












有一些同学在写爬虫的时候,喜欢在Chrome 开发者工具里面直接复制 XPath,如下图所示:
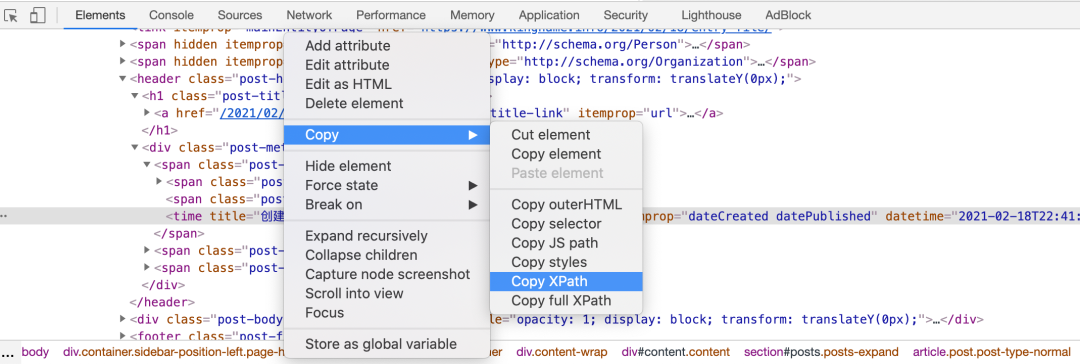
他们觉得这样复制出来的 XPath 虽然长了点,但是工作一切正常,所以频繁使用。
但我希望大家不要过于依赖这个功能。因为它给出的结果仅作参考,有时候并不能让你提取出数据。我们来看一个例子。
