为深度学习项目建立一个良好的环境不是一件容易的任务。因为需要处理的事情太多了:库必须匹配特定的版本,整个环境需要可以复制到其他机器上,所有东西都需要能够机器中的所有驱动程序通信。这意味着你需要为你的NVIDIA GPU安装特定的驱动程序,并且CUDA库必须与你的驱动程序和你想要使用的框架兼容。
随着容器彻底改变了软件开发的世界,现在它们也可以帮助数据科学家构建更健壮的环境。
有一件事是肯定的:数据科学可以从软件开发领域学到一些东西。
NVIDIA NGC是一个软件中心,提供gpu优化框架、预训练模型和工具包来培训和部署生产中的AI。它是一个容器注册中心,包含训练模型所需的所有工具:无论您使用的是caffee2、Pytorch、Tensorflow、Keras、Julia还是其他工具都没有关系。
在NGC目录中有大量可生产的容器,你只需要选择你自己想用的。
Nvidia NGC不仅是一个容器注册中心,它还内置了许多功能,可以帮助您的组织将模型带到生产环境中。
从头开始
让我们从一台配备了GPU的Linux机器开始(GPU不是强制性的,但如果你想训练模型,强烈建议使用GPU)。我在Ubuntu 20.04 LTS和18.04 LTS上测试了这个功能,但是可以很容易地适应其他Linux发行版。
我们需要做什么?
步骤很简单,我们只需要安装NVIDIA驱动程序和Docker。然后我们下载我们想要的docker镜像并开始工作!
第一步:在Ubuntu 20.04上安装NVIDIA驱动程序
注意:如果你使用的是另一个Ubuntu版本,请确保你修改了相应的脚本。此外,如果启用了Secure Boot,这种方法也不起作用。
sudo apt install linux-headers-$(uname -r)
curl -O https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
sudo apt-key adv - fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/7fa2af80.pub
sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/ /"
sudo apt update
sudo apt -y install cuda
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
使用nvidia-smi命令验证安装。你应该看到这样的东西。
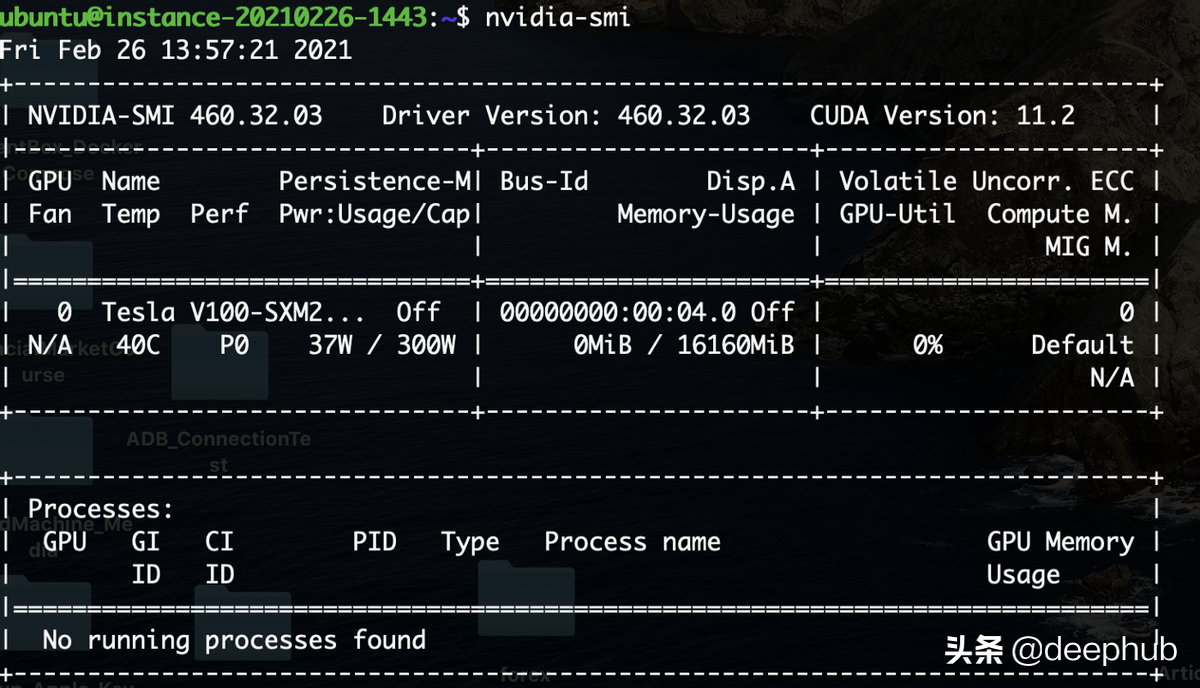
第二步:在Ubuntu 20.04中安装Docker
#!/bin/sh
#Set up the repository
sudo apt-get update
sudo apt-get install -y \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
# Add Docker’s official GPG key:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# set up the stable repository
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io
# Substitute ubuntu with your username
sudo usermod -aG docker ubuntu
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
注意:你需要注销和登录,以在没有sudo权限的情况下使用docker命令。
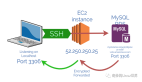
第三步:让Docker与NVIDIA driver通信
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt update
sudo apt-get install -y docker nvidia-container-toolkit
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
我们现在想测试Docker是否能够与NVIDIA驱动程序通信。要做到这一点,只需运行以下命令,您应该会看到与步骤1类似的结果。
sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
- 1.
