













本文转载自微信公众号「Java极客技术」,作者鸭血粉丝。转载本文请联系Java极客技术公众号。
Hello,大家好,我是阿粉~
最近阿粉接到了一个业务需求,需要开发一个业务接口,批量删除 Redis 中数据。
这个功能点其实很简单,只要让外部传入需要删除键信息,然后在接口内部遍历调用删除命令即可。
按照这个思路,功能很快就开发完成,然后顺利的上线。
上线之后,运行一段时间,调用业务方反馈,当要删除的数据很多的时候,这个接口响应时间就比较长,然后希望我们这边优化一下,降低响应时间。
那优化办法其实有很多,比如使用多线程删除等,不过这一次并没有采用这个,最终使用了 Redis pipeline(管道)命令进行了优化。
所以今天这篇文章就给大家介绍一下 Redis pipeline 命令,以及相关原理,文章涉及到知识点如下图所示:
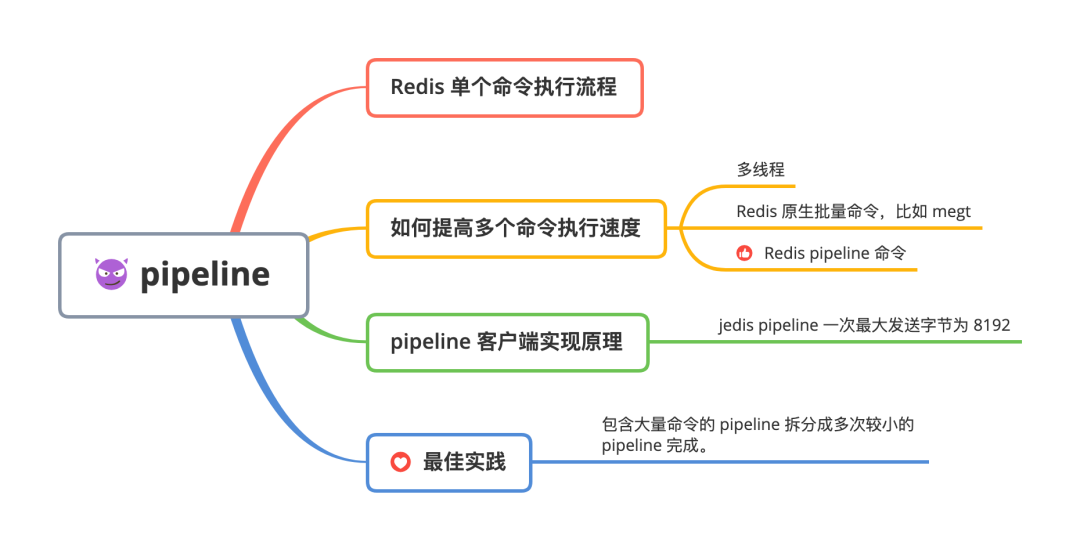
为什么多次调用 Redis 命令比较慢Redis 客户端执行一个命令需要经历流程如下图所示:
总共需要经过四个流程:
- 客户端发送命令
- Redis 服务收到命令等待处理
- Redis 服务端处理命令
- Redis 服务返回执行结果
Redis 的客户端与服务可能部署在不同的机器上,这里我们假设 Redis 客户端部署在北京,而 Redis 服务端在广州,两地的网络延时为 50ms。
一次 Redis 命令,1 与 4 这两个流程就需要耗费 100ms, 而 2 与 3 在由于是在 Redis 服务端执行,执行速度会很快,可以忽略不计。
此时客户端如果需要执行 N 次 Redis 命令,我们就需要耗费 2N*100ms 时间,执行命令越多,耗时越长。
这就是文章开头 Redis 删除多个命令比较慢的主要原因。
Redis pipeline 流水线执行命令那如何解决这类问题了?
