本文会翻炒一个用途比较广的算法 - 「布隆过滤器算法」。
布隆过滤器的一些概念主要包括:
- 简介
- 算法
- 参数
- 优势和劣势
布隆过滤器简介
布隆过滤器是「一种空间高效概率性的数据结构」(百科中原文是a space-efficient probabilistic data structure),该数据结构于1970年由Burton Howard Bloom提出,「作用是测试一个元素是否某个集合的一个成员」。布隆过滤器是可能出现false positive(这个是专有名词"假阳性",可以理解为误判的情况,下文如果用到这个名词会保留英文单词使用)匹配的,换言之,布隆过滤器在使用的时候有可能返回结果"可能存在于集合中"或者"必定不存在于集合中"。
布隆过滤器算法描述
在场景复杂的网络爬虫中,爬取到的网页URL依赖有可能成环,例如在URL-1页面中展示了URL-2,然后又在URL-2中的页面展示了URL-1,这个时候需要一种方案记录和判断历史访问过的URL。这个时候可能会想到下面的方案:
- 方案一:使用数据库存储已经访问过的URL,例如MySQL表中基于URL建立唯一索引或者使用Redis的SET数据类型
- 方案二:使用HashSet(其实这里不局限于HashSet,链表、树和散列表等数据结构都能满足)存储已经访问过的URL
- 方案三:基于方案一和方案二进行优化,存储URL的摘要,使用摘要算法如MD5、SHA-n算法针对URL字符串生成摘要
- 方案四:使用Hash函数处理对应的URL生成一个哈希码,再把哈希码通过一个映射函数映射到一个固定容量的BitSet中的某一个比特
对于方案一、方案二和方案三,在历史访问URL数据量极大的情况下,会消耗巨大的存储空间(磁盘或者内存),对于方案四,如果URL有100亿个,那么要把冲突几率降低到1%,那么BitSet的容量需要设置为10000亿。
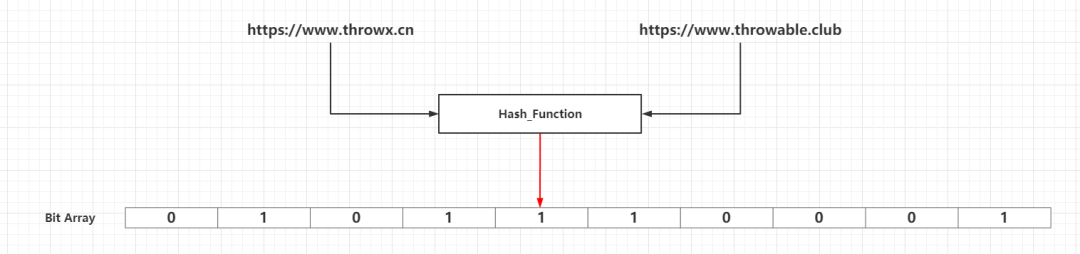
所以上面的四种方案都有明显的不足之处,而布隆过滤器算法的基本思路跟方案四差不多,最大的不同点就是方案四中只提到使用了一个散列函数,而布隆过滤器中使用了k(k >= 1)个相互独立的高效低冲突的散列函数。
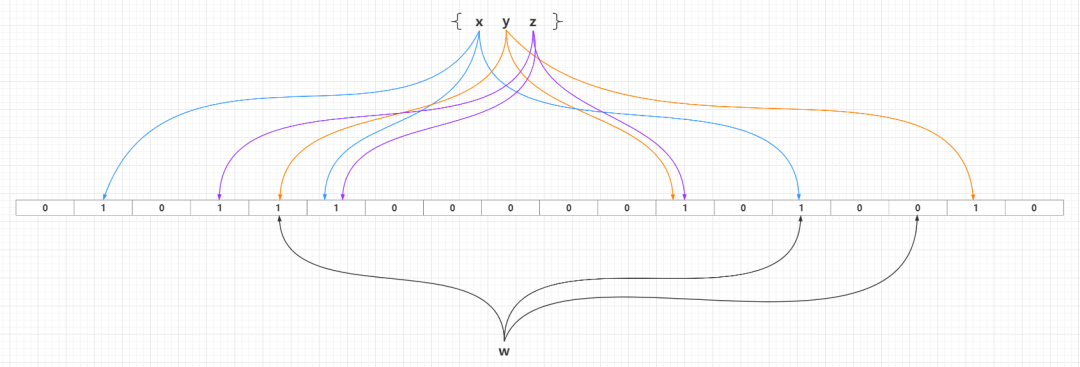
一个初始化的布隆过滤器是一个所有比特都设置为0的长度为m的比特数组,也就是认知中的Bit Array、Bit Set或者Redis中的Bit Map概念。然后需要引入k个不同的散列函数,某个新增元素通过这k个散列函数处理之后,映射到比特数组m个比特中的k个,并且把这些命中映射的k个比特位设置为1,产生一个均匀的随机分布。通常情况下,k的一个较小的常数,取决于所需的误判率,而布隆过滤器容量m与散列函数个数k和需要添加元素数量呈正相关。
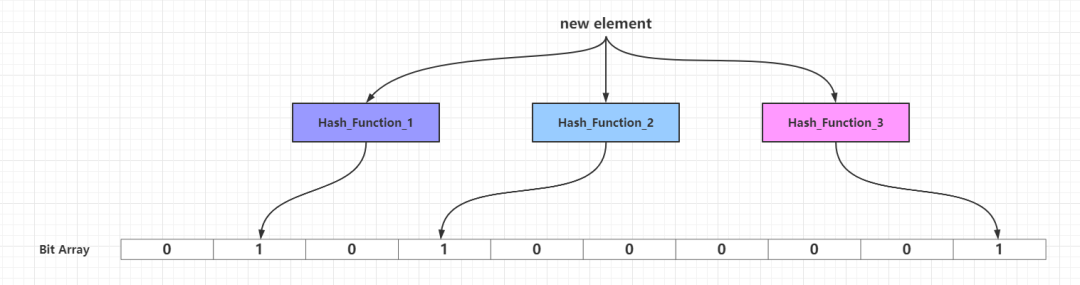
