一、问题描述
如何在内核中操作某个文件?
问题
二、操作函数
1. 分析
在用户态,读写文件可以通过read和write这两个系统调用来完成(C库函数实际上是对系统调用的封装)。但是,在内核态没有这样的系统调用,我们又该如何读写文件呢?
阅读Linux内核源码,可以知道陷入内核执行的是实际执行的是sys_read和sys_write这两个函数,但是这两个函数没有使用EXPORT_SYMBOL导出,也就是说其他模块不能使用。
在fs/open.c中系统调用具体实现如下(内核版本3.14):
- SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
- {
- if (force_o_largefile())
- flags |= O_LARGEFILE;
- return do_sys_open(AT_FDCWD, filename, flags, mode);
- }
跟踪do_sys_open()函数,
- long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
- {
- struct open_flags op;
- int fd = build_open_flags(flags, mode, &op);
- struct filename *tmp;
- if (fd)
- return fd;
- tmp = getname(filename);
- if (IS_ERR(tmp))
- return PTR_ERR(tmp);
- fd = get_unused_fd_flags(flags);
- if (fd >= 0) {
- struct file *f = do_filp_open(dfd, tmp, &op);
- if (IS_ERR(f)) {
- put_unused_fd(fd);
- fd = PTR_ERR(f);
- } else {
- fsnotify_open(f);
- fd_install(fd, f);
- }
- }
- putname(tmp);
- return fd;
- }
就会发现它主要使用了do_filp_open()函数该函数在fs/namei.c中,
- struct file *do_filp_open(int dfd, struct filename *pathname,
- const struct open_flags *op)
- {
- struct nameidata nd;
- int flags = op->lookup_flags;
- struct file *filp;
- filp = path_openat(dfd, pathname, &nd, op, flags | LOOKUP_RCU);
- if (unlikely(filp == ERR_PTR(-ECHILD)))
- filp = path_openat(dfd, pathname, &nd, op, flags);
- if (unlikely(filp == ERR_PTR(-ESTALE)))
- filp = path_openat(dfd, pathname, &nd, op, flags | LOOKUP_REVAL);
- return filp;
- }
该函数最终打开了文件,并返回file类型指针。所以我们只需要找到其他调用了do_filp_open()函数的地方,就可找到我们需要的文件操作函数。
而在文件fs/open.c中,filp_open函数也是调用了file_open_name函数,
- /**
- * filp_open - open file and return file pointer
- *
- * @filename: path to open
- * @flags: open flags as per the open(2) second argument
- * @mode: mode for the new file if O_CREAT is set, else ignored
- *
- * This is the helper to open a file from kernelspace if you really
- * have to. But in generally you should not do this, so please move
- * along, nothing to see here..
- */
- struct file *filp_open(const char *filename, int flags, umode_t mode)
- {
- struct filename name = {.name = filename};
- return file_open_name(&name, flags, mode);
- }
- EXPORT_SYMBOL(filp_open);
函数file_open_name调用了do_filp_open,并且接口和sys_open函数极为相似,调用参数也和sys_open一样,并且使用EXPORT_SYMBOL导出了,所以在内核中可以使用该函数打开文件,功能非常类似于应用层的open。
- /**
- * file_open_name - open file and return file pointer
- *
- * @name: struct filename containing path to open
- * @flags: open flags as per the open(2) second argument
- * @mode: mode for the new file if O_CREAT is set, else ignored
- *
- * This is the helper to open a file from kernelspace if you really
- * have to. But in generally you should not do this, so please move
- * along, nothing to see here..
- */
- struct file *file_open_name(struct filename *name, int flags, umode_t mode)
- {
- struct open_flags op;
- int err = build_open_flags(flags, mode, &op);
- return err ? ERR_PTR(err) : do_filp_open(AT_FDCWD, name, &op);
- }
2. 所有操作函数
使用同样的方法,找出了一组在内核操作文件的函数,如下:
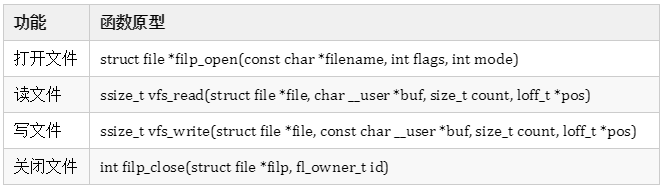
这些函数的参数非常类似于应用层文件IO函数,open、read、write、close。
3. 用户空间地址
虽然我们找到了这些函数,但是我们还不能直接使用。
因为在vfs_read和vfs_write函数中,其参数buf指向的用户空间的内存地址,如果我们直接使用内核空间的指针,则会返回-EFALUT。
这是因为使用的缓冲区超过了用户空间的地址范围。一般系统调用会要求你使用的缓冲区不能在内核区。这个可以用set_fs()、get_fs()来解决。
在include/asm/uaccess.h中,有如下定义:
- #define MAKE_MM_SEG(s) ((mm_segment_t) { (s) })
- #define KERNEL_DS MAKE_MM_SEG(0xFFFFFFFF)
- #define USER_DS MAKE_MM_SEG(PAGE_OFFSET)
- #define get_ds() (KERNEL_DS)
- #define get_fs() (current->addr_limit)
- #define set_fs(x) (current->addr_limit = (x))
如果使用,可以按照如下顺序执行:
- mm_segment_t fs = get_fs();
- set_fs(KERNEL_FS);
- //vfs_write();
- //vfs_read();
- set_fs(fs);
详解:系统调用本来是提供给用户空间的程序访问的,所以,对传递给它的参数(比如上面的buf),它默认会认为来自用户空间,在read或write()函数中,为了保护内核空间,一般会用get_fs()得到的值来和USER_DS进行比较,从而防止用户空间程序“蓄意”破坏内核空间。
而现在要在内核空间使用系统调用,此时传递给read或write()的参数地址就是内核空间的地址了,在USER_DS之上(USER_DS ~ KERNEL_DS),如果不做任何其它处理,在write()函数中,会认为该地址超过了USER_DS范围,所以会认为是用户空间的“蓄意破坏”,从而不允许进一步的执行。
为了解决这个问题, set_fs(KERNEL_DS),将其能访问的空间限制扩大到KERNEL_DS,这样就可以在内核顺利使用系统调用了!
