本文转载自微信公众号「源码兴趣圈」,作者马龙台。转载本文请联系源码兴趣圈公众号。
工作中使用最多的是本地事务,但是在对单一项目拆分为 SOA、微服务之后,就会牵扯出分布式事务场景
文章以分布式事务为主线展开说明,并且针对 2PC、3PC 算法进行详细的讲解,最后通过一个 Demo 来更深入掌握分布式事务,文章目录结构如下
- 什么是事务
- 什么是分布式事务
- DTP 模型和 XA 规范
- 什么是 DTP 模型
- 什么是 XA 规范
- 2PC 一致性算法
- 2PC-准备阶段
- 2PC-提交阶段
- 2PC 算法优缺点
- 3PC 一致性算法
- JDBC 操作 MySQL XA 事务
- 结言
什么是事务
事务是数据库操作的最小工作单元,一组不可再分割的操作集合,是作为单个逻辑工作单元执行的一系列操作。这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行
事务具有四个特征,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),简称为事务的 ACID 特性
如何保证事务的 ACID 特性?
- 原子性(Atomicity):事务内 SQL 要么同时成功要么同时失败,基于撤销日志(undo 日志)实现
- 一致性(Consistency):系统从一个正确态转移到另一个正确态,由应用通过 AID 来保证,可以说是事务的核心特性
- 隔离性(Isolation):控制事务并发执行时数据的可见性,基于锁和多版本并发控制(mvcc)实现
- 持久性(Durability):提交后一定存储成功不会丢失,基于重做日志(redo log)实现
文章主要是介绍分布式事务 2PC 和 3PC,关于 redo、undo 日志、mvcc、锁这块的内容后续再详细介绍
在早些时候,我们应用程序还是单体项目,所以操作的都是单一数据库,这种情况下我们称之为本地事务。本地事务的 ACID 一般都是由数据库层面支持的,比如我们工作中常用的 MySQL 数据库
平常我们在操作 MySQL 客户端时,MySQL 会隐式对事务做自动提交,所以日常工作不会涉及手动书写事务的创建、提交、回滚等操作。如果想要试验锁、MVCC等特性,可以创建多个会话,通过begin、commit、rollback等命令来试验下不同事务之间的数据,看执行结果和自己所想是否一致
我们平常开发项目代码时使用的是 Spring 封装好的事务,所以也不会手动编写对数据库事务的提交、回滚等方法(个别情况除外)。这里使用原生 JDBC 写一个示例代码,帮助大家理解如何通过事务保证 ACID 四大特性
Connection conn = ...; // 获取数据库连接
conn.setAutoCommit(false); // 开启事务
try {
// ...执行增删改查sql
conn.commit(); // 提交事务
} catch (Exception e) {
conn.rollback(); // 事务回滚
} finally {
conn.close(); // 关闭链接
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
