本文转载自微信公众号「新智元」,作者新智元。转载本文请联系新智元公众号。
无需标签,自我分析数据!
Facebook的新AI模型在革计算机视觉的命?
刚刚,Facebook宣布了一个在10亿张图片上训练的AI模型——SEER,是自监督(Self-supervised)的缩写。

该模型包含10亿个参数,可以在几乎没有标签帮助的情况下识别图像中的物体,并在一系列计算机视觉基准上取得了先进的结果。
要知道,大多数计算机视觉模型都是从标记的数据集中学习。
而Facebook的最新模型则是通过暴露数据各部分之间的关系从数据中来生成标签。
这一步被认为对有朝一日实现人类终极智能至关重要。
新AI模型SEER在革计算机视觉的命?
参数一直是机器学习系统的基本组成部分,是从历史训练数据中得到的模型的一部分。
人工智能的未来在于是否能够不依赖于带注释的数据集,从给定的任何信息中进行推理。
只要提供文本、图像或其他类型的数据,AI就能够完美地识别照片中的物体、解释文本,或者执行任何要求它执行的其他任务。
Facebook首席科学家Yann LeCun表示,这是构建具有背景知识或「常识」的机器以解决远远超出当今AI任务的最有前途的方法之一。
我们已经看到了自然语言处理(NLP)的重大进步。其中,在大量文本上对超大型模型进行自我监督的预训练在自然语言处理方面取得重大突破。
现在,Facebook声称自家的SEER计算机视觉模型向这个目标迈进了一步。
它可以从互联网上的任何一组随机图像中学习,而不需要进行注释。
对视觉的自我监督是一项具有挑战性的任务。
对于文本,语义概念可以被分解成离散的单词,但是对于图像,模型必须自己推断哪个像素属于哪个概念。
同样的概念在不同的图像之间往往会发生变化,这使得问题变得更具挑战性。因此,要想掌握单个概念的变化,就需要查看大量不同的图像。

研究人员通过instagram的公开的10亿张图片进行模型训练
他们发现,让人工智能系统处理复杂的图像数据至少需要两个核心算法:
一是可以从大量随机图像中学习,无需任何元数据或注释的算法;二是卷积神经网络(ConvNet)足够大,可以从这些数据中捕捉和学习所有视觉概念。
卷积神经网络在20世纪80年代首次提出,受到生物学过程的启发,因为模型中各组成部分之间的连接模式类似于视觉皮层。
SEER:10亿张图,无需标记,自主训练数据集
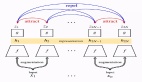
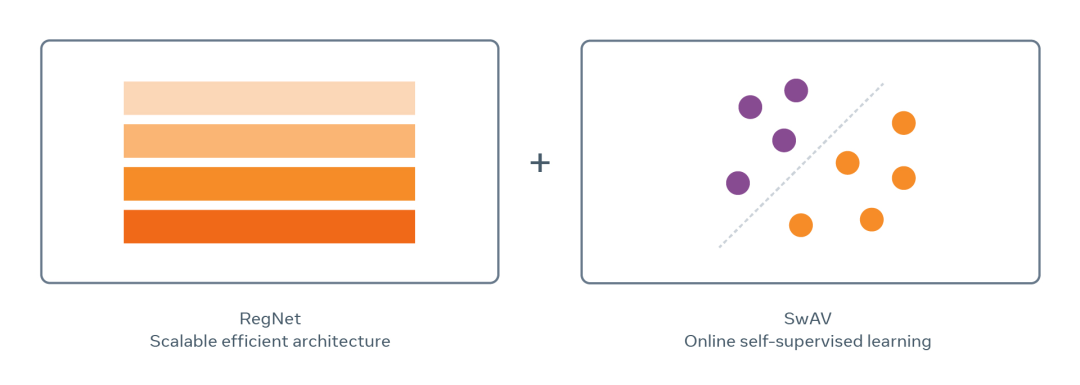
SEER模型结合了最近的架构家族「RegNet」和在线自我监督训练「SwAV」来规模训练数具有10亿参数的数十亿张随机图像。
科研团队改编利用了一种新算法,称为SwAV。它起源于FAIR的研究,后被应用于自我监督学习。
SwAV 使用在线聚类方法来快速分组具有相似视觉概念的图像,并且能利用图像的相似性改进自我监督学习的先进水平,而且训练时间减少了6倍。
这种规模的训练模型还需要一个在运行时间和内存方面都效率很高的,又不会损失精确性的模型架构。
幸运的是,FAIR 最近在架构设计领域的一项创新催生了一个称为 RegNets 的新模型家族,它完全符合这些需求。
RegNet 模型能够扩展到数十亿甚至数万亿个参数,可以优化这些参数以适应不同的运行时间和内存限制。
科研团队对比了SEER在随机IG图像上的预训练和在ImageNET上的预训练,结果表明非监督特性比监督特性平均提高了2%。
为SEER技术添上最后一块砖的是VISSL自我监督学习通用库。
服务于SEER的VISSL是开源的,这个通用图书馆能让更广泛的群体可以从图像中进行自我监督学习实验。
VISSL是一个基于PyTorch的库,她允许使用各种现代方法在小规模和大规模上进行自我监督训练。