注意:我在不同的云主机提供商上试验过,根据操作系统、虚拟机类型和gpu,此时可能需要重启。因此,如果出现错误,请尝试sudo reboot并再次执行上述命令。正常的话应该看到nvidia-smi结果。
第四步:让我们获取镜像并运行它!
#Download NGC Tensorflow 2 Image
docker pull nvcr.io/nvidia/tensorflow:20.12-tf2-py3
# create local_dir folder mounted at /container_dir in the container
mkdir /home/ubuntu/local_dir
docker run --gpus all --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 -it --rm -v /home/ubuntu/local_dir:/container_dir nvcr.io/nvidia/tensorflow:20.10-tf2-py3
- 1.
- 2.
- 3.
- 4.
- 5.
注意:flags - shm-size=1g - ulimit memlock=-1 - ulimit stack=67108864是必要的,为了避免操作系统限制资源分配给Docker容器。
我们现在进入了容器,让我们看看是否一切正常。
正如你从图片中看到的,GPU是可用的,tensorflow可以使用它。
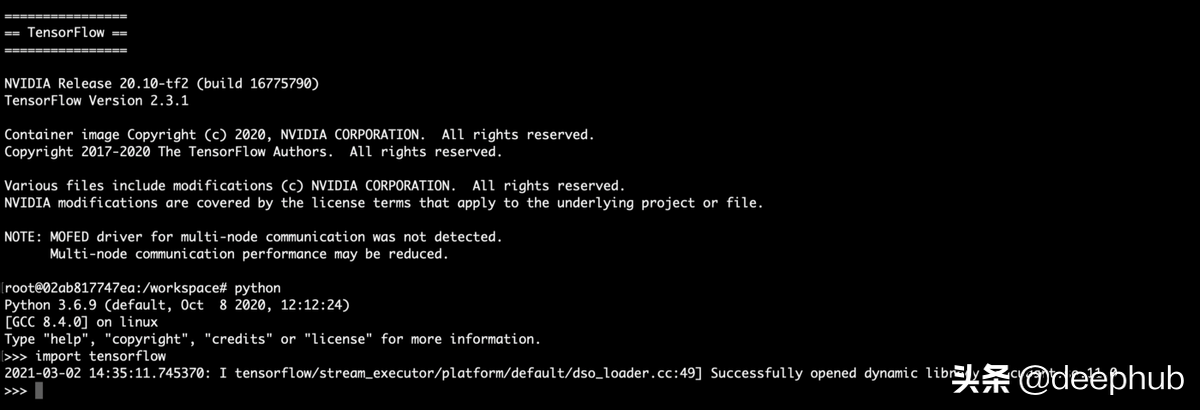
最后:访问docker环境
当您断开与机器的连接时,您将注意到您已经不在容器内了。
要再次连接,你需要使用docker ps找到正在运行的容器的container_ id,然后:
docker exec -it <containerid> /bin/bash</containerid>
- 1.
最后总结
在本教程中,我们发现使用NVIDIA NGC的图像创建一个具有所有库和工具的生产就绪环境是多么容易。
我们看到了配置Docker使其与NVIDIA驱动程序和所需框架通信是多么容易。
我们在5分钟内完成了所有这些工作