设想一下,每次进行数据库操作,都要写重复的创建事务、提交、回滚等方法是不是挺痛苦的,那 Spring 如何自动帮助我们管理事务的呢?Spring 项目中我们一般使用两种方式来进行事务的管理,编程式事务和声明式事务
项目中使用 Spring 管理事务,要么在接口方法上添加注解 @Transactional,要么使用 AOP 配置切面事务。其实这两种方式大同小异,只不过 @Transactional 的粒度更细一些,实现原理上都是依赖 AOP,举例说明下
@Service
public class TransactionalService {
@Transactional
public void save() {
// 业务操作
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
TransactionalService 会被 Spring 创建一个代理对象放入到容器中,创建后的代理对象相当于下述类
public class TransactionalServiceProxy {
private TransactionalService transactionalService;
public TransactionalServiceProxy(TransactionalService transactionalService) {
this.transactionalService = transactionalService;
}
public void save() {
try {
// 开启事务操作
transactionalService.save();
} catch (Exception e) {
// 出现异常则进行回滚
}
// 提交事务
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
示例代码看着简洁明了,但是真正的代码生成代码对比要复杂很多。关于事务管理器,Spring 提供了接口 PlatformTransactionManager,其内部包含两个重要实现类
- DataSourceTransactionManager:支持本地事务,内部通过java.sql.Connection来开启、提交和回滚事务
- JtaTransactionManager:用于支持分布式事务,其实现了 JTA 规范,使用 XA 协议进行两阶段提交
通过这两个实现类得知,平常我们使用的编程式事务和声明式事务依赖于本地事务管理实现,Spring 同时也支持分布式事务,关于 JTA 分布式事务的支持网上资料挺多的,就不在这里赘述了
什么是分布式事务
日常业务代码中的本地事务我们一直都在用,理解起来并不困难。但是随着服务化(SOA)、微服务的流行,平常我们的单一业务系统被拆分成为了多个系统,为了迎合业务系统的变更,数据库也结合业务进行了拆分
比如以学校管理系统举例说明,可能就会拆分为学生服务、课程服务、老师服务等,数据库也拆分为多个库。当这种情况,把不同的服务部署到服务器,就会有可能面临下述的服务调用
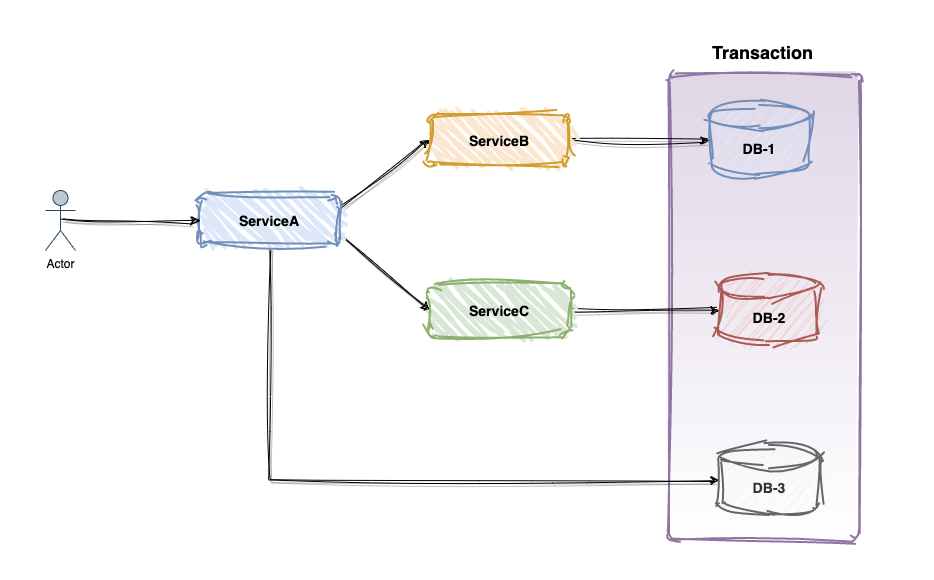
