注:本文为我最近阅读《微服务架构设计模式》的一点感悟,我不准备详细去写对该书的读书笔记记录,而是结合我们自己所做的一些微服务架构实践情况做一些总结和复盘。
从单体应用到微服务
任何一个新的架构模式或方法的出现,一定是传统架构模式遇到了问题。而对于单体应用来说常说的问题主要包括了如下几个点。
单体应用规模太大,导致复杂度剧增,难以开发和管理
单体应用开发,交付和变更周期变长,敏捷性跟不上
单体应用本身在性能,扩展性上出现了问题
在软件架构设计里面,分而治之始终都是解决复杂性的一个关键思维方法。包括在传统软件架构设计里面对于大系统会进行子系统或组件划分,会进行接口设计,集成设计等。
架构的核心思维仍然是:分解+集成
但是传统架构在分解的时候没有做到单个组件的高度独立自治和彻底解构。这个高度独立自治实际上要求组件或模块从开发,设计,测试,上线运行,后期运维全生命周期都做到高度独立;同时还要求配合的开发团队,组织结构设计也独立。
也正是这个原因进一步发展出了微服务架构。也就是说微服务架构实际是传统组件化架构设计思想的进一步强化,强化的核心就是独立和解耦。
微服务架构思想的一个重点就是单体应用的拆分。
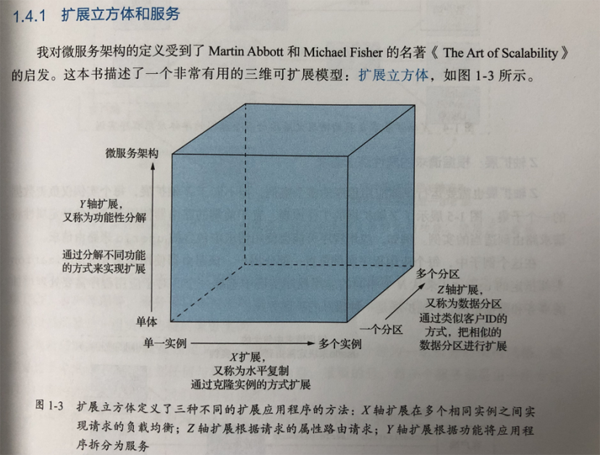
讲微服务一定会谈到扩展立方体。
对于传统单体应用一般来讲扩展的方法只能是X坐标轴的通过扩展实例方式的水平扩展。而另外两个重要的扩展一个是功能拆分,一个是数据库拆分。
对于功能拆分实际不是新鲜东西,在很早组件化架构设计我们就做过将不同的应用组件部署到不同的App Server服务器上,对于应用层你只需要考虑解决类似Session会话保存,全局配置和分发等问题即可,不会涉及到复杂的数据持久化问题。
而真正难的是在数据库拆分。因为数据库拆分引入了两个大问题,其一是分布式事务问题,其二是大量操作跨库带来的分布式事务问题。
数据库为何要拆分?
在单体应用发展到一定阶段后,出现的性能问题往往都是DB层面的难以解决。数据库集群很难做到水平弹性扩展,即使对于类似Oracle RAC等商用集群软件,本身也有性能扩展瓶颈。性能扩展到2到3倍后已经无法再扩展。
因此单纯从扩展实例扩展来说,后面衍生了读写分离集群,读写分离集群在应对读操作占比大的业务场景下实际是最佳的一种扩展方式,在这种方式下数据库本身并没有拆分为多个实例,不会引入前面遇到的两个大问题。只要在数据库上搭建一个DaaS数据库访问中间件,那么数据库底层的这种拆分和变化完全可以做到对上层应用开发透明。
当谈到这里的时候,再来回顾一下微服务的一些核心点自然就更加清楚。
微服务是传统单体的拆分,而且需要做到高度独立自治
微服务的拆分不仅仅是功能拆分,更加重要是数据库拆分
异步和解耦是微服务架构设计的重要指导思想
微服务间通过轻量高效的Http API接口交互协同
微服务实践需要开发组织,持续集成,测试,交付方式配套支撑
场景和问题驱动
在前面谈微服务的时候我就谈到过,微服务架构本身将导致开发,集成,运维复杂度全部增加。即使对于常说的高可用性,也仅仅是高可用性和弹性扩展能力增加,但是对于高可靠性反而是降低。
那么一个企业或团队是什么原因实践微服务?仅仅是微服务是一种架构发展趋势,是技术热点,是互联网大厂都在用吗?
