【51CTO.com快译】如今,全球的数字广告代理商每天都会在新闻网站、搜索引擎、社交媒体、视频流以及其他媒体平台上投放数以亿计的广告。他们都想解答一个问题:其产品目录中有哪些广告更能吸引特定的用户?当面对数以百计的网站、数以万计的广告以及数以百万的访问者时,获得这个问题的正确答案将会对企业增加收入产生巨大影响。
对于广告代理商来说,幸运的是,强化学习提供了一种解决方案(强化学习是一种主要应用在棋局和视频游戏而闻名的人工智能分支技术)。采用强化学习模型可以获得更大的回报。就网络广告而言,强化学习模式致力于寻找让用户更容易点击的广告。
全球的数字广告行业每年产生数千亿美元的收入,并提供了有关强化学习功能的案例研究。
1.采用A/B/n测试
为了更好地理解强化学习为优化广告的推广提供的帮助,可以考虑一个简单的场景的应用:例如一家新闻网站已经和一家公司签订了合同,在新闻网站上刊登这家公司的广告。该公司为在这个网站发布了五个不同的广告,而在处理两个以上的备选方案时,可以称之为A/B/n测试。
网站运营者的首要目标是找到产生点击次数最多的广告。在广告术语中,需要最大限度地提高点击率(CTR)。点击率是点击次数与展现广告数量的比值,也称为展示次数。例如,如果展现了1,000次广告,为网站带来了3次点击,则其点击率将是3/1000 = 0.003或0.3%。
在通过强化学习解决问题之前,先来讨论一下A/B测试,这是一种用于比较两个竞争解决方案(A和B)的性能的标准技术,例如不同的网页布局、产品推荐或广告。当处理两种以上的选择时,称为A/B/n测试。
在A/B/n测试中,通常将实验对象随机分为不同的组,每组都提供一种可用的解决方案。而在这个新闻网站发布广告的案例中,这意味着将随机向网站的每个访问者展示五个广告中的一个,并对展示结果进行评估。
假设对A/B/ n测试进行了10万次展示,相当于每个广告大约有2万次展示。以下是5个广告的点击率:
广告1:80/20,000=0.40%
广告2:70/20,000=0.35%
广告3:90/0,000=0.45%
广告4:62/20,000=0.31%
广告5:50/20,000=0.25%
该网站在10万次广告展示中获得了352美元的收入,平均点击率是0.35%。更重要的是,网站运营者发现第3个广告的展示效果要优于其他几个广告,并将继续将其用于吸引其他访问者。而使用展示效果最差的广告(第5个广告),获得收入应为250美元。如果使用展示效果最好的广告(第3个广告),收入应为450美元。因此,采用A/B/n测试提供了最低和最高收入的平均值,并提供了除了展现点击率之外更具价值的知识。
数字广告的转化率其实非常低。在这个示例中,效果最好的广告和效果最差的广告之间只存在0.2%的细微差别。但是这种差别会可能在规模上产生重大影响。与第5个广告相比,在展示次数为1,000次的情况下,展示第3个广告将会多获得2美元。在展示次数为100万次的情况下,这个差额为2,000美元。当投放数十亿次广告时,0.2%的细微差别会对网站收入产生巨大影响。
因此,找到这些细微的差别对于广告优化非常重要。A/B/n测试的问题在于查找这些差别并不是很有效。它通常平等地对待所有广告的展示,只有运行数万次广告,才能以可靠的置信度发现它们之间的差异。这可能会导致收入损失,尤其是当发布更多广告时。
传统A/B/n测试的另一个问题是它是静态的。一旦找到了最佳的广告,就必须坚持下去。如果环境由于出现新的因素(例如季节和新闻趋势等)而发生变化,并导致其他广告中的一个具有潜在更高的点击率(CTR),除非重新进行A/B/n测试,否则难以发现。
如果可以更改A/B/n测试使其更高效、更动态呢?这就是强化学习发挥重要作用的地方。广告代理商必须找到一种最大限度地提高其回报的方法。
在这个案例中,强化学习代理的行为是要展示这五个广告。而用户每次点击广告,强化学习代理都会获得奖励的积分。因此必须找到一种最大限度提高广告点击量的方法。
2.多臂老虎机(Multi-armed Bandit)
多臂老虎机是找到通过反复试验发现几种解决方案之一的方法。