ServiceA 服务需要操作数据库执行本地事务,同时需要调用 ServiceB 和 ServiceC 服务发起事务调用,如何保证三个服务的事务要么一起成功或者一起失败,如何保证用户发起请求的事务 ACID 特性呢?无疑这就是分布式事务场景,三个服务的单一本地事务都无法保证整个请求的事务
分布式事务场景有很多种解决方案,以不同分类来看,强一致性解决方案、最终一致性解决方案,细分其中的方案包括2PC、3PC、TCC、可靠消息...
业界中使用较多的像阿里的 RocketMQ 事务消息、Seata XA模式、可靠消息模型这几种解决方案。不过,分布式事务无一例外都是会直接或间接操作多个数据库,而且使用了分布式事务同时也会带来新的挑战,那就是性能问题。如果为了保证强一致性分布式事务亦或者补偿方案的最终一致性,导致了性能的下降,对于正常业务而言,无疑是得不偿失的
DTP 模型和 XA 规范
X/Open 组织定义了分布式事务的模型(DTP)和 分布式事务协议(XA),DTP 由以下几个模型元素组成
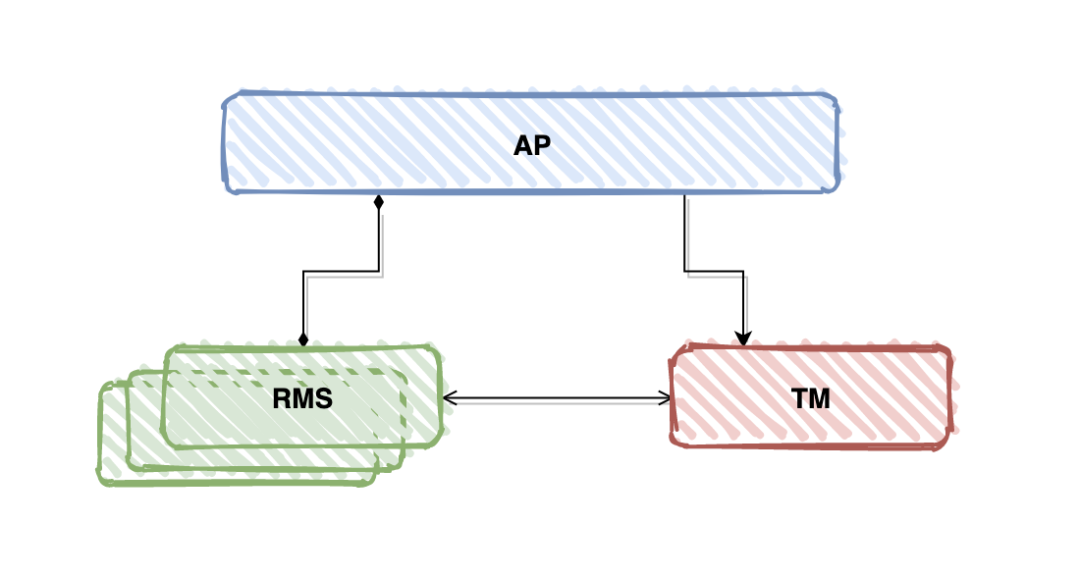
- AP(Application 应用程序):用于定义事务边界(即定义事务的开始和结束),并且在事务边界内对资源进行操作
- TM(Transaction Manager 事务管理器):负责分配事务唯一标识,监控事务的执行进度,并负责事务的提交、回滚等
- RM(Resource Manager 资源管理器):如数据库、文件系统等,并提供访问资源的方式
- CRM(Communication Resource Manager 通信资源管理器):控制一个TM域(TM domain)内或者跨TM域的分布式应用之间的通信
- CP(Communication Protocol 通信协议):提供CRM提供的分布式应用节点之间的底层通信服务
在 DTP 分布式事务模型中,基本组成需要涵盖 AP、TM、RMS(不需要 CRM、CP 也是可以的),如下图所示
XA 规范
XA 规范最重要的作用就是定义 RM(资源管理器)与 TM(事务管理器)之间的交互接口。另外,XA 规范除了定义 2PC 之间的交互接口外,同时对 2PC 进行了优化
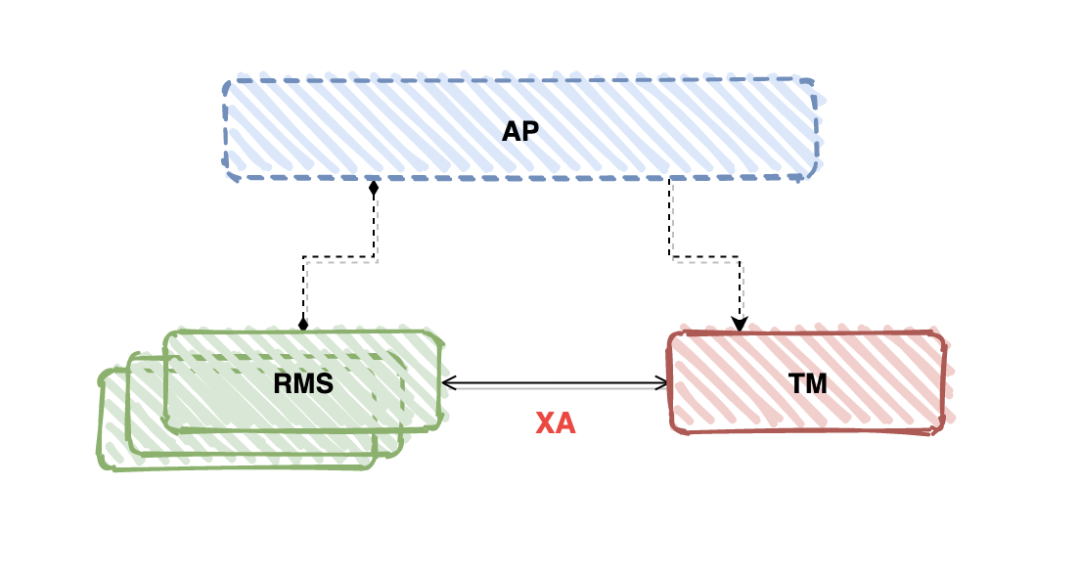
梳理下 DTP、XA、2PC 之间的关系
DTP 规定了分布式事务中的角色模型,并在其中指定了全局事务的控制需要使用 2PC 协议来保证数据的一致性
2PC 是 Two-Phase Commit 的缩写,即二阶段提交,是计算机网络尤其是数据库领域内,为了保证分布式系统架构下所有节点在进行事务处理过程中能够保证原子性和一致性而设计的一种算法。同时,2PC 也被认为是一种一致性协议,用来保证分布式系统数据的一致性
XA 规范是 X/Open 组织提出的分布式事务处理规范,XA 规范定义了 2PC(两阶段提交协议)中需要用到的接口,也就是上图中 RM 和 TM 之间的交互。2PC 和 XA 两者最容易混淆,可以这么理解,DTP 模型定义 TM 和 RM 之间通讯的接口规范叫 XA,然后 关系数据库(比如MySQL)基于 X/Open 提出的的 XA 规范(核心依赖于 2PC 算法)被称为 XA 方案
