本文转载自微信公众号「明哥的IT随笔」,作者IT明哥。转载本文请联系明哥的IT随笔公众号。
随着整个IT生态的进一步发展,在2021年,IT从业人员对大数据的发展趋势有一个普遍的共识,就是大数据和云计算的进一步深度融合的趋势,即大数据拥抱云计算,走向云原生化。
明哥在这里,跟大家一起看下,大数据与云计算的深度融合的趋势下,深度融合具体体现在哪些地方。
大数据与云计算的深度融合,体现在以下几个方面:
一是应用方的大数据平台上云:使用大数据技术的业务应用建设方,不再自建数据中心,而是将大数据平台搬到了云上,有的是在云厂商的 IaaS 层上自建大数据平台(现在以这种方式在云上使用大数据的案例已经比较少了),有的直接使用云厂商提供的 PaaS 层大数据相关产品(aws 的 emr,阿里云的 e-MapReduce等),有的甚至直接使用云厂商推出的 SaaS层大数据相关产品(aws的redshift, 阿里云的maxcompute等)。现在“上云”有一点趋势需要强调下,就是大家都很重视不 vendor-lockin,底层的云可能是多个公有云和私有的的融合的 hybrid-cloud;
二是云计算厂商在不断推出自己基于大数据的各种增值服务:为了提高自己的市场竞争力,以进一步巩固/拓宽自己的市场地位,各大云厂商也在积极推出自己整合的大数据相关产品,有最基础的 s3/oss, emr/e-mapreduce,有上文的aws redshift, 阿里云的maxcompute,除此之外,还有各种云上数据库,云上 serverless 形态的各种大数据服务等等,这个名单还在不断增长中,以下截图可见一斑:


三是各传统大数据厂商已经转向依托云来提供自己的产品和服务:如 elastic 很早就开始基于云交付自己的elk 技术栈了,如databricks的大数据平台和产品一直都是基于云来向客户提供服务的(可以对接aws, gcp, azure等云平台),如 cloudera 不断探索改变自己的商业模式(从大数据三驾马车的辉煌期,到业绩下滑下的和 hortorworks的合并,再到主动改变商业模式基于云来交付自己的产品和服务,甚至数据中心版的大数据平台都改名为了 cdp private cloud base);

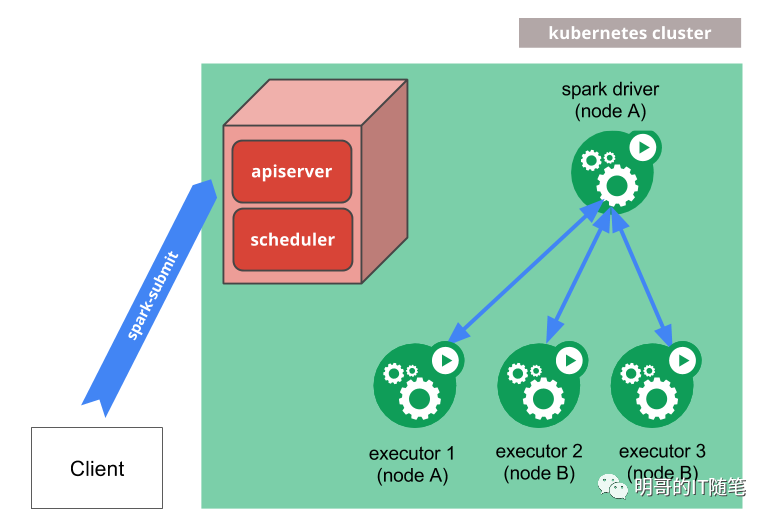
四是各个具体的大数据组件都在主动改变自身架构,积极向云原生靠拢以“云化”:从理念层面讲,大数据已经从最早的强调“数据本地性”和“移动数据不如移动计算”的理念,演进到了现在的强调“存储计算分离”的理念。各个新推出的组件和框架主动拥抱云原生,如pulsa,TiDB等都是依托于存储计算分离的云原生架构; 各个传统的组件虽然有历史包袱,也在不断求新求变,如flink/spark都深度整合支持了kubernetes集群模式;如kafka也在不断探索如花云化:包括完全去掉zookeeper依赖,包括Rebalance Protocol的 Static Membership等;正如古语所言,“顺则昌不顺则亡”,一些不适应云原生架构的技术组件,其市场正在不断萎缩,如很多场景下,kubernetes都替代了yarn, 对象存储oss/s3等也在替代hdfs (我们也注意到了apache 社区推出的Ozone,该组件在对象存储的基础上,也融合推出了文件系统api,该组件的背后有很多原hdfs社区的committer在贡献代码,在cloudera的cdp平台中也内嵌支持了该组件)。下图展示了flink/spark跟kubernetes的深度整合:(注意不是简单的使用k8s operator将spark/flink作业运行在k8s集群中,而是native的深度的整合)
参考链接
http://spark.apache.org/docs/latest/running-on-kubernetes.html
https://ci.apache.org/projects/flink/flink-docs-release-1.12/deployment/resource-providers/native_kubernetes.html
https://aws.amazon.com/
https://www.confluent.io/blog/kafka-rebalance-protocol-static-membership/