解决办法有三种,第一种利用多线程机制,并行执行命令,提高执行速度。
第二种,调用 mget 这类命令,这类命令可以一次操作多个键,Redis 服务端收到命令之后,将会批量执行。
但是 mget这类批量命令毕竟是少数,很多情况下我们没办法直接使用,就像我们上面的例子。
这样的话,只能使用最后一种办法,使用 Redis pipeline命令。
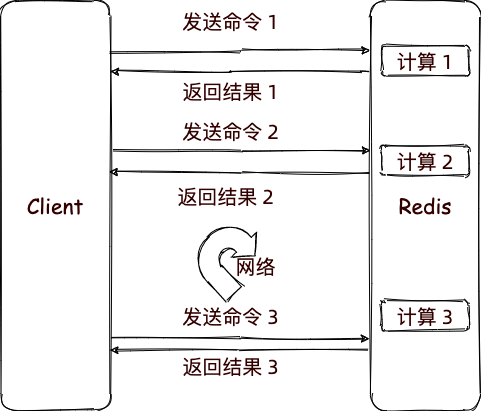
开启 Redis pipeline 之后,再执行 Redis 的其他命令,命令将不会发送给服务端,而是先暂存在客户端,左后等到所有命令都执行完,然后再统一发送给服务端。
服务端会根据发送过来的命令的顺序,依次运行计算。
然后同样先将结果暂存服务端,等到命令都执行完毕之后,统一返回给客户端。
通过这种方式,减少多个命令之间网络交互,有效的提高多个命令执行的速度。
如上图所示,开启 Redis Pipeline 之后,客户端运行的 5 个命令将会一起发送到服务端。服务依次运行命令,然后统一返回。
介绍完原理,我们来看下如何使用 Redis Pipeline ,下面代码以 Jedis 为例。
- JedisPoolConfig poolConfig = new JedisPoolConfig();
- poolConfig.setMaxIdle(100);
- poolConfig.setTestOnBorrow(false);
- poolConfig.setTestOnReturn(false);
- JedisPool jedisPool = new JedisPool(poolConfig, "127.0.0.1", Integer.parseInt("6379"), 60*1000, "1234qwer");