在某些强化学习环境中,其动作是按顺序进行评估的。例如在电子游戏中,在完成一个关卡或赢得一场比赛时,必须执行一系列动作才能获得奖励。而在投放广告时,每个广告展示的结果都是独立评估的,这是一个单一步骤的环境。
为了解决广告优化问题,可以将使用多臂老虎机(Multi-armed Bandit)算法,这是一种适用于单一步骤强化学习的算法。多臂老虎机(MAB)来自一个假想场景:在这个场景中,很多人都在玩老虎机,并知道这些老虎机有不同的中奖率,但并不知道哪一台老虎机的中奖率最高。
如果某人坚持玩某一台老虎机,可能会失去选择中奖率最高的老虎机的机会。因此,必须找到一种有效的方法来发现最高中奖率的老虎机,而又不会投入太多的筹码。
广告优化案例就是一种采用多臂老虎机原理的一个典型示例。在这种情况下,强化学习代理必须找到一种方法来发现点击率最高的广告,而不会在效率低下的广告上浪费太多的时间和资源。
3.探索vs.开发
每个强化学习模型都面临的一个问题是“探索vs.开发”的挑战。开发意味着坚持使用强化学习代理迄今为止发现的最佳解决方案,而探索意味着尝试其他解决方案,希望找到比当前最佳解决方案更好的解决方案。
在选择广告的应用中,强化学习代理必须在选择展示效果最佳的广告和探索其他选择之间做出决定
解决开发或探索问题的一种方法是采用“ε-greedy”算法。在这种情况下,强化学习模型通常会选择最佳的解决方案,在指定百分比的情况下(ε因子),将随机选择其中一个广告。
每个强化学习算法都必须在探索最佳解决方案和探索新选择之间找到适当的平衡。这是一个实际的运作方式。假设有一个采用ε-greedy算法的多臂老虎机(MAB)代理,其ε因子设置为0.2。这意味着代理可以在80%的时间中选择效果最佳的广告,而另外20%的时间选择其他广告。
强化学习模型是在不知道哪个广告效果更好的情况下启动的,因此为每个广告分配了相同的投放次数。当所有广告的投放次数均等时,将会在每次投放广告时随机选择其中一个。
在投放200次广告之后(5个广告分别有40次投放次数),有人点击了一次第4个广告。强化学习代理会按以下方式调整广告的点击率:
广告1:0/40=0.0%
广告2:0/40=0.0%
广告3:0/40=0.0%
广告4:1/40=2.5%
广告5:0/40=0.0%
现在,强化学习代理认为第4个广告是效果最好的广告。对于每个广告的展示,将选择一个介于0和1之间的随机数。如果该数字大于0.2(ε因子),则会选择第4个广告。如果该数字小于0.2,则会随机选择一个其他广告。
现在,强化学习代理在另一个用户点击广告之前又展示了200次其他广告,这次有人点击了一次第3个广告。需要注意的是,在这200次展示中,由于第4个广告是最佳广告,将获得80%的广告展示次数(160次)。而其余的平均分配给其他广告,而新的点击率值如下:
广告1:0/50=0.0%
广告2:0/50=0.0%
广告3:1/50=2.0%
广告4:1/200=0.5%
广告5:0/50=0.0%
现在最理想的广告变为第3个广告。它将获得80%的广告展示次数。假设再获得100次展示(第3个广告为80次,而其他每个广告为4次),则有人点击了一次第2个广告。以下是新的点击率分布状况:
广告1:0/54=0.0%
广告2:1/54=1.8%
广告3:1/130=0.7%
广告4:1/204=0.49%
广告5:0/54=0.0%
现在,第2个广告是最佳解决方案。随着投放更多广告,点击率将反映每个广告的实际价值。效果最好的广告将获得最多的展示次数,但强化学习代理将继续探索其他选择。因此,如果环境发生变化,用户开始对某个广告有着更积极的反应表现,强化学习就可以发现。
在投放了10万个广告之后,其分布状况如下所示:
广告1:123/30,600=0.40%
广告2:67/18,900=0.35%
广告3:187/41,400=0.45%
广告4:35/11,300=0.31%
广告5:15/5,800=0.26%
使用ε-greedy算法,可以将10万次广告展示的收入从352美元提高到426美元,平均点击率达到0.42%。这是对传统的A/B/n测试模型的重大改进。
改进ε-greedy算法