2PC 一致性算法
当应用程序(AP)发起一个事务操作需要跨越多个分布式节点的时候,每一个分布式节点(RM)知道自己进行事务操作的结果是成功或是失败,但是却不能获取到其它分布式节点的操作结果。为了保证事务处理的 ACID 特性,就需要引入称为"协调者"的组件(TM)来进行统一调度分布式的执行逻辑
协调者负责调度参与整体事务的分布式节点的行为,并最终决定这些分布式节点要把事务进行提交还是回滚。所以,基于这种思想下,衍生出了二阶段提交和三阶段提交两种分布式一致性算法协议。二阶段指的是准备阶段和提交阶段,下面我们先看准备阶段都做了什么事情
2PC-准备阶段
二阶段提交中第一阶段也叫做"投票阶段",即各参与者投票表明自身是否继续执行接下来的事务提交步骤
- 事务询问:协调者向所有参与本次分布式事务的参与者发送事务内容,询问是否可以执行事务提交操作,然后开始等待各个参与者的响应
- 执行事务:参与者收到协调者的事务请求,执行对应的事务,并将内容写入 Undo 和 Redo 日志
- 返回响应:如果各个参与者执行了事务,那么反馈协调者 Yes 响应;如果各个参与者没有能够成功执行事务,那么就会返回协调者 No 响应
如果第一阶段全部参与者返回成功响应,那么进入事务提交步骤,反之本次分布式事务以失败返回。以 MySQL 数据库为例,在第一阶段,事务管理器(TM)向所有涉及到的数据库(RM)发出 prepare(准备提交) 请求,数据库收到请求后执行数据修改和日志记录处理,处理完成后把事务的状态修改为 "可提交",最终将结果返回给事务处理器
2PC-提交阶段
提交阶段分为两个流程,一个是各参与者正常执行事务提交流程,并返回 Yes 响应,表示各参与者投票执行成功;一个是各参与者当中有执行失败返回 No 响应或超时情况,将触发全局回滚,表示分布式事务执行失败
- 执行事务提交
- 中断事务
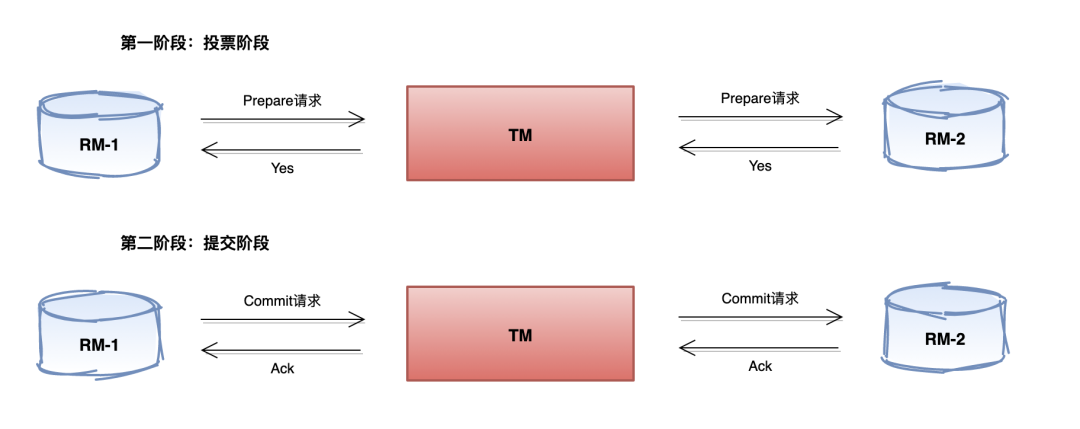
执行事务提交
假设协调者从所有的参与者获得的反馈都是 Yes 响应,那么就会执行事务提交操作
- 事务提交:协调者向所有参与者节点发出 Commit 请求,各个参与者接收到 Commit 请求后,将本地事务进行提交操作,并在完成提交之后释放事务执行周期内占用的事务资源
- 完成事务:各个参与者完成事务提交之后,向协调者发送 Ack 响应,协调者接收到响应后完成本次分布式事务
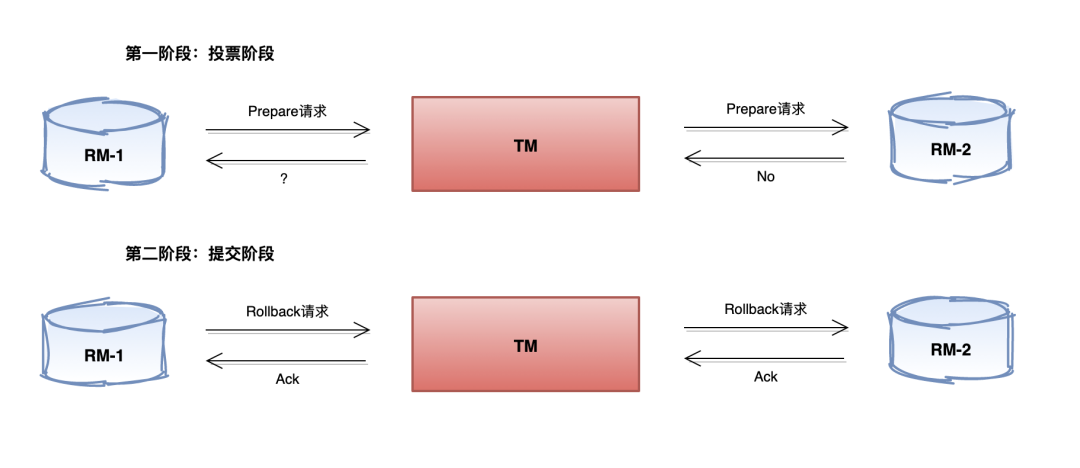
中断事务
假设任意一个事务参与者节点向协调者反馈了 No 响应(注意这里的 No 响应指的是第一阶段),或者在等待超时之后,协调者没有接到所有参与者的反馈响应,那么就会进行事务中断流程
- 事务回滚:协调者向所有参与者发出 Rollback 请求,参与者接收到回滚请求后,使用第一阶段写入的 undo log 执行事务的回滚,并在完成回滚事务之后释放占用的资源
- 中断事务:参与者在完成事务回滚之后,向协调者发送 Ack 消息,协调者接收到事务参与者的 Ack 消息之后,完成事务中断
2PC 优缺点
- 2PC 提交将事务的处理过程分为了投票和执行两个阶段,核心思想就是对每个事务都采用先尝试后提交的方式处理。2PC 优点显而易见,那就是 原理简单,实现方便。简单也意味着很多地方不能尽善尽美,这里梳理三个比较核心的缺陷