- Jedis jedis = jedisPool.getResource();
- Pipeline pipelined = jedis.pipelined();
- for (int i = 0; i < 100; i++) {
- pipelined.set("key" + i, "value" + i);
- }
- pipelined.sync();
Jedis#pipelined 将会开启 Redis Pipeline,而Pipeline 这个类提供所有 Redis 可以使用的命令:
当执行完所有的命令之后,调用 Pipelined#sync 命令,所有命令数据将会统一发送到到 Redis 中。
上面的例子中,Pipelined#sync 方法调用之后不会返回任何结果。
如果此时需要处理 Redis 的返回值,那么我们需要调用 Pipelined#syncAndReturnAll 方法,这个方法返回值将会是一个集合,返回结果按照 Redis 命令的顺序排序。
解密 pipeline 实现原理
Redis pipeline 命令的实现,其实需要客户端与服务端同时支持,并且实际执行过程中,Redis pipeline 会根据需要发送命令数据量大小进行拆分,拆分成多个数据包进行发送。
这么做主要原因是因为,如果一次组装 pipeline 数据量过大,一方面会增加客户端的等待时间,而另一方面会造成一定的网络阻塞。
不同 Redis 客户端 pipeline 发送的最大字节数不太相同,比如 jedis-pipeline 每次最大发送字节数为8192。
下面我们从源码侧,看下 jedis pipeline 实现机制。