当需要新增的所有元素都添加到布隆过滤器之后,那么比特数组中的很多比特都被设置为1。这个时候如果需要判断一个元素是否存在于布隆过滤器中,只需要通过k个散列函数处理得到比特数组的k个下标,然后判断比特数组对应的下标所在比特是否为1。如果这k个下标所在比特中「至少存在一个0,那么这个需要判断的元素必定不在布隆过滤器代表的集合中」;如果这k个下标所在比特全部都为1,那么那么这个需要判断的元素「可能存在于」布隆过滤器代表的集合中或者刚好是一个False Positive,至于误差率分析见下文的「布隆过滤器的相关参数」一节。False Positive出现的情况可以见下图:
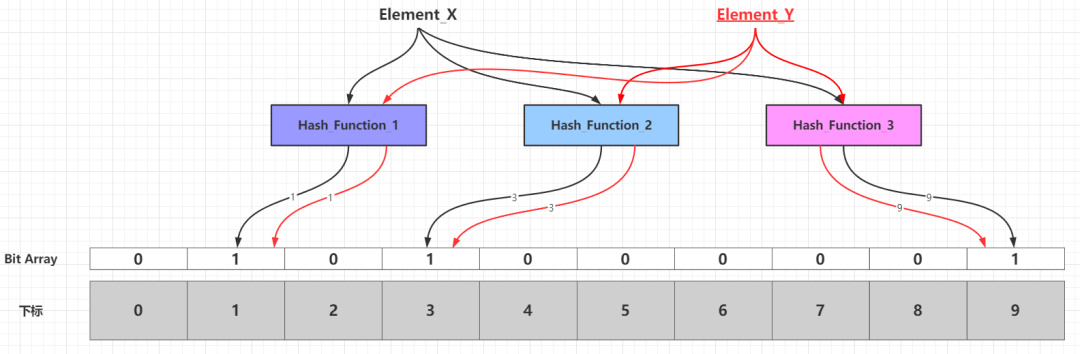
当添加到布隆过滤器的元素数量比较大,并且布隆过滤器的容量设置不合理(过小),容易出现多个元素通过k个散列函数,映射到相同的k个位(如上图的下标1、3、9所在的位),这个时候就无法准确判断这k个位由具体那个元素映射而来。其实可以极端一点思考:假设布隆过滤器容量为24,散列函数只有一个,那么添加最多25个不同元素,必定有两个不同的元素的映射结果落在同一个位。
布隆过滤器的相关参数
在算法描述一节已经提到过,布隆过滤器主要有下面的参数:
初始化比特数组容量m
散列函数个数k
误判率ε(数学符号Epsilon,代表False Positive Rate)
需要添加到布隆过滤器的元素数量n
考虑到篇幅原因,这里不做这几个值的关系推导,直接整理出结果和关系式。
误判率ε的估算值为:[1 - e^(-kn/m)]^k
最优散列函数数量k的推算值:对于给定的m和n,当k = m/n * ln2的时候,误判率ε最低
推算初始化比特容量m的值,当k = m/n * ln2的时候,m >= n * log2(e) * log2(1/ε)
这里贴一个参考资料中m/n、k和False Positive Rate之间的关系图:
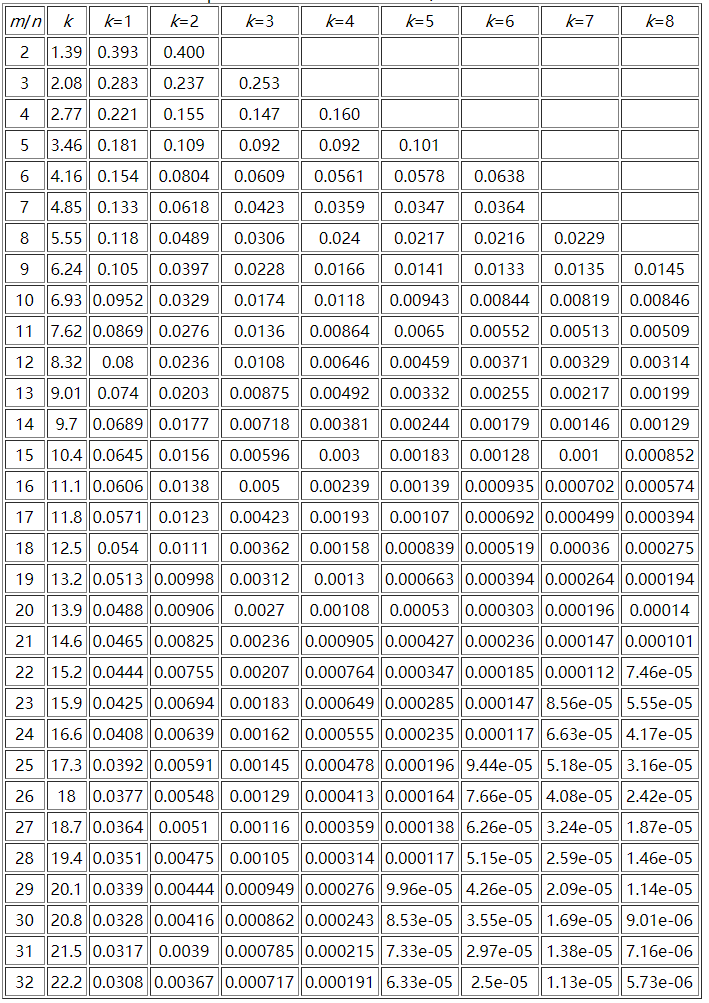
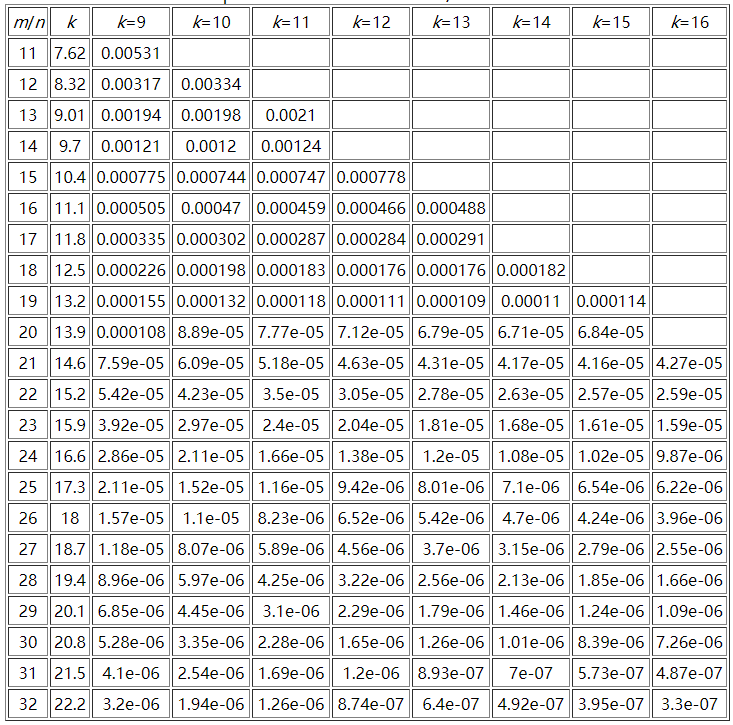
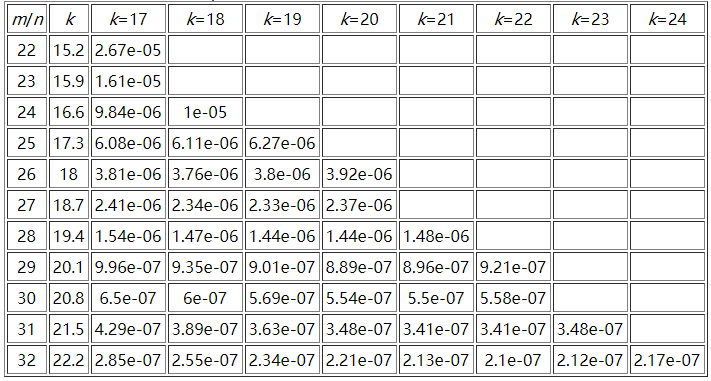
这里可以推算一下表格中最大参数所需要的空间极限,假设n为10亿,m/n = 32,那么m为320亿,而k为24,此时的误判率为2.17e-07(0.000000217),需要空间3814.69727m。一般规律是:
当k固定的时候,m/n越大,误判率越小
当m/n固定的时候,k越大,误判率越大
通常情况下,k需要固定,而n是无法确定准确值,最好要评估增长趋势预先计算一个比较大的m值去降低误判率,当然也要权衡m值过大导致空间消耗过大的问题。
既然参数的关系式都已经有推导结果,可以基于关系式写一个参数生成器:
import java.math.BigDecimal;
import java.math.RoundingMode;
public class BloomFilterParamGenerator {