- 同步阻塞:无论是在第一阶段的过程中,还是在第二阶段,所有的参与者资源和协调者资源都是被锁住的,只有当所有节点准备完毕,事务协调者才会通知进行全局提交,参与者进行本地事务提交后才会释放资源。这样的过程会比较漫长,对性能影响比较大
- 单点故障:如果协调者出现问题,那么整个二阶段提交流程将无法运转。另外,如果协调者是在第二阶段出现了故障,那么其它参与者将会处于锁定事务资源的状态中
数据不一致性:当协调者在第二阶段向所有参与者发送 Commit 请求后,发生了局部网络异常或者协调者在尚未发送完 Commit 请求之前自身发生了崩溃,导致只有部分参与者接收到 Commit 请求,那么接收到的参与者就会进行提交事务,进而形成了数据不一致性
由于 2PC 的简单方便,所以会产生上述的同步阻塞、单点故障、数据不一致等情况,所以在 2PC 的基础上做了改进,推行出了三阶段提交(3PC)
使用 2PC 存在诸多限制,首先就是数据库需要支持 XA 规范,而且性能与数据一致性数据均不友好,所以 Seata 中虽然支持 XA 模式,但是主推的还是 AT 模式
3PC 一致性算法
三阶段提交(3PC)是二阶段提交(2PC)的一个改良版本,引入了两个新的特性
- 协调者和参与者均引入超时机制,通过超时机制来解决 2PC 的同步阻塞问题,避免事务资源被永久锁定
- 把二阶段演变为三阶段,二阶段提交协议中的第一阶段"准备阶段"一分为二,形成了新的 CanCommit、PreCommit、do Commit 三个阶段组成事务处理协议
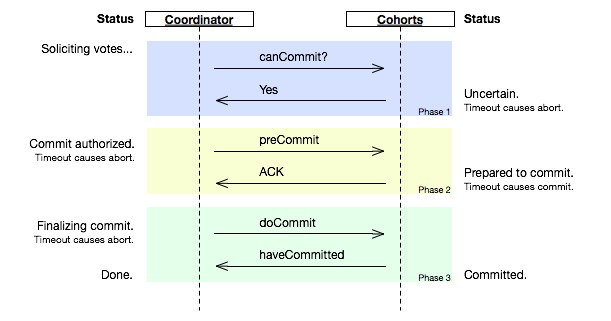
这里将不再赘述 3PC 的详细提交过程,3PC 相比较于 2PC 最大的优点就是降低了参与者的阻塞范围,并且能够在协调者出现单点故障后继续达成一致
虽然通过超时机制解决了资源永久阻塞的问题,但是 3PC 依然存在数据不一致的问题。当参与者接收到 PreCommit 消息后,如果网络出现分区,此时协调者与参与者无法进行正常通信,这种情况下,参与者依然会进行事务的提交
通过了解 2PC 和 3PC 之后,我们可以知道这两者都无法彻底解决分布式下的数据一致性
JDBC 操作 MySQL XA 事务
MySQL 从 5.0.3 开始支持 XA 分布式事务,且只有 InnoDB 存储引擎支持。MySQL Connector/J 从5.0.0 版本之后开始直接提供对 XA 的支持
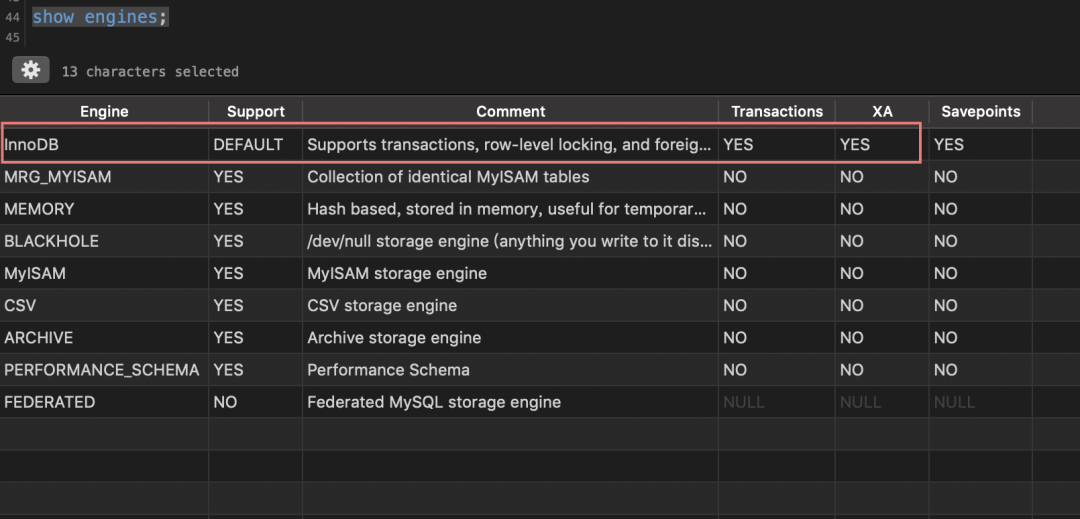
在 DTP 模型中,MySQL 属于 RM 资源管理器,所以这里就不再演示 MySQL 支持 XA 事务的语句,因为它执行的只是自己单一事务分支,我们通过 JDBC 来演示如何通过 TM 来控制多个 RM 完成 2PC 分布式事务
这里先来说明需要引入 GAV 的 Maven 版本,因为高版本 8.x 移除了对 XA 分布式事务的支持(可能也是觉得没人会用吧)
<dependencies>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
