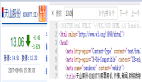
urllib是Python3中内置的HTTP请求库,不需要单独安装,官方文档链接如下:https://docs.python.org/3/library/urllib.html从官方文档可以看出,urllib包含4个模块,如图1所示。

图1 urllib官方文档目录
这4个模块的功能描述如下:
- request:最基本的HTTP请求模块,可以用来发送HTTP请求,并接收服务端的响应数据。这个过程就像在浏览器地址栏输入URL,然后按Enter键一样。
- error:异常处理模块,如果出现请求错误,我们可以捕获这些异常,然后根据实际情况,或者进行重试,或者直接忽略,或进行其他操作。
- parse:工具模块,提供了很多处理URL的API,如拆分、解析、合并等。
- robotparser:主要用来识别网站的robots.txt文件,然后判断哪些网站可以抓取,哪些网站不可以抓取。
本文主要介绍如何通过urllib发送HTTP GET请求和HTTP POST请求,并获取相应数据。
1. 用urlopen函数发送HTTP GET请求
urllib最基本的一个功能就是向服务端发送HTTP请求,然后接收服务端返回的响应数据。这个功能只需要通过urlopen函数就可以搞定。例如,下面的代码向百度发送HTTP GET请求,然后输出服务端的响应结果。
- import urllib.request
- response=urllib.request.urlopen('https://baidu.com')
- # 将服务端的响应数据用utf-8解码
- print(response.read().decode('utf-8'))
运行结果如图2所示。
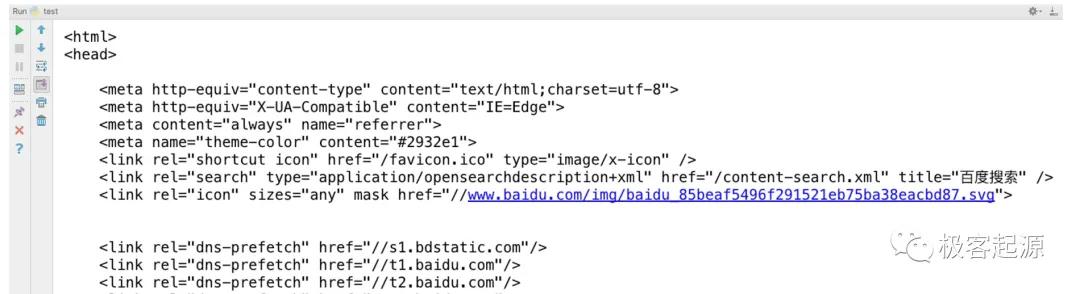
图2 百度首页的HTML代码
我们可以看到,使用urllib与服务端交互是非常容易的,除了import语句外,真正与业务有关的代码只有2行,就完成了整个与服务端交互的过程。其实这个过程已经完成了爬虫的第一步,就是从服务端获取HTML代码,然后就可以利用各种分析库对HTML代码进行解析,提取出我们感兴趣的URL、文本、图像等。其实urlopen函数返回的是一个对象,而read是这个对象的一个方法,可以利用type方法输出这个对象的类型,当我们知道了对象类型后,就可以很容易知道这个对象中有哪些API,然后调用它们。
- import urllib.request
- response=urllib.request.urlopen('https://baidu.com')
- print(type(response))
这段代码会输出如下的结果:
- <class 'http.client.HTTPResponse'>
现在我们了解到,urlopen函数返回的是HTTPResponse类型的对象,主要包含read、getheader、getheaders等方法,以及msg、version、status、debuglevel、closed等属性。下面是一个实际的案例,用来演示了HTTPResponse对象中主要的方法和属性的用法。
- import urllib.request