public BigDecimal falsePositiveRate(int m, int n, int k) {
double temp = Math.pow(1 - Math.exp(Math.floorDiv(-k * n, m)), k);
return BigDecimal.valueOf(temp).setScale(10, RoundingMode.FLOOR);
}
public BigDecimal kForMinFalsePositiveRate(int m, int n) {
BigDecimal k = BigDecimal.valueOf(Math.floorDiv(m, n) * Math.log(2));
return k.setScale(10, RoundingMode.FLOOR);
}
public BigDecimal bestM(int n, double falsePositiveRate) {
double temp = log2(Math.exp(1) + Math.floor(1 / falsePositiveRate));
return BigDecimal.valueOf(n).multiply(BigDecimal.valueOf(temp)).setScale(10, RoundingMode.FLOOR);
}
public double log2(double x) {
return Math.log(x) / Math.log(2);
}
public static void main(String[] args) {
BloomFilterParamGenerator generator = new BloomFilterParamGenerator();
System.out.println(generator.falsePositiveRate(2, 1, 2)); // 0.3995764008
System.out.println(generator.kForMinFalsePositiveRate(32, 1)); // 22.1807097779
System.out.println(generator.bestM(1, 0.3995764009)); // 2.2382615950
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
这里的计算没有考虑严格的进位和截断,所以和实际的结果可能有偏差,只提供一个参考的例子。
布隆过滤器的优势和劣势
布隆过滤器的优势:
- 布隆过滤器相对于其他数据结构在时空上有巨大优势,占用内存少,查询和插入元素的时间复杂度都是O(k)
- 可以准确判断元素不存在于布隆过滤器中的场景
- 散列函数可以独立设计
- 布隆过滤器不需要存储元素本身,适用于某些数据敏感和数据严格保密的场景
布隆过滤器的劣势:
- 不能准确判断元素必定存在于布隆过滤器中的场景,存在误判率,在k和m固定的情况下,添加的元素越多,误判率越高
- 没有存储全量的元素,对于一些准确查询或者准确统计的场景不适用
- 原生的布隆过滤器无法安全地删除元素
这里留一个很简单的问题给读者:为什么原生的布隆过滤器无法安全地删除元素?(可以翻看之前的False Positive介绍)
布隆过滤器算法实现
著名的Java工具类库Guava中自带了一个beta版本的布隆过滤器实现,这里参考其中的源码实现思路和上文中的算法描述进行一次布隆过滤器的实现。先考虑设计散列函数,简单一点的方式就是参考JavaBean的hashCode()方法的设计:
// 下面的方法来源于java.util.Arrays#hashCode
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
上面方法的31可以作为一个输入的seed,每个散列函数设计一个独立的seed,并且这个seed值选用素数基于字符串中的每个char进行迭加就能实现计算出来的结果是相对独立的:
import java.util.Objects;
public class HashFunction {
/**
* 布隆过滤器容量
*/
private final int m;
/**
* 种子
*/
private final int seed;
public HashFunction(int m, int seed) {
this.m = m;
this.seed = seed;
}
public int hash(String element) {
if (Objects.isNull(element)) {
return 0;
}
int result = 1;
int len = element.length();
for (int i = 0; i < len; i++) {
result = seed * result + element.charAt(i);
}
// 这里确保计算出来的结果不会超过m
return (m - 1) & result;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
接着实现布隆过滤器:
public class BloomFilter {
private static final int[] K_SEED_ARRAY = {5, 7, 11, 13, 31, 37, 61, 67};
private static final int MAX_K = K_SEED_ARRAY.length;
private final int m;
private final int k;
private final BitSet bitSet;
private final HashFunction[] hashFunctions;