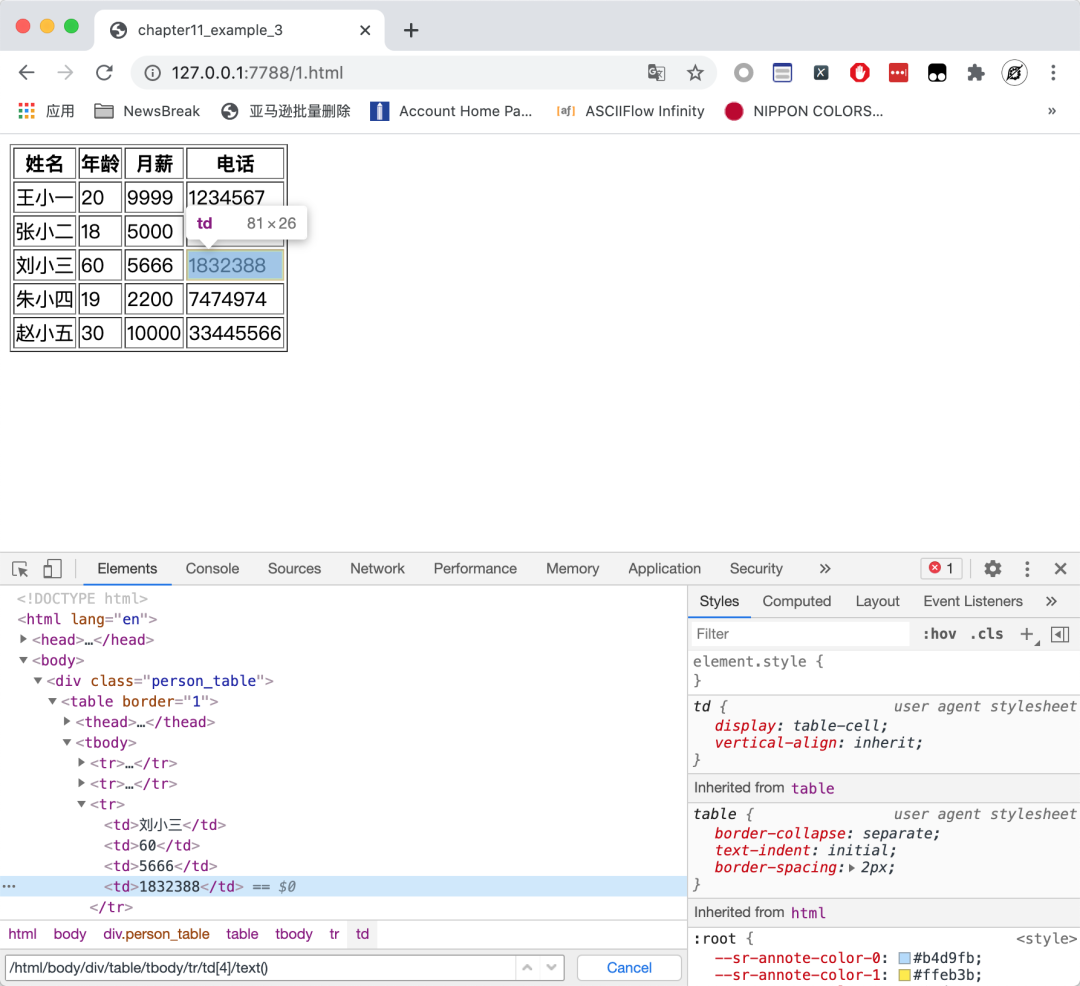
这是一个非常简单的HTML 页面,页面中有一个表格,表格有一列叫做电话。我现在想把这里面的5个电话提取出来。如果直接使用 Chrome 的复制 XPath 的功能,我们可以得到下面这个 XPath:
- /html/body/div/table/tbody/tr[3]/td[4]
这实际上对应了刘小三这一行的电话字段。那么,我们去掉tr后面的数字,似乎就能覆盖到所有行了:
- /html/body/div/table/tbody/tr/td[4]/text()
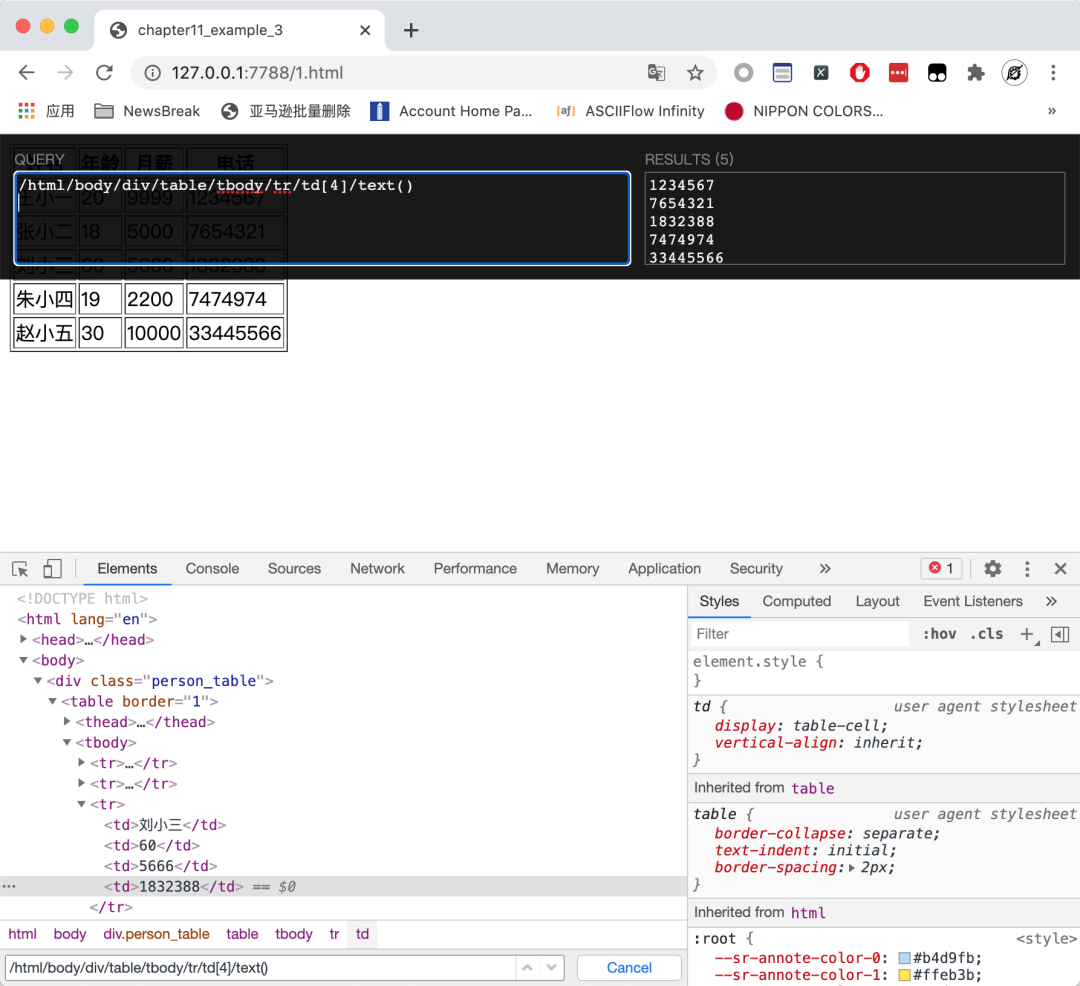
在 XPath Helper 上面运行看看效果,确实提取出了所有的电话号码,如下图所示:
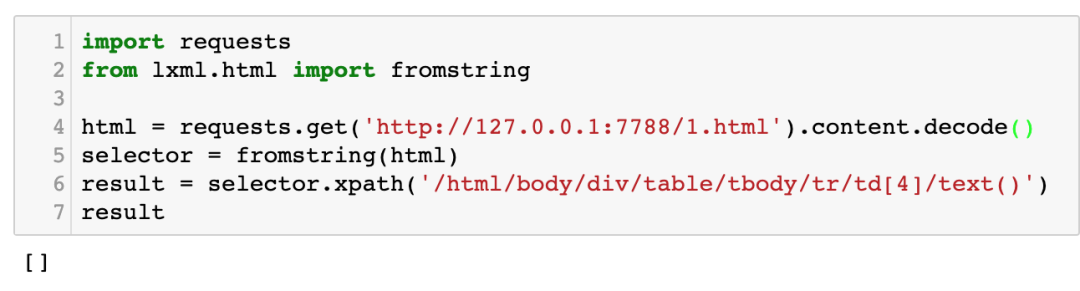
但如果你使用 requests 来爬这个网页,然后使用 XPath 提取电话号码,你就会发现什么都提取不到,如下图所示:
你可能会想,这应该是异步加载导致的问题。表格里面的数据是通过 Ajax 后台加载的,不在网页源代码里面。
那么我们打印看看网页的源代码:
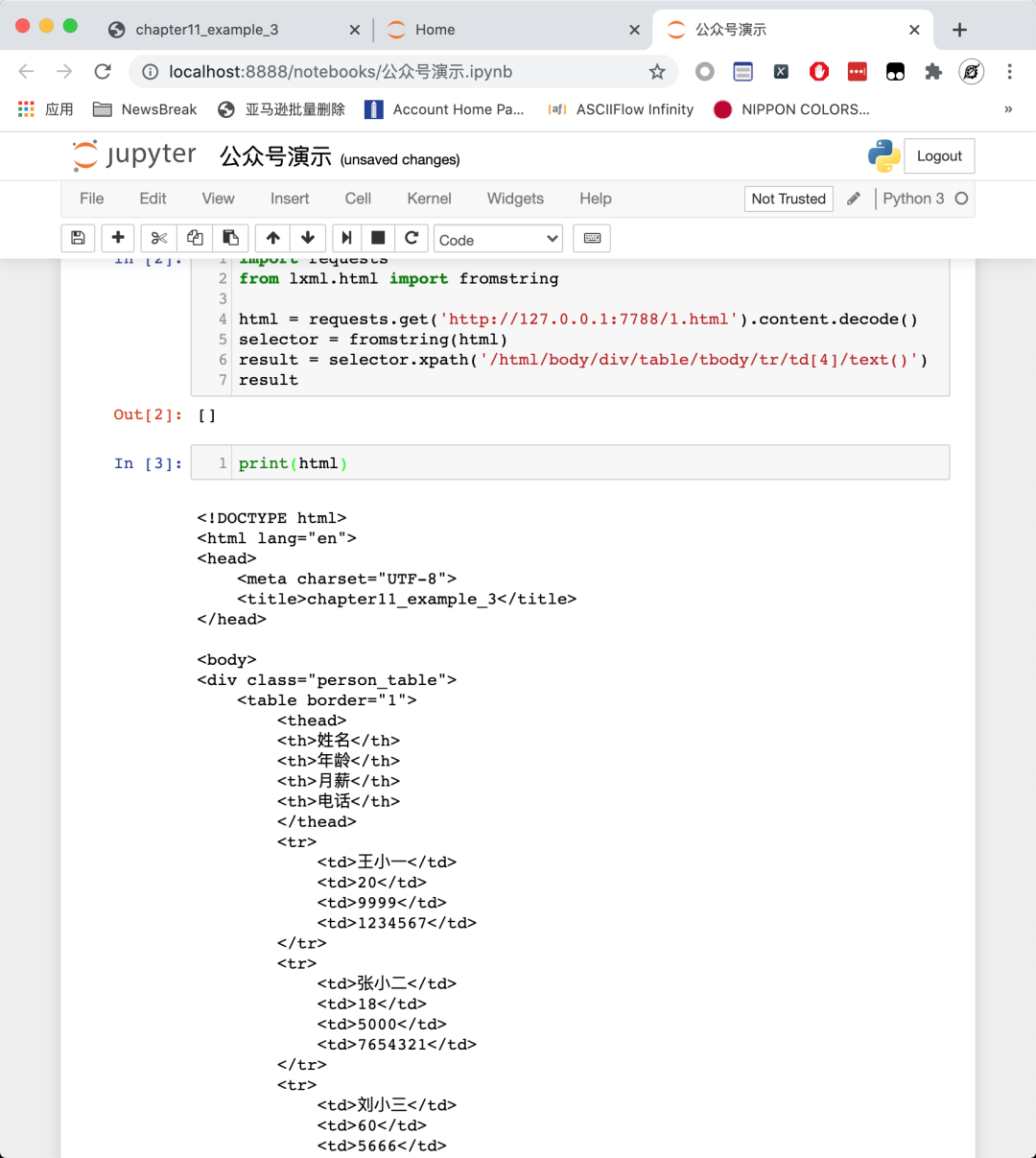
大家可以看到,数据就在网页源代码里面,那为什么我们在Chrome 上面通过 XPath Helper 就能提取数据,而用 requests 就无法提取数据?
