













从论文到手机,这个团队正在「一键实现」越来越多的好玩特效。
这几年,AI 模型在特效方向的技能似乎已被拉满。因此,我们在有生之年见到了会说话的蒙娜丽莎、cos 油画的周杰伦以及可以让人一秒变秃的「东升发型生成器」。但是,这些技术似乎在使用层面都不太「接地气」,很少有人将其做成「一键生成」类应用放到手机上,实时类应用就更少了。
到了 2021 年,这种局面正在发生变化。
在一款短视频应用上,我们惊喜地看到,最近火遍全网的「深度怀旧」、「照片唱歌」都已经可以一键生成了:

这些特效都来自腾讯微视,用户只需要下载微视 APP,上传一张照片就可以得到想要的特效效果。其中,「会动的老照片」可以完成老照片上色、超分辨率、让照片中的人物动起来等效果;而「让照片唱首歌」可以让任意照片中的人演唱一首曲目,还搭配丰富的面部表情。
不过,这还只是微视实现的众多特效之一,还有更多特效可以在微视 APP 实时体验,如变明星、变欧美、变娃娃等。

此外,你还可以通过手机实时控制生成图像的面部动作,实现人脸动作迁移:
这些实时特效就像一面又一面的「魔镜」,可以实现各种奇妙的人脸魔法特效。而且玩法非常简单,只需要在 APP 中找到相应模板,然后打开摄像头拍摄即可。
也许有人会问:论文都出来那么久了,怎么现在才在手机上看到这些效果?这就不得不提把 AI 模型从论文搬上手机的那些难处了。
把特效搬上手机难在哪儿?
我们知道,近年来兴起的很多 AI 特效都是基于 GAN(生成对抗网络)的,上文中的大部分特效也不例外。但是,传统的 GAN 往往存在以下问题:
1.需要大量的训练数据。数据对 AI 模型的重要性不言而喻,但对于一些基于 GAN 的人脸特效来说,模型不光需要数据,还需要大量的成对数据,这给数据采集工作带来了新的挑战。比如,在变换人种的特效中,我们不可能同时拥有一个人作为不同人种的图片。
2.可控性差。我们在应用 GAN 生成人脸的时候可能会希望单独调整某个属性,其他属性保持不变,如只把眼睛放大。但麻烦的是,图像的信息被压缩在一个维度很小的隐向量空间中,各个属性耦合十分紧密。因此,如何实现这些属性的解耦、提高人脸属性的可控性就成了一个难题。
3.生成质量不稳定。由于输入数据的质量和生成模型本身的不稳定性,GAN 模型生成的图像画质可能较低,因此我们还需要采取其他措施来提高生成图像的质量。
4.计算量大,难以部署在移动端。一个拥有强大生成能力的 GAN 可能计算量要达到上百 G,不适合在移动端部署。因此,如何在不明显损失视觉效果的前提下实现模型的高效压缩成了一个亟待解决的问题。
这些挑战如何克服?
针对上述挑战,腾讯微视的技术团队研发出了一套支持移动端实时特效的 GAN 模型训练和部署框架,整体流程可以概括为以下几个步骤:
按需求采集非成对数据,并训练高参数量的模型生成成对数据;
对成对数据进行画质增强;
利用成对数据训练移动端轻量化模型。
借助这些步骤,模型不需要真实的成对数据也能达到预期的效果,可控性、生成图像的质量都得到了显著提升,还适配各种机型,让更多人用上了简单、高质量的人脸魔法特效。
利用高参数量模型生成成对数据
当成对的数据难以获得,利用高参数量的大模型生成成对数据就成了一个必然选择。生成效果如下图:

为了完成这项任务,微视的技术团队研发了三种不同的大模型。
第一种是融合了CycleGAN 和 StyleGAN 的 Cycle-StyleGAN。StyleGAN 拥有强大的高清人脸生成能力,但它是非条件生成模型,只能通过随机向量生成随机人脸。因此,研究人员引入了 CycleGAN 的思想,使模型具备 image-to-image 的条件生成能力。
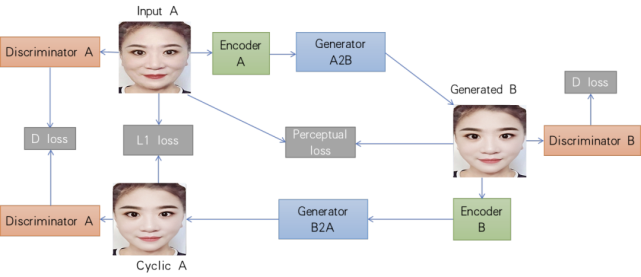
Cycle-StyleGAN 的基本结构。
借助这一模型设计,微视研发并上线了变年轻的效果:

但这一模型也有缺点:需要的数据量太大,而且稳定性、可控性都不强。因此,微视又研发了第二种大模型:基于隐向量的属性编辑模型。
首先,他们利用亚洲人脸数据集训练了一个高质量的生成模型。该模型通过 AdaIN 模块来提取隐向量的信息,然后利用 Decoder 网络来生成数据。为了解决数据解耦问题,实现单属性可控(如只调节眼睛大小),团队做出了以下优化:
对方向向量进行解耦,摸索出了一套有效的属性解耦方法;
在训练的过程中,通过监督信息控制隐向量的具体意义,比如限定某些维度控制鼻型,某些维度控制脸型。
通过以上操作,团队实现了对大部分属性的单独控制,但眼袋、鱼尾纹等过于细致的属性依旧无法做到干净的解耦。为此,团队开发出了一套基于风格空间的属性编辑方法。此外,团队还针对真实数据与训练数据之间的差异所导致的模糊、噪声等问题进行了优化。
整体来看,第二代大模型不仅提高了模型可控性,还大大减少了数据需求量,可以在只能收集到少量非成对数据的真实人脸生成场景中使用。基于这套方案,微视研发并上线了变明星和变假笑等效果。

然而,现实中的人脸特效需求并不局限于真实人脸,还有一些风格化的需求需要满足,如 CG 人脸生成。这类任务的数据匮乏程度更为严重,因此需要一种数据量需求更小的模型。为此,微视的团队设计了第三种大模型——基于小样本的模型融合模型。这种模型的主要思想是:在收集的少量数据上对预训练的真实人脸模型进行调优训练,使预训练模型能够较好地生成目标风格的图片(如 CG 风格图)。然后,将调优训练后的模型与原始模型进行融合得到一个混合模型,该模型既能生成目标风格的图片,又兼具原始预训练模型强大多样的生成能力。

CG 效果图。
为了增加数据的多样性,研发人员还给该模型加了一个数据增强模块,借助 3D 人脸等技术生成更加多样的数据。借助这一模型,只需要几十张数据就能生成符合要求的人脸。
成对数据画质增强
在迭代了三种大模型之后,小模型训练所需的成对数据已经基本就绪,但还需要在美观程度、稳定性和清晰度等方面进行优化。在美观程度方面,微视利用图像处理技术和属性编辑方案对大模型生成的图片进行美化,如利用去皱纹模型去除眼袋和泪沟。在稳定性和清晰度方面,微视参考图像修复和超分辨率的相关方法单独训练了一个既能提升清晰度又能消除人脸瑕疵的 GAN 模型。随机调研的结果显示,用户对美化后的图片的喜爱程度明显提高。