VISSL还包含了一个一个广泛的基准套件和一个包括了60多个预先训练模型的模型动物园(model zoo),使研究人员可以比较几个现代自我监督方法。
VISSL通过整合现有的几种算法,减少了对每个GPU的内存需要,提高了任意一个给定模型的训练速度,从而实现了大规模的自我监督学习。
SEER的自我监督模型建立在与VISSL相同的核心工具之上,并结合了PyTorch的自定义数据加载器,该加载器的数据吞吐量高于默认值。
自监督学习的未来
Facebook 表示,SEER在预先训练了10亿张公开的instagram图片后,性能优于最先进的自监督模型。
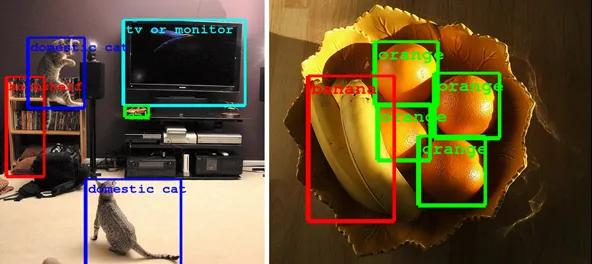
SEER在目标检测分析、分割和图像分类等任务上也取得了最佳结果。

用受欢迎的ImageNet10%的数据集中进行训练时,SEER仍然达到了77.9%的准确率。
当只有1%的数据集训练时,SEER的准确率是60.5% 。
接下来,Facebook将发布SEER背后的一些技术,但不会发布算法本身,因为它使用了instagram用户的数据进行训练。

麻省理工学院计算知觉和认知实验室的负责人Aude Oliva表示,这种方法将使我们能够实践更多雄心勃勃的视觉识别任务,但是像SEER这样的尖端人工智能算法的庞大规模和复杂性也带来了问题。
SEER可能有数十亿或数万亿个神经连接或参数,这样的算法需要大量的计算能力,使可用的芯片供应变得更加紧张。
Facebook的团队使用了具有32GB RAM的 V100 Nvidia GPU,并且随着模型尺寸的增加,必须将模型放入可用的RAM中。
长期以来,自我监督学习一直是 Facebook 人工智能的一个重点,因为它使机器能够直接从世界上大量可用的信息中学习,而不仅仅是从专门为人工智能研究创建的训练数据中学习。
自我监督学习对计算机视觉的未来有着难以置信的影响,就像它在其他研究领域所做的那样。
消除对人工注释和元数据的需求,使计算机视觉社区能够处理更大、更多样化的数据集。
Facebook的研究人员表示,「这一突破可以实现计算机视觉的自监督学习革命。」

参考资料:
https://ai.facebook.com/blog/seer-the-start-of-a-more-powerful-flexible-and-accessible-era-for-computer-vision/
https://venturebeat.com/2021/03/04/facebooks-new-computer-vision-model-achieves-state-of-the-art-performance-by-learning-from-random-images/