</dependencies>
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
这里为了保证在公众号阅读的舒适性,通过 IDEA 将多行代码合并为一行了,如果小伙伴需要粘贴到 IDEA 中,格式化一下就好了
因为 XA 协议的基础是 2PC 一致性算法,所以小伙伴在看代码时可以对照上面文章讲的 DTP 模型和 2PC 来进行理解以及模拟错误和执行结果
import com.mysql.jdbc.jdbc2.optional.MysqlXAConnection;import com.mysql.jdbc.jdbc2.optional.MysqlXid;import javax.sql.XAConnection;import javax.transaction.xa.XAException;import javax.transaction.xa.XAResource;import javax.transaction.xa.Xid;import java.sql.*;
public class MysqlXAConnectionTest {
public static void main(String[] args) throws SQLException {
// true 表示打印 XA 语句, 用于调试
boolean logXaCommands = true;
// 获得资源管理器操作接口实例 RM1
Connection conn1 = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "root");XAConnection xaConn1 = new MysqlXAConnection((com.mysql.jdbc.Connection) conn1, logXaCommands);XAResource rm1 = xaConn1.getXAResource();
// 获得资源管理器操作接口实例 RM2
Connection conn2 = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "root");XAConnection xaConn2 = new MysqlXAConnection((com.mysql.jdbc.Connection) conn2, logXaCommands);XAResource rm2 = xaConn2.getXAResource();
// AP(应用程序)请求 TM(事务管理器) 执行一个分布式事务, TM 生成全局事务 ID
byte[] gtrid = "distributed_transaction_id_1".getBytes();int formatId = 1;
try {
// ============== 分别执行 RM1 和 RM2 上的事务分支 ====================
// TM 生成 RM1 上的事务分支 ID
byte[] bqual1 = "transaction_001".getBytes();Xid xid1 = new MysqlXid(gtrid, bqual1, formatId);
