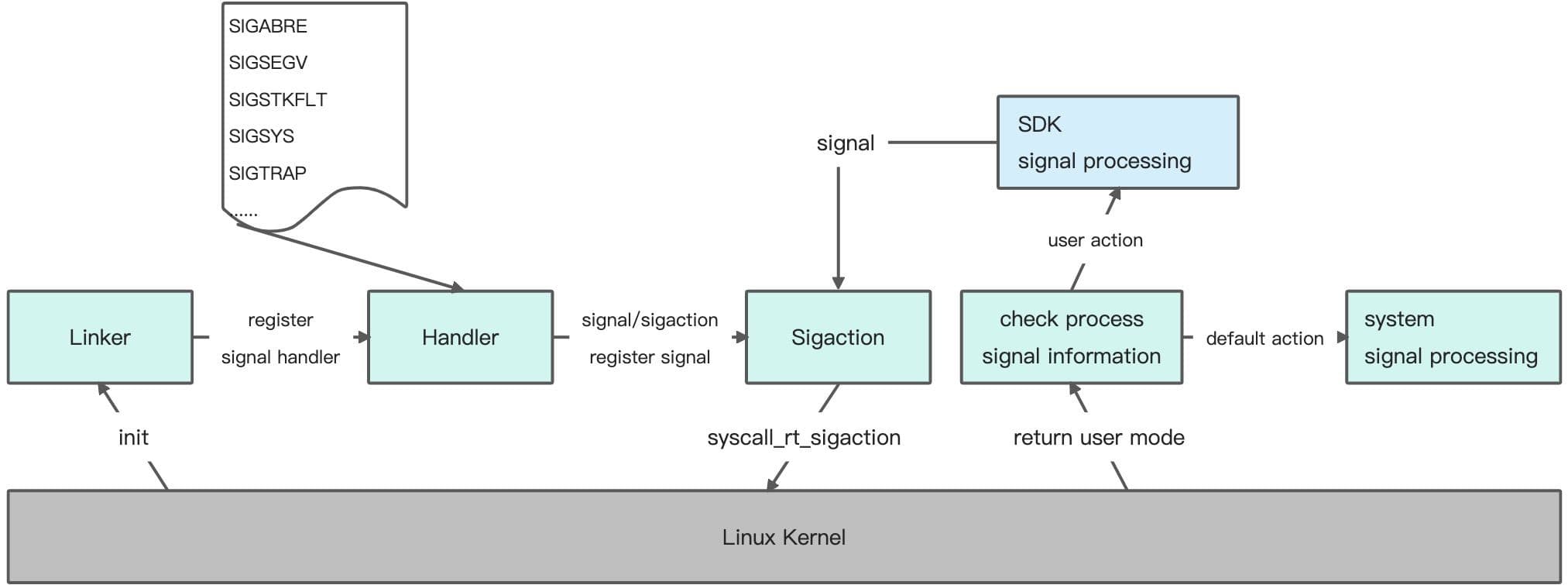
当然,除了稳定、安全的捕获能力外,还需要丰富崩溃现场的上下文信息,比如Logcat信息、调用栈信息、设备信息、环境信息等等,为我们后续定位和解决问题提供全面的参考。
对于发生崩溃的情况,我们使用崩溃率作为数据指标。包括:
- UV崩溃率,也就是发生崩溃错误的去重用户/去重活跃总用户;
- PV崩溃率,也就是发生崩溃错误的次数/启动次数;
启动崩溃率,也就是应用启动过程中发生的崩溃,很容易被忽略但又非常重要的崩溃指标,因为启动是APP生命周期中非常重要的一个阶段,很多广告、闪屏、活动等内容都在这个过程中透出,同时启动时又需要加载各种初始化,并且如果启动出现错误,往往热修复、降级融灾策略都无法弥补。
ANR,也就是Application Not Responding,当应用程序一段时间无法及时响应,则会弹出ANR对话框,让用户选择继续等待,还是强制关闭。从用户体验的角度看,有时候ANR可能要比崩溃会带来更糟糕的体验,所以开发者重视崩溃的同时也要非常重视ANR。
ANR捕获的准确性一直是不断升级打怪、不断完善的过程。早期我们通过FileObserver 监听/data/anr/traces.txt文件的变化进行捕获和上报,但很遗憾随着版本升级,系统和厂商开始收紧系统文件的权限,此方案的覆盖设备情况越来越低,造成ANR捕获的准确性也一直降低。
随后我们改进为监控消息队列的运行时间的方式捕获ANR,也就是向主线程Looper中放入一个空消息,监听该空消息在5秒后是否被执行,但该方案无法真实的捕获ANR情况(存在漏报和误报情况),并且也无法得到完整的ANR内容。后续我们参考Android ANR的实现原理,实现了一套实时、准确的ANR捕获方案,并且可以兼容所有系统版本。我们知道系统的system_server 进程在检测到 APP 出现 ANR 后,会向出现ANR 的进程发送 SIGQUIT (signal 3) 信号。默认情况,系统的 libart.so 会收到该信号,并调用 Java 虚拟机的 dump 方法生成 traces。