去眼袋和泪沟效果示意图。
移动端小模型训练
在手机上部署的特效对算法的实时性、稳定性要求都很高,因此微视的团队设计了能在移动端流畅运行的小模型结构,把大模型生成的成对数据作为小模型训练的监督信息进行训练和蒸馏。
轻量级的小模型整体骨干基于 Unet 结构,参考了 MobileNet 深度可分离卷积和 ShuffleNet 的特征重利用等优点。为了提高生成图像的清晰度和整体质量,研究团队不仅将整张图放进判别器进行训练,还根据人脸点位裁剪出眼、眉、鼻、嘴,并将其分别输入到判别器进行训练。
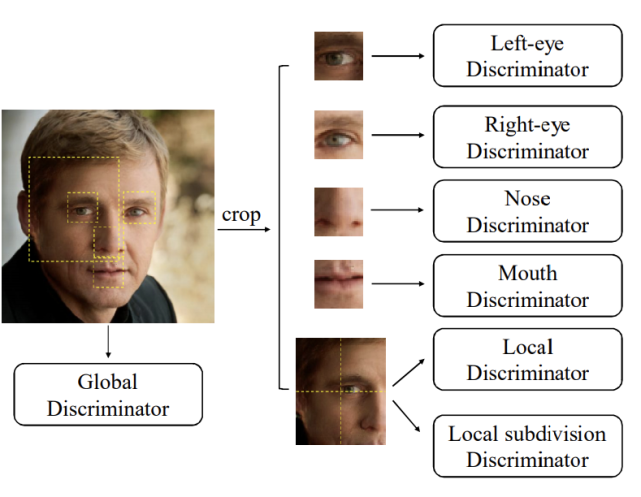
为了适配不同机型,团队设计了多种计算量的模型。而且,考虑到低端机部署的模型参数量较少,他们还用到了知识蒸馏的方法让 student 小模型学习到更多的信息。
以上三大步骤帮助微视实现了 image-to-image 的实时特效生成效果,但团队并没有止步于此,他们还实现了实时的轻量化人脸动作迁移。
实时人脸动作迁移
在人脸动作迁移方向,有一部分工作的思路是:首先估计从目标图片到源图片的反向光流,基于光流对源图片的特征表示进行扭曲(warping)操作,然后再恢复出重建结果,例如 Monkey-Net、FOMM 等。微视的实时人脸动作迁移大模型就借鉴了此类方法。
为了实现手机端实时推断,他们在模型大小和计算量两个方面对大模型进行了优化,借鉴 GhostNet 分别设计了相应的小模型结构,从而将模型大小缩减了 99.2%,GFLOPs 降低了 97.7%。为了让小模型成功学到大模型的能力,他们还采用了分阶段蒸馏训练的策略。
训练完小模型之后,团队借助腾讯自己研发的移动端深度学习推理框架 TNN实现了手机端的部署和实时推理,从而使得用户通过摄像头驱动任意人脸图片的玩法变为可能。
做特效,腾讯微视优势在哪儿
逼真的效果、高效的模型离不开坚实的技术支撑。这些项目的核心技术由腾讯微视拍摄算法团队与腾讯平台与内容事业群(PCG)应用研究中心(Applied Research Center,ARC)共同研发。腾讯微视拍摄算法团队致力于图像 / 视频方向的技术探索,汇聚了一批行业内顶尖的算法专家和产品经验丰富的研究员和工程师,拥有丰富的业务场景,持续探索前沿 AI 和 CV 算法在内容生产和消费领域的应用和落地。ARC 则是 PCG 的侦察兵和特种兵,主要任务是探索和挑战智能媒体相关的前沿技术,聚焦于音视频内容的生成、增强、检索和理解等方向。
在 AI 特效落地方面,团队建立了以下优势:
已经搭建了从算法研发、模型迭代到线上部署的一整套流程化框架,可以实现各项技术的快速落地,为探索更多特效提供了效率保证;
算法经过了多次迭代,数据需求量已经降至很低的水平,几十张图像就能实现不错的效果,使得更多特效的实现成为可能;
在图像质量提升、模型压缩等方面积累了一些自己的技术,可以保障 AI 模型在各种移动端平台上成功部署。
除了上面讨论的 GAN 之外,研发团队在增强现实、3D 空间理解等方面也做了一些探索,并在微视 APP 上上线了一批特效,这也是当前整个社区比较热门的研究方向。
随着技术的不断迭代,未来,我们还将在微视上看到更多原本只能在论文中看到的惊艳效果。



















