最近,贾玲导演的电影《你好,李焕英》在春节档一众电影中脱颖而出,成为了一匹黑马,更是中国影史上第三部票房破50亿的电影。

我们从豆瓣上看到,该影片当前评分是8.1分,接近30%的评价都是5颗星。今天我们就来从豆瓣上爬取一部分影评,结合jieba和pyecharts做个分词和词云图。

打开开发者工具
首先,在豆瓣上找到电影《你好,李焕英》,下拉到影评区,可以看到共有三十多万条短评和七千多影评。短评数量太多了,我们还是数量较少的影评下手吧。接下来,在浏览器中按F12或者右键点击检查打开开发者工具,然后选择network(网络)选项,然后点击上图中影评区的“全部7494条”,就可以在开发者工具中看到一系列的请求。
寻找目标URL

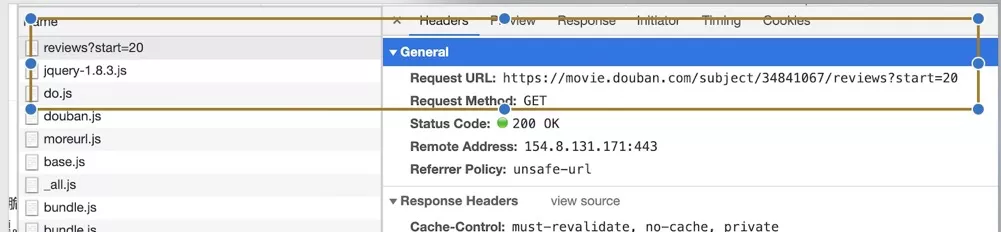
将影评区拖到最底部,将会看到影评被分成来几百个页面,然后我们清空开发者工具中的捕获的请求,点击下一页,在请求列表中找到第一条,这就是我们翻页的通用请求了:每页20条,使用start参数判断起始位置,这样循环300多次就可以获取到全部的影评了。
等等,貌似还少了什么?由于影评内容较长,评论只显示了一部分,要想看到全部内容,还需要点击一下展开全文。

点一下展开,发现浏览器发出一条这样的请求,刚好返回的json就是完整的评论内容。依次点击后面的几条影评,也都是同样格式的请求,只有full前面的数字发生了变化,可以断定这串数字就是这条影评的id了。那么如何知道每一条影评的id是什么呢?
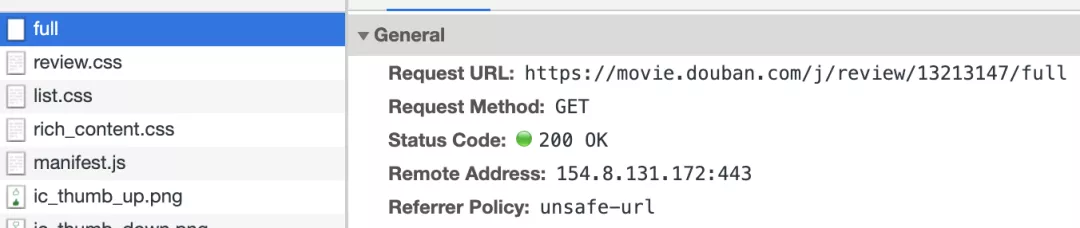
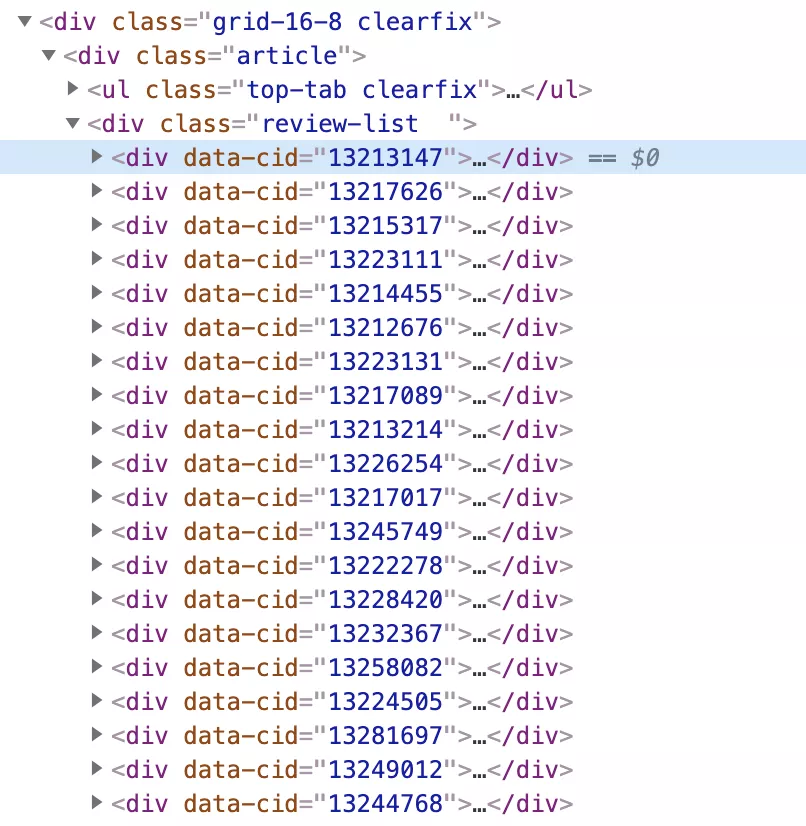
检查目标元素
鼠标放到展开按钮上,右键点击检查元素,我们可以发现,页面上的每一条影评都对应了一个div,这个div有一个data-cid的参数,它的值刚好就是上面我们请求中的id,所以我们只要在每次请求页面时,遍历review-list中所有的div,获取到data-cid的值,再把影评id循环代入到上面的url中请求完整影评内容即可。
爬取完影评评论并保存到本地,然后使用jieba分词将评论文章分割成单词,然后去除停用词并统计词频。
大功告成
最后一步就是利用我们前面提到的pyecharts中的wordcloud来制作词云了。选择一张照片作为词云的形状,然后导入单词及其词频作为权重,输出文件即可。