ε-greedy强化学习算法的关键是调整ε因子。如果将其设置得太低,将利用认为最好的广告,其可能的代价是找不到更好的解决方案。例如,在上面探索的示例中,第四个广告恰好有了第一次点击,但从长远来看,它的点击率并不是最高的。因此小样本不一定代表真实的分布。
另一方面,如果将ε因子设置得过高,则强化学习代理将会浪费太多资源来探索非最佳解决方案。
改善ε-greedy算法的一种方法是定义动态策略。当多臂老虎机(MAB)模型开始运行时,可以从较高的ε因子开始进行更多的探索和更少的开发。随着模型投放更多的广告,并更好地估计每个解决方案的价值,它可以逐渐减小ε因子直至达到阈值。
在优化广告问题的背景下,可以将ε因子设为0.5,然后在每1000次广告展示后将其减小0.01,直到达到0.1。
改善多臂老虎机(MAB)的另一种方法是将更多的精力放在新的观测值上,并逐渐降低原有观测值的价值。这在动态环境(例如数字广告和产品推荐)中特别有用,在动态环境中解决方案的价值会随着时间而变化。
这是一种非常简单的方法。投放广告后更新点击率的传统方法如下:
(result + past_results)/impressions
此处,result是所显示广告的结果(如果点击则为1,如果未点击则为0),past_results是这个广告迄今为止获得的累计点击次数,而impressions数量是该广告已投放的总次数。
要逐渐淡化原有结果,可以添加一个新的alpha因子(介于0和1之间),并进行以下更改:
(result + past_results * alpha)/impressions
这个微小的变化将使新的观察结果带来更大的影响。因此,如果有两个相互竞争的广告,而它们的点击次数和展示次数相等,那么在强化学习模型中,将会选择点击次数最高的那个广告。此外,如果某个广告过去的点击率非常高,但最近却没有响应,则其价值在该模型中的下降速度会更快,从而迫使强化学习模型更早地转向其他替代方案,并在效率低下的广告上使用更少的资源。
为强化学习模型添加场景
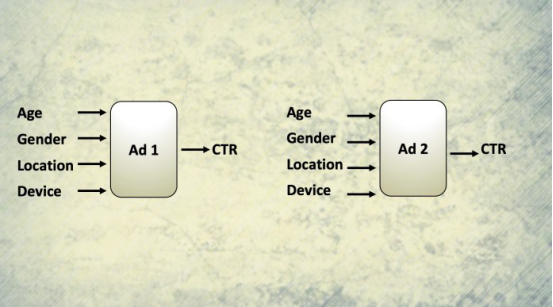
上下文老虎机利用函数近似来考虑广告受众的个体特征
在互联网时代,网站、社交媒体和移动应用程序拥有大量用户的信息,例如他们的地理位置、设备类型以及观看广告的确切时间。社交媒体公司拥有更多关于他们用户的信息,其中包括年龄、性别、朋友和家人,他们过去分享的内容类型。喜欢或点击的帖子类型等等。
这些丰富的信息使这些公司有机会为每个观众提供个性化广告。但是,所创建的多臂老虎机(MAB)模型向所有人显示了相同的广告,并且没有考虑每个受众的特定特征。如果想为多臂老虎机(MAB)增加上下文该怎么办?
一种解决方案是创建多个多臂老虎机(MAB)模型,每个模型针对特定的用户子领域。例如,可以为北美、欧洲、中东、亚洲、非洲等地用户创建单独的强化学习模型。如果还要考虑性别怎么办?那么将为北美地区的女性用户提供一种强化学习模型,为北美地区的男性用户提供另一种强化学习模型等。如果还要添加年龄和设备类型等因素,可能看到它很快就会成为一个大问题,这造成多臂老虎机(MAB)模型数量激增,难以训练和维护。
一种替代解决方案是使用“上下文老虎机”(Contextual Bandit),这是考虑到上下文信息的多臂老虎机(MAB)的升级版本。上下文老虎机没有为每个特征组合创建单独的多臂老虎机(MAB),而是使用“函数近似”,它试图根据一组输入因素对每个解决方案的性能进行建模。
无需过多讨论细节,上下文老虎机使用监督的机器学习根据位置、设备类型、性别、年龄等来预测每个广告的效果。多臂老虎机(MAB)是每个广告使用一个机器学习模型,而不是每个特征组合都需要创建上下文老虎机。
这总结了关于通过强化学习优化广告的讨论。而强化学习技术可用于解决许多其他问题,例如推荐内容和产品或动态定价,并且可用于其他领域,例如医疗保健、投资和网络管理等行业领域。
原文标题:How reinforcement learning chooses the ads you see,作者:By Ben Dickson
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】