我们通过拦截SIGQUT,在出现ANR时优先接收到信号,并生成traces和ANR日志,在处理完信号后,将信号继续传递给系统让系统生成traces文件,生成traces文件时,在保证内容与系统原生的一致性的同时还对生成traces文件的速度进行了明显的提升,有效地避免了可能因生成 traces 时间过长,而被 system_server 使用 SIGKILL (signal 9) 再次强杀,同时我们对捕获到的内容进行了丰富,包括:触发 ANR 的原因、手机中 TOP 进程CPU 使用率、ANR 进程中 TOP 线程 CPU 使用率、CPU 各核心处理时间分布情况、磁盘 IO 操作等待时长等重要信息,对分析、定位和解决 ANR 问题,提供了更加强有力的支撑!
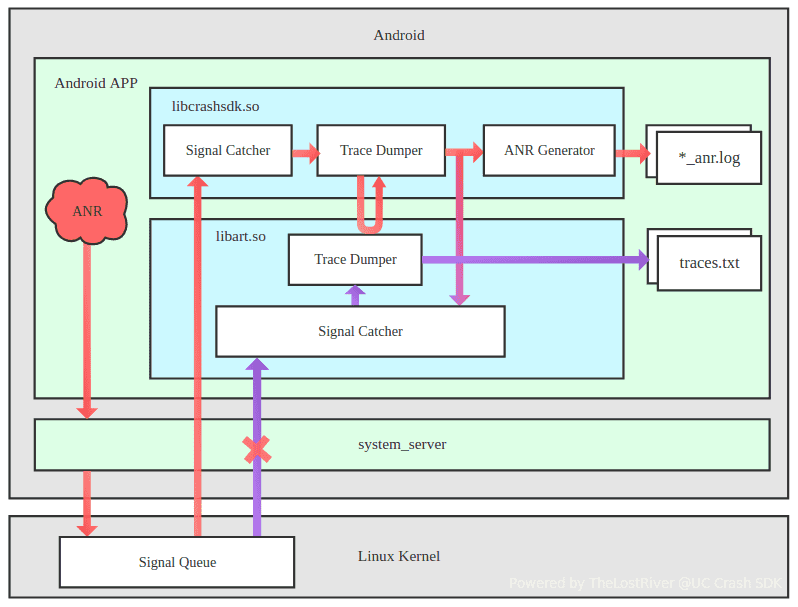
同样对于发生ANR的情况,我们也分为UV ANR率和PV ANR率,算法可参考如上崩溃率的计算。
当然,除了崩溃和ANR,我们往往忽略了异常退出这种场景,但往往通过异常退出我们可以发现如low memory killer、系统重启等无法正常捕获到的问题。比如兼容性问题导致的闪退、设备重启、三方库主动调用exit函数,导致应用闪退次数增加等难以发现的问题,所以通过异常退出率我们可以比较全面的了解和衡量应用的稳定性。
综上,对于文章开始的那个问题,我想大家都应该有答案了吧。当然,我们不应该为了掩盖代码质量问题,通过手动try catch去规避某些问题,这样有可能会打断用户的正常使用,并造成感知性的阻断反馈,应该从用户使用APP时的真实感知出发,当出现问题时及时捕获和处理问题。
App的稳定性是一个长期不断迭代的过程,在这个过程中U-APM是一个很好的提升效率降低成本的工具,他提供了收集、解析、聚合、分析的能力,下一期我们会从如何通过U-APM解决和处理崩溃、ANR等问题进行讲解,敬请期待。




