public BloomFilter(int m, int k) {
this.k = k;
if (k <= 0 && k > MAX_K) {
throw new IllegalArgumentException("k = " + k);
}
this.m = m;
this.bitSet = new BitSet(m);
hashFunctions = new HashFunction[k];
for (int i = 0; i < k; i++) {
hashFunctions[i] = new HashFunction(m, K_SEED_ARRAY[i]);
}
}
public void addElement(String element) {
for (HashFunction hashFunction : hashFunctions) {
bitSet.set(hashFunction.hash(element), true);
}
}
public boolean contains(String element) {
if (Objects.isNull(element)) {
return false;
}
boolean result = true;
for (HashFunction hashFunction : hashFunctions) {
result = result && bitSet.get(hashFunction.hash(element));
}
return result;
}
public int m() {
return m;
}
public int k() {
return k;
}
public static void main(String[] args) {
BloomFilter bf = new BloomFilter(24, 3);
bf.addElement("throwable");
bf.addElement("throwx");
System.out.println(bf.contains("throwable")); // true
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
这里的散列算法和有限的k值不足以应对复杂的场景,仅仅为了说明如何实现布隆过滤器,总的来说,原生布隆过滤器算法是比较简单的。对于一些复杂的生产场景,可以使用一些现成的类库如Guava中的布隆过滤器API、Redis中的布隆过滤器插件或者Redisson(Redis高级客户端)中的布隆过滤器API。
布隆过滤器应用
主要包括:
- Guava中的API
- Redisson中的API
- 使用场景
使用Guava中的布隆过滤器API
引入Guava的依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1-jre</version>
</dependency>
- 1.