实际上,如果大家仔细观察从 Chrome 中复制出来的 XPath,就会发现它里面有一个tbody节点。但是我们的网页源代码是没有这个节点的。
这就要说到 Chrome 开发者工具里面显示的 HTML 代码,跟网页真正的源代码之间的区别了。很多人分不清楚这两者的区别,所以导致写出的 XPath 匹配不到数据。
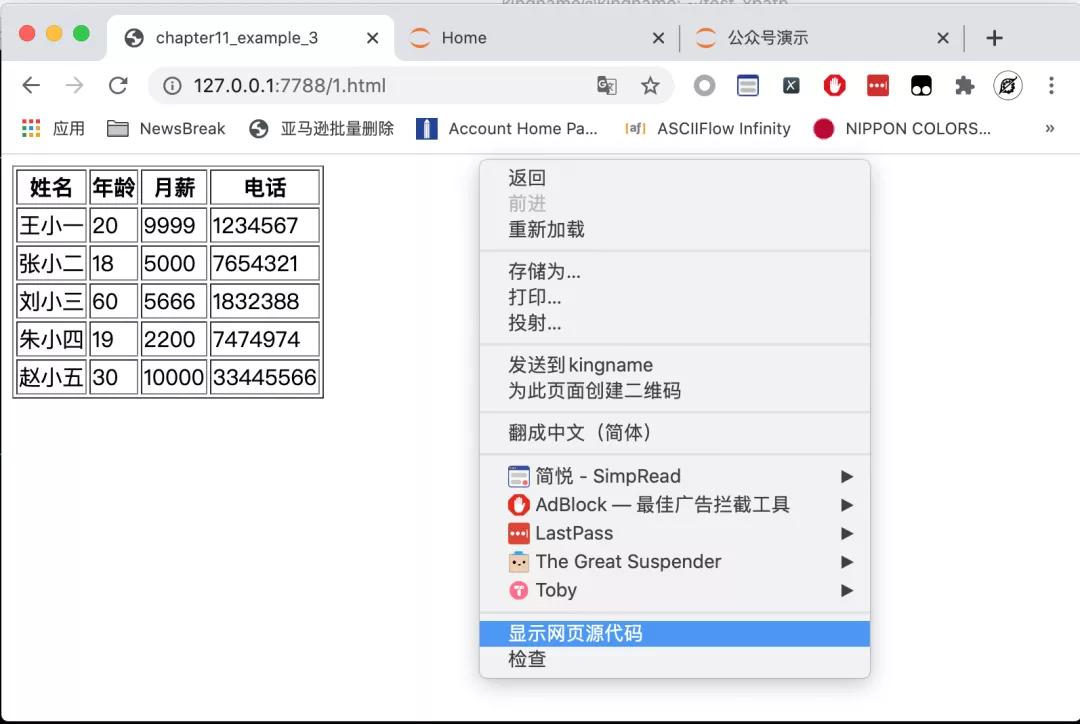
当我们说到网页源代码的时候,我们指的是在网页上右键,选择“显示网页源代码”按钮所查看到的 HTML 代码,如下图所示:
这个查看源代码的页面长成下图所示的这样:
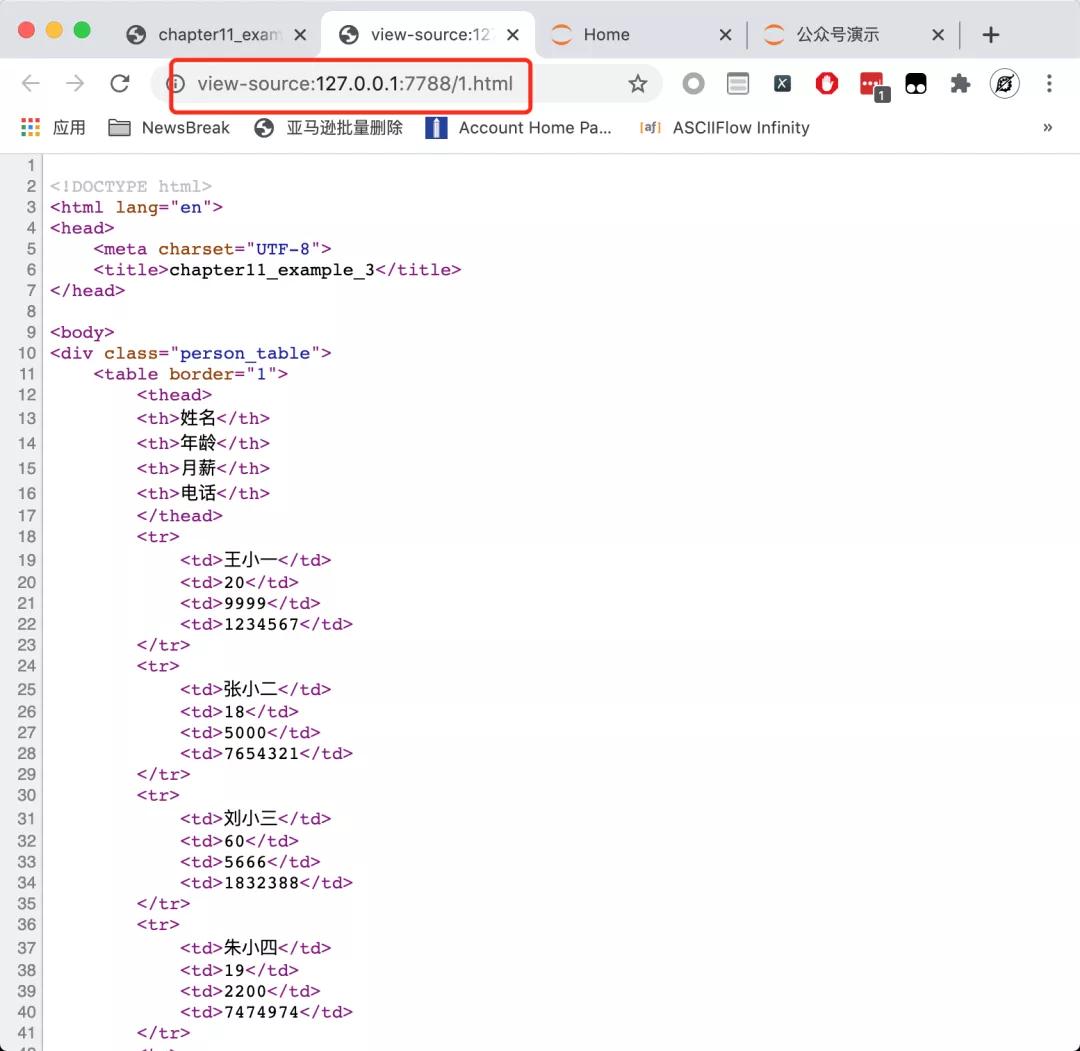
注意地址栏,是以view-source:开头的。这才是网页真真正正的源代码。