- # 向京东商城发送HTTP GET请求,urlopen函数即可以使用http,也可以使用https
- response=urllib.request.urlopen('https://www.jd.com')
- # 输出urlopen函数返回值的数据类型
- print('response的类型:',type(response))
- # 输出响应状态码、响应消息和HTTP版本
- print('status:',response.status,' msg:',response.msg,' version:', response.version)
- # 输出所有的响应头信息
- print('headers:',response.getheaders())
- # 输出名为Content-Type的响应头信息
- print('headers.Content-Type',response.getheader('Content-Type'))
- # 输出京东商城首页所有的HTML代码(经过utf-8解码)
- print(response.read().decode('utf-8'))
运行结果如图3所示。
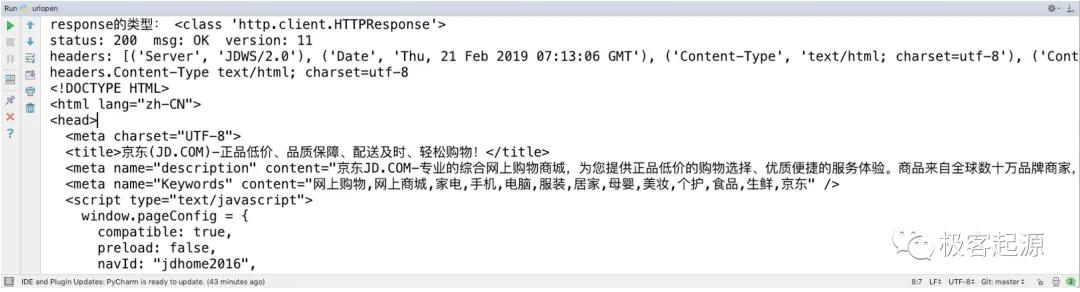
图3 HTTPResponse对象的API演示
2. 用urlopen函数发送HTTP POST请求
urlopen函数默认情况下发送的是HTTP GET请求,如果要发送HTTP POST请求,需要使用data命名参数,该参数是bytes类型,需要用bytes类将字符串形式的数据转换为bytes类型。下面的例子
下面的例子向http://httpbin.org/post发送HTTP POST请求,并输出返回结果。
- import urllib.request
- # 将表单数据转换为bytes类型,用utf-8编码
- data=bytes(urllib.parse.urlencode({'name':'Bill','age':30}),encoding='utf-8')
- # 提交HTTP POST请求
- response=urllib.request.urlopen('http://httpbin.org/post',data=data)
- # 输出响应数据
- print(response.read().decode('utf-8'))
这段代码中一开始提供了一个字典形式的表单数据,然后使用urlencode方法将字典类型的表单转换为字符串形式的表单,接下来将字符串形式的表单按utf-8编码转换为bytes类型,这就是要传给urlopen函数的data命名参数的值,要注意,一旦指定了data命名参数,urlopen函数就会向服务端提交HTTP POST请求,这里并不需要显式指定要提交的是POST请求。
本例将HTTP POST请求提交给了http://httpbin.org/post,这是一个用于测试HTTP POST请求的网址,如果请求成功,服务端会将HTTP POST请求信息原封不动地返回给客户端。运行结果如图4所示。
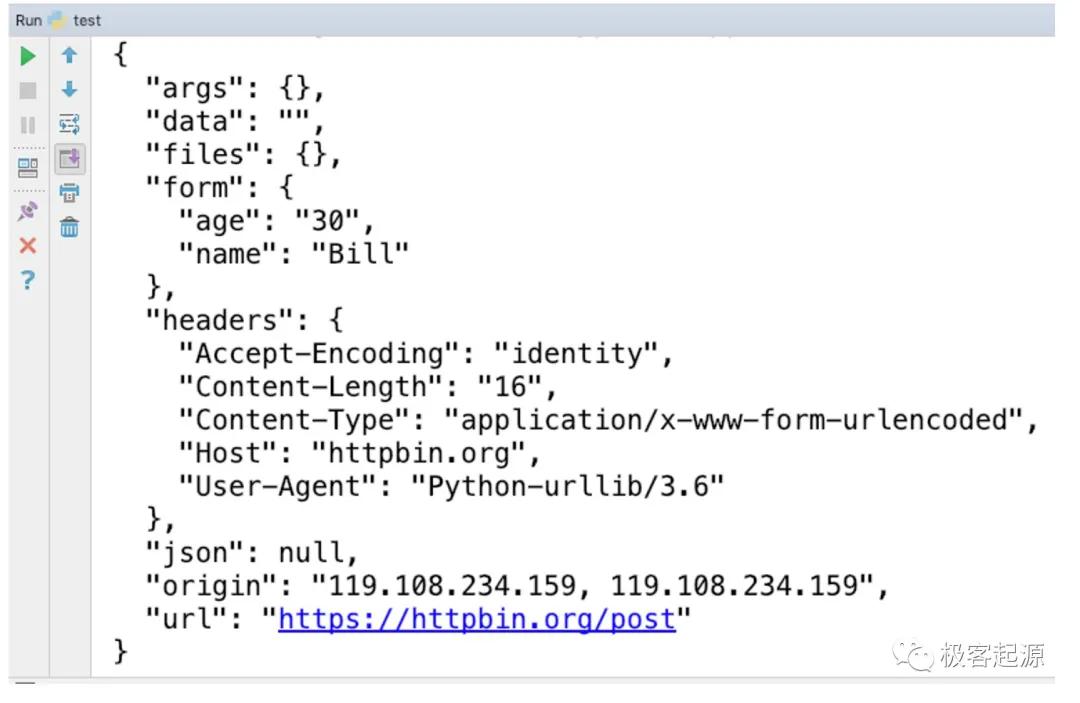
图4 HTTP POST请求信息
本文转载自微信公众号「极客起源」,可以通过以下二维码关注。转载本文请联系极客起源公众号。