// 执行 RM1 上的事务分支
rm1.start(xid1, XAResource.TMNOFLAGS);PreparedStatement ps1 = conn1.prepareStatement("INSERT into user(name) VALUES ('jack')");ps1.execute();rm1.end(xid1, XAResource.TMSUCCESS);
// TM 生成 RM2 上的事务分支 ID
byte[] bqual2 = "transaction_002".getBytes();Xid xid2 = new MysqlXid(gtrid, bqual2, formatId);
// 执行 RM2 上的事务分支
rm2.start(xid2, XAResource.TMNOFLAGS);PreparedStatement ps2 = conn2.prepareStatement("INSERT into user(name) VALUES ('rose')");ps2.execute();rm2.end(xid2, XAResource.TMSUCCESS);
// =================== 两阶段提交 ================================
// phase1: 询问所有的RM 准备提交事务分支
int rm1_prepare = rm1.prepare(xid1);int rm2_prepare = rm2.prepare(xid2);
// phase2: 提交所有事务分支
if (rm1_prepare == XAResource.XA_OK && rm2_prepare == XAResource.XA_OK) {
// 所有事务分支都 prepare 成功, 提交所有事务分支
rm1.commit(xid1, false);rm2.commit(xid2, false);
} else {
// 如果有事务分支没有成功, 则回滚
rm1.rollback(xid1);rm1.rollback(xid2);
}
} catch (XAException e) { e.printStackTrace(); } }}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
结言
本文通过图文并茂的方式讲解了如何保证本地事务的四大特性,分布式事务的产出背景,以及 2PC、3PC 为何不能解决分布式情况下的数据一致性,最后通过 JDBC 演示了 2PC 的执行流程。相信大家看过后也对分布式事务有了较深的印象,同时对 DTP、XA、2PC 这几种比较容易混淆的概念有了清楚的认识。
这是《分布式事务》专栏的第一章开篇,后面陆续完成通过消息中间件、可靠消息模型、Seata XA模型完成分布式事务的文章,并对不同的实现方式进行总结利弊,挑选出合适场景使用不同的分布式事务解决方案。
作者认为最好的学习方式那就是实战,如果没有接触过分布式事务的小伙伴,可以通过自己正在写的项目,模拟出分布式事务的业务场景,加深印象的同时也能够更好理解分布式事务解决方案相关设计思路。