而Chrome 的开发者工具里面的Element标签所显示的源代码,长成下面这样:
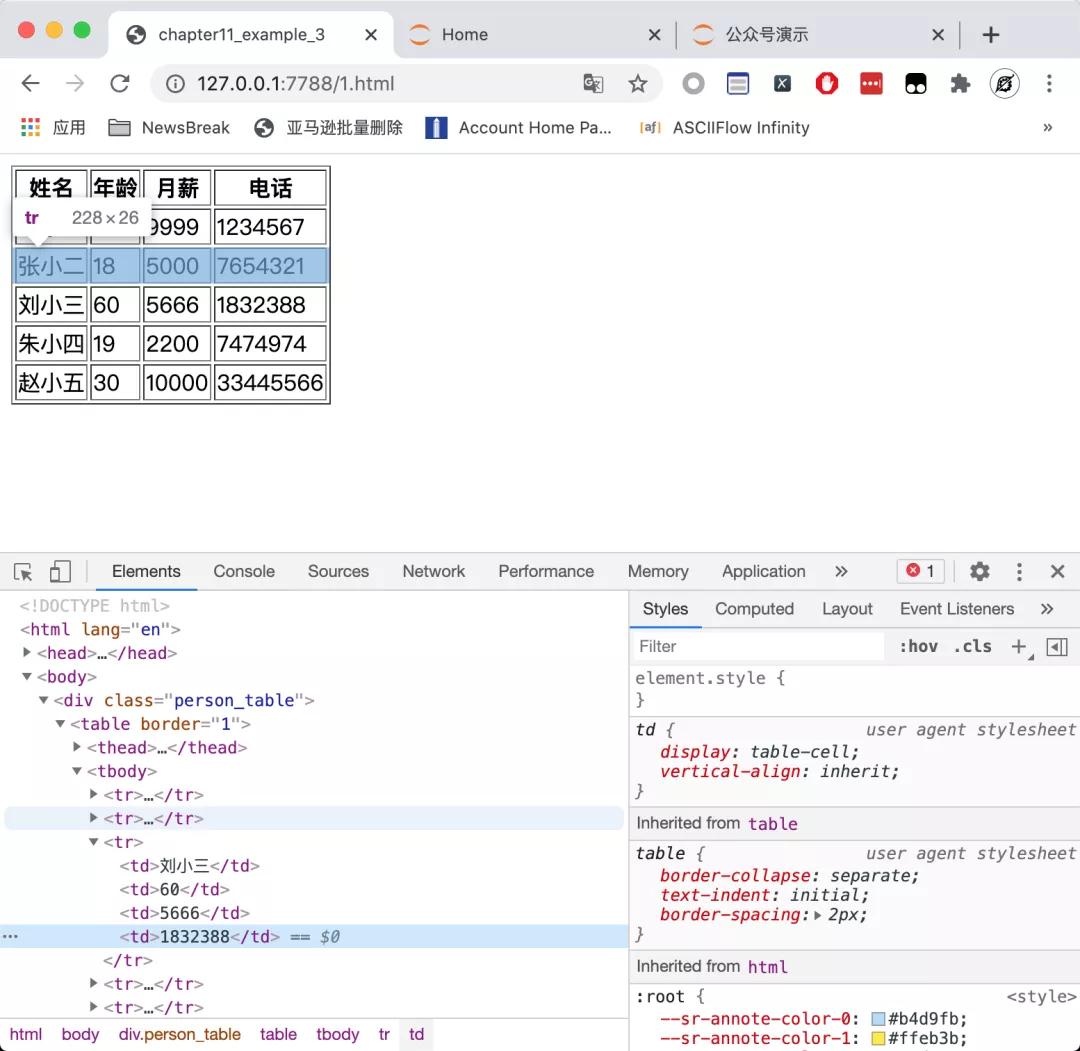
这两个地方的HTML代码可能是不一样的,而且在现代化的网站中,这两个地方的 HTML大概率是不一样的。当我们使用 requests 或者 Scrapy 时,拿到的是第一种情况的源代码,这才是网页真正的源代码。而在开发者工具里面的 HTML 代码,是经过 Chrome 浏览器修饰甚至大幅度增删后的 HTML 代码。当网站有异步加载时,JavaScript 可以轻易在这里增加、删除非常多的内容。即使网站没有异步加载,如果网站原始的 HTML 代码编写不够规范,或者存在一些错漏,那么 Chrome 浏览器会自动纠错和调整。
以本文的例子来说,在 HTML 的官方规范里面,表格的正文确实应该包在标签里面。但现在大多数情况下,前端开发者都会省略这个标签,所以真正的源代码里面是没有这个标签的。而 Chrome 会自动识别到这种情况,然后自动加上这个标签,所以在开发者工具里面看到的 HTML 代码是有这个标签的。
当你写爬虫的时候,不仅仅是 Chrome 开发者工具里面复制的 XPath 仅作参考,甚至这个开发者工具里面显示的 HTML 代码也是仅作参考。你应该首先检查你需要的数据是不是在真正的源代码里面,然后再来确定是写 XPath 还是抓接口。如果是写 XPath,那么更应该以这个真正的源代码为准,而不是开发者工具里面的 HTML 代码。
本文转载自微信公众号「未闻Code」,可以通过以下二维码关注。转载本文请联系未闻Code公众号。




