在VFS的支持下,用户态进程读写任何类型的文件系统都可以使用read和write这两个系统调用,但是在linux内核中没有这样的系统调用我们如何操作文件呢?
我们知道read和write在进入内核态之后,实际执行的是sys_read和sys_write,但是查看内核源代码,发现这些操作文件的函数都没有导出(使用EXPORT_SYMBOL导出),也就是说在内核模块中是不能使用的,那如何是好?
通过查看sys_open的源码我们发现,其主要使用了do_filp_open()函数,该函数在fs/namei.c中,而在改文件中,filp_open函数也是间接调用了do_filp_open函数,并且接口和sys_open函数极为相似,调用参数也和sys_open一样,并且使用EXPORT_SYMBOL导出了,所以我们猜想该函数可以打开文件,功能和open一样。
三、实例
Makefile
- ifneq ($(KERNELRELEASE),)
- obj-m:=sysopen.o
- else
- KDIR :=/lib/modules/$(shell uname -r)/build
- PWD :=$(shell pwd)
- all:
- $(info "1st")
- make -C $(KDIR) M=$(PWD) modules
- clean:
- rm -f *.ko *.o *.mod.o *.symvers *.cmd *.mod.c *.order
- endif
sysopen.c
- #include <linux/module.h>
- #include <linux/syscalls.h>
- #include <linux/file.h>
- #include <linux/fcntl.h>
- #include <linux/delay.h>
- #include <linux/slab.h>
- #include <linux/uaccess.h>
- MODULE_LICENSE("GPL");
- MODULE_AUTHOR("yikoulinux");
- void test(void)
- {
- struct file *file = NULL;
- mm_segment_t old_fs;
- loff_t pos;
- char buf[64]="yikoulinux";
- printk("test()");
- file = filp_open("/home/peng/open/test.txt\n",O_RDWR|O_APPEND|O_CREAT,0644);
- if(IS_ERR(file)){
- return ;
- }
- old_fs = get_fs();
- set_fs(KERNEL_DS);
- pos = 0;
- vfs_write(file,buf,sizeof(buf),&pos);
- pos =0;
- vfs_read(file, buf, sizeof(buf), &pos);
- printk("buf:%s\n",buf);
- filp_close(file,NULL);
- set_fs(old_fs);
- return;
- }
- static int hello_init(void)
- {
- printk("hello_init \n");
- test();
- return 0;
- }
- static void hello_exit(void)
- {
- printk("hello_exit \n");
- return;
- }
- module_init(hello_init);
- module_exit(hello_exit);
编译:
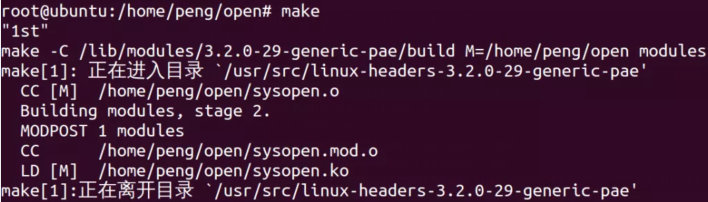
安装模块:
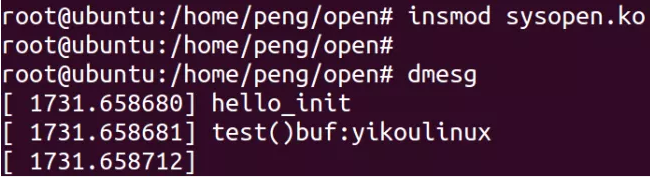
查看操作的文件:

查看文件内容:

可见在内核模块中成功操作了文件。