Pipeline 所有命令方法,底层最终将会调用 Protocol#sendCommand方法,这个方法主要就是向 RedisOutputStream 输出流中写入数据。
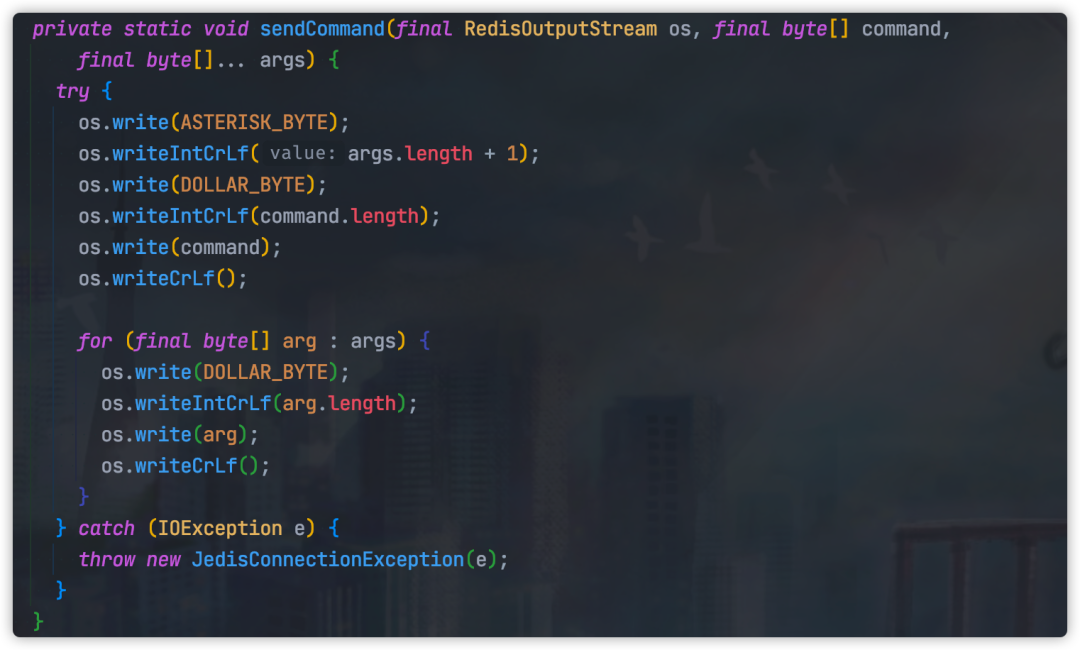
RedisOutputStream#write方法如下图所示:
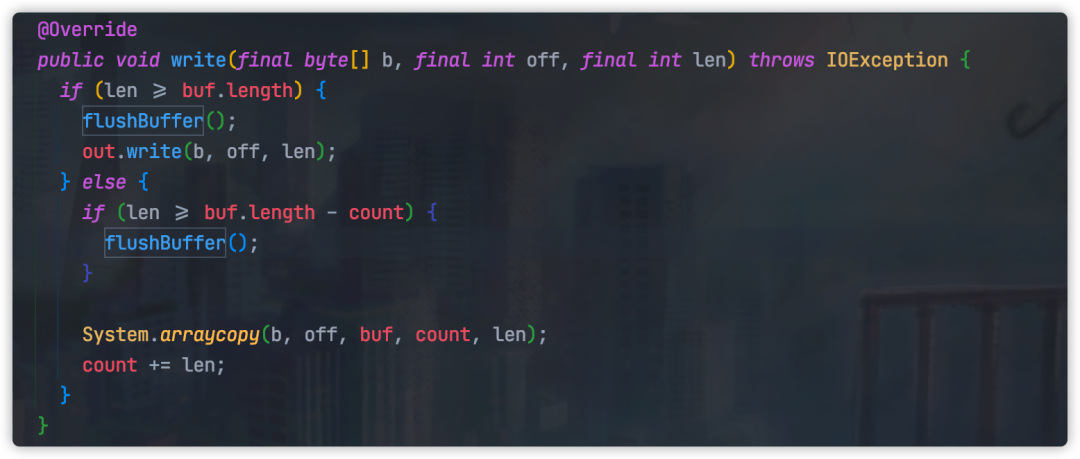
这个方法内,一旦缓冲的数据大小超过指定大小,目前为 8192,就会立刻将数据全部写入到真正输出流中。
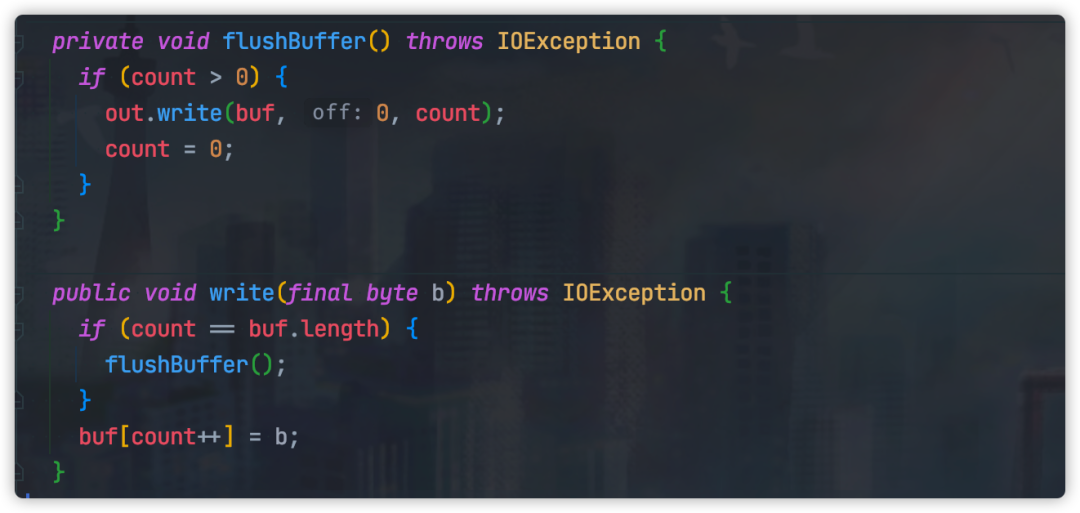
pipeline 多个命令实际发送流程图如下所示:
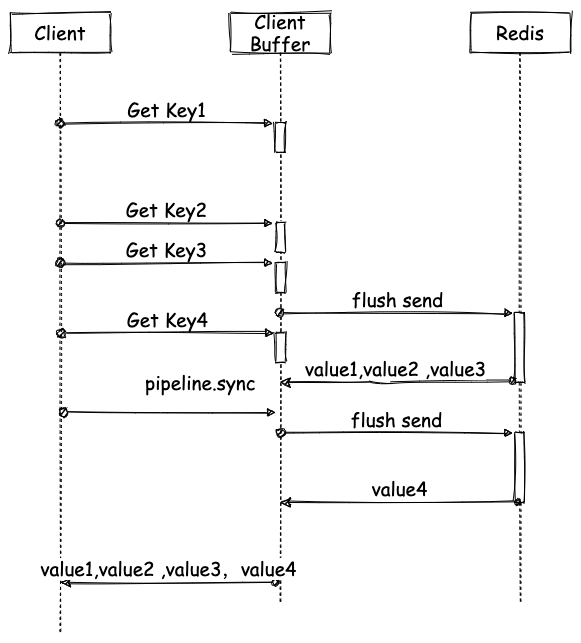
一旦 Redis 客户端将部分 pipeline 中执行命令的发送给 Redis 服务端,服务端就会立即运行这些命令,然后返回给客户端。
但是此时客户端并不会去读取,所以返回的响应数据将会暂存在客户端的 Socket 接收缓冲区中。
如果响应数据比较大,填满缓冲区,此时客户端会通过 TCP 流量控制机制,ACK 返回 WIN=0(接收窗口)来控制服务端不要再发送数据。
这时这些响应数据将会一直暂存在 Redis 服务端输出缓存中,如果数据比较多,将会占用很多内存。
所以使用 Redis Pipeline 机制一定注意返回的数据量,如果数据很多,建议将包含大量命令的 pipeline 拆分成多次较小的 pipeline 来完成。
总结Redis 的 pipeline 命令可以批量执行多个 redis 命令,它通过减少网络的调用次数,从而有效提高的多个命令执行的速度。
不过我们使用过程,一定主要执行数据的大小,如果数据过大,可以考虑将一个 pipeline 拆

