- 2.
- 3.
- 4.
- 5.
使用布隆过滤器:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.StandardCharsets;
public class GuavaBloomFilter {
@SuppressWarnings("UnstableApiUsage")
public static void main(String[] args) {
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.US_ASCII), 10000, 0.0444D);
bloomFilter.put("throwable");
bloomFilter.put("throwx");
System.out.println(bloomFilter.mightContain("throwable"));
System.out.println(bloomFilter.mightContain("throwx"));
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
构造BloomFilter的最多参数的静态工厂方法是BloomFilter
- funnel:主要是把任意类型的数据转化成HashCode,是一个顶层接口,有大量内置实现,见Funnels
- expectedInsertions:期望插入的元素个数
- fpp:猜测是False Positive Percent,误判率,小数而非百分数,默认值0.03
- strategy:映射策略,目前只有MURMUR128_MITZ_32和MURMUR128_MITZ_64(默认策略)
参数可以参照上面的表格或者参数生成器的指导,基于实际场景进行定制。
使用Redisson中的布隆过滤器API
高级Redis客户端Redisson已经基于Redis的bitmap数据结构做了封装,屏蔽了复杂的实现逻辑,可以开箱即用。引入Redisson的依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.15.1</version>
</dependency>
- 1.
- 2.
- 3.
- 4.
- 5.
使用Redisson中的布隆过滤器API:
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379");
RedissonClient redissonClient = Redisson.create(config);
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("ipBlockList");
// 第一个参数expectedInsertions代表期望插入的元素个数,第二个参数falseProbability代表期望的误判率,小数表示
bloomFilter.tryInit(100000L, 0.03D);
bloomFilter.add("127.0.0.1");
bloomFilter.add("192.168.1.1");
System.out.println(bloomFilter.contains("192.168.1.1")); // true
System.out.println(bloomFilter.contains("192.168.1.2")); // false
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
Redisson提供的布隆过滤器接口RBloomFilter很简单:
常用的方法有tryInit()(初始化)、add()(添加元素)和contains()(判断元素是否存在)。相对于Guava的内存态的布隆过滤器实现,Redisson提供了基于Redis实现的「分布式布隆过滤器」,可以满足分布式集群中布隆过滤器的使用。