详细代码:
import requests
import random, time, json
from bs4 import BeautifulSoup as bs
import jieba
import pandas as pd
from pyecharts import charts, options
url1 = 'https://movie.douban.com/subject/34841067/reviews?start={}'
url2 = 'https://movie.douban.com/j/review/{}/full'
header = '''Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Connection: keep-alive
Cookie: bid=RWSCuDu3-hA; douban-fav-remind=1; __gads=ID=f22d1fef6a644a7a-228e1b3a32c50048:T=1607935481:RT=1607935481:S=ALNI_MZwRU5qCsyehoDFgRdf7D5PRBqqCg; ll="108288"; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1614764251%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DlzDNd94NFnBQCDIqNI00Il5NwjZoARpWz1lQy5MGKdL26rV5yrb1N1HIoGzoKu5k%26wd%3D%26eqid%3Dda5556d4000016f000000003603f58d7%22%5D; ap_v=0,6.0; __utmc=30149280; __utmz=30149280.1614764252.6.6.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.1843127241.1614764252.1614764252.1614764252.1; __utmc=223695111; __utmz=223695111.1614764252.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __yadk_uid=rcNjENFDHY62mSmlZqJtXPKJZUfQkM75; _vwo_uuid_v2=D771633F1FBA119FD38FD79DCE082F26D|35b2c7beff079fe25b62163affe94ce8; _pk_id.100001.4cf6=2e0a301ce93b85e0.1614764251.1.1614764408.1614764251.; __utma=30149280.1170719909.1607935481.1614764252.1614766647.7; __utmt=1; __utmb=30149280.2.9.1614766647; dbcl2="152966201:ETujHWfkU2g"; ck=1WtR
Host: movie.douban.com
Referer: https://accounts.douban.com/
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: same-site
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36'''
headers = {x.split(': ')[0]: x.split(': ')[1] for x in header.split('\n')}
session = requests.session()
session.headers = headers
result1 = []
for i in range(0, 365):
print(i)
try:
r = session.get(url1.format(i))
r.close()
content = bs(r.text)
result1.extend(x.get('data-cid') for x in content.select('div.review-list > div'))
except:
pass
time.sleep(random.randrange(3, 20))
result2 = []
for j in result1:
print(result1.index(j))
try:
r = session.get(url2.format(j))
r.close()
data = json.loads(r.text)
result2.append(data)
except:
pass
time.sleep(random.randrange(10, 20))
review = []
for i in result2:
html = bs(i['html'])
review.append(html.text)
for i in ['贾玲', '贾晓玲', '沈腾', '张小斐', '李焕英', '光林', '陈赫', '沈光林', '冷特']:
jieba.add_word(i)
words = []
for x in review:
cut = jieba.lcut(x)
words.extend(cut)
with open('stopwords.txt', 'r')as f:
stop = [x.strip() for x in f.readlines()]
f.close()
df = pd.DataFrame(words, columns=['words'])
df_count = pd.DataFrame(df.groupby('words').size())
count = df_count.loc[[x for x in df_count.index.values if x not in stop]].sort_values(0, ascending=False)
cloud = charts.WordCloud(init_opts=options.InitOpts(width='2000px', height='2000px'))
cloud.add('你好,李焕英',
data_pair=[(x, count.loc[x].values[0] / 100) for x in count.index.values],
mask_image='jialing.jpeg',
word_size_range=[10, 300])
cloud.render('你好李焕英.html')
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.