布隆过滤器使用场景
其实布隆过滤器的使用场景可以用百科中的一张示意图来描述:
基于上图具体化的一些场景列举如下:
- 网站爬虫应用中进行URL去重(不存在于布隆过滤器中的URL必定是未爬取过的URL)
- 防火墙应用中IP黑名单判断(不局限于IP黑名单,通用的黑名单判断场景基本都可以使用布隆过滤器,不存在于布隆过滤器中的IP必定是白名单)
- 用于规避缓存穿透(不存在于布隆过滤器中的KEY必定不存在于后置的缓存中)
布隆过滤器变体
布隆过滤器的变体十分多,主要是为了解决布隆过滤器算法中的一些缺陷或者劣势。常见的变体如下:
| 变体名称 | 变体描述 |
|---|---|
Counting Bloom Filter |
把原生布隆过滤器每个位替换成一个小的计数器(Counter),所谓计数器其实就是一个小的整数 |
Compressed Bloom Filter |
对位数组进行压缩 |
Hierarchical Bloom Filters |
分层,由多层布隆过滤器组成 |
Spectral Bloom Filters |
CBF的扩展,提供查询集合元素的出现频率功能 |
Bloomier Filters |
存储函数值,不仅仅是做位映射 |
Time-Decaying Bloom Filters |
计数器数组替换位向量,优化每个计数器存储其值所需的最小空间 |
Space Code Bloom Filter |
- |
Filter Banks |
- |
Scalable Bloom filters |
- |
Split Bloom Filters |
- |
Retouched Bloom filters |
- |
Generalized Bloom Filters |
- |
Distance-sensitive Bloom filters |
- |
Data Popularity Conscious Bloom Filters |
- |
Memory-optimized Bloom Filter |
- |
Weighted Bloom filter |
- |
Secure Bloom filters |
- |
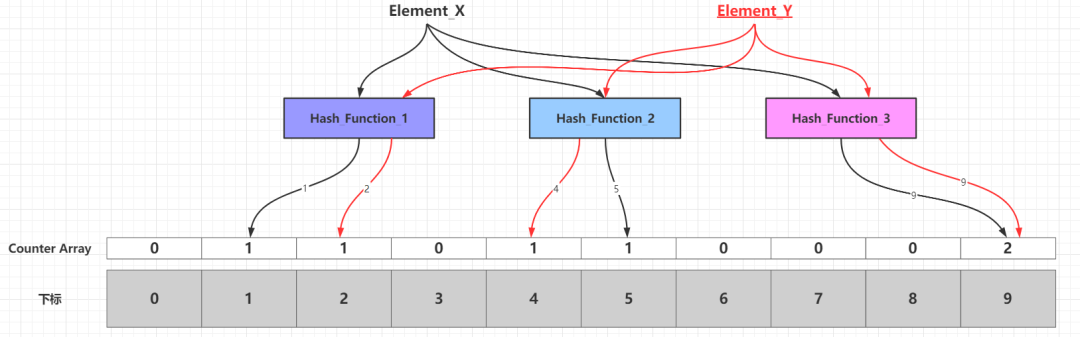
这里挑选Counting Bloom Filter(简称CBF)变体稍微展开一下。原生布隆过滤器的基础数据结构是位向量,CBF扩展原生布隆过滤器的基础数据结构,底层数组的每个元素使用4位大小的计数器存储添加元素到数组某个下标时候映射成功的频次,在插入新元素的时候,通过k个散列函数映射到k个具体计数器,这些命中的计数器值增加1;删除元素的时候,通过k个散列函数映射到k个具体计数器,这些计数器值减少1。使用CBF判断元素是否在集合中的时候:
- 某个元素通过k个散列函数映射到k个具体计数器,所有计数器的值都为0,那么元素必定不在集合中
- 某个元素通过k个散列函数映射到k个具体计数器,至少有1个计数器的值大于0,那么元素可能在集合
小结一句话简单概括布隆过滤器的基本功能:「不存在则必不存在,存在则不一定存在。」
在使用布隆过滤器判断一个元素是否属于某个集合时,会有一定的误判率。也就是有可能把不属于某个集合的元素误判为属于这个集合,这种错误称为False Positive,但不会把属于某个集合的元素误判为不属于这个集合(相对于False Positive,"假阳性",如果属于某个集合的元素误判为不属于这个集合的情况称为False Negative,"假阴性")。False Positive,也就是错误率或者误判率这个因素的引入,是布隆过滤器在设计上权衡空间效率的关键。
参考资料:
- Bloom filter
- Guava相关源码
- Bloom Filters - the math
(本文完 c-1-w e-a-20210306)
本文转载自微信公众号「Throwable」,可以通过以下二维码关注。转载本文请联系Throwable公众号。