而实际对于很多企业应用微服务可以看到,更多是团队里面总有一些技术狂热份子,热衷于新架构,新技术,但是对于这些技术究竟解决了哪些业务场景下的问题并不关心。这直接就导致了大量技术在不恰当的时候被应用。
并不是说微服务不好,而是说对于架构师来说应该基于业务,技术,团队资源,成本等多个维度来综合考虑究竟应该在什么时候用什么样的技术最合适。
类似阿里的电商平台,一天访问量上亿,接近百万的TPS,高峰秒级成交都几十万笔,这种业务场景下各个模块拆分为独立中心,独立数据库是必然。不是说什么技术先进了必须使用,而是为了满足和支撑业务必须微服务化。
那么传统企业实践微服务就一定要思考微服务究竟能解决什么问题。如果这个问题没有想清楚就不要轻易去搞微服务。其次就是通过其他传统方式能解决的也不要轻易去理想化的实践微服务架构。
比如一个业务系统运行过程中数据库出现性能瓶颈,这个时候你可以考虑的是将历史数据进行迁移到备库,增加备库单据查询能力;或者是前面谈到的构建数据库的读写分离集群或者在数据库上构建二级索引缓存库来解决性能问题。
再比如一些业务系统出现瓶颈,并不是常规的OLTP场景出现问题,而是单个业务系统数据库同时在支撑OLTP和OLAP能力。这个时候你应该做到是将大量的查询统计和数据分析功能移出,而不是对整个业务系统进行数据拆分。
这方面的例子还有很多,实际是想说明一点,很多业务系统的复杂度和性能问题远远没有到必须进行功能拆分和数据库拆分才能够解决的地步。
微服务拆分策略
当聊微服务拆分的时候先谈下传统软件架构设计里面的组件拆分。
对于组件拆分可以看到常规的组件拆分实际是在应用层而没有到具体的数据库。这就导致了组件拆分后,底层数据库仍然是一个中心点和紧耦合点。包括组件拆分后,实际架构规划的时候希望通过组件间通过接口调用协同的,后续在开发实现中往往也出现偏差,即常说的仍然是通过底层数据库的关联sql查询等来解决问题。所以你看到情况是组件间并没有什么接口调用,而大量的耦合都转到底层数据库的耦合上面。
到了微服务阶段的拆分,实际上变成了两个重要的事情,一个是数据库的拆分,一个是基于数据库拆分后的功能拆分。
对于拆分我前面写过两篇文章可以参考:
对领域模型和上下文边界分析来划分微服务的再思考
聊聊DaaS数据库即服务和微服务下数据库拆分
不论是采用的是传统的结构化分析方法,还是当前类似DDD领域驱动建模里面的子域划分,上下文边界识别等。拆分的重点仍然是在数据库拆分上面,只是DDD方法里面将其理解为核心领域对象拆分,领域对象拆分出来自然对应的数据库和功能都进行了拆分。
先梳理清楚边界并进行服务拆分,再基于业务协同和业务功能实现来梳理和定义API接口,也就是说微服务拆分工作实际包括了三个方面的事情。
即数据库拆分,功能拆分,API接口识别和定义。
对于微服务拆分来说,真正的困难点是在微服务拆分的颗粒度上,当重新读这本书的时候再次庆幸我们没有按书里面这么理想化的方法去实践微服务,去将微服务拆分的如此细,否则真正是思路一条。
因此在这里需要重申一个重要观点。
微服务拆分不应该是按标准理论理想化的拆分到哪个颗粒度,而是应该根据实际的业务场景和扩展性需求,开发团队管理需求拆分到一个合适的颗粒度。
比如你现在做的是一个外卖订餐系统,如果是类似美团APP这种规模进行细粒度的微服务拆分势在必然。但是如果你的系统面对的市场仅仅是类似社区,园区等私有云部署场景。那么这个系统从业务场景和并发量上都没有必要做大的微服务拆分,实际架构上进行前后端分离,独立缓存库,读写分离基本完全可以解决问题。
因此微服务拆分到哪个程度,跟业务系统面对的业务场景和问题有关,而不要用标准的类似拆分方法策略去做拆分。
类似面向对象的分析设计,DDD领域驱动和领域对象分析识别,这些方法都没有问题,这些完全可以应用到应用内部,应用内部也需要组件化拆分,而不是说组件化后每个组件就必须拆分为独立的高度自治的微服务。
从API接口到异步解耦
对于微服务架构中的API接口设计,在前面我专门写过文章来进行描述。在这里还是想重新来说明对API接口设计和暴露里面的两个重要观点。
对Http Rest API标准规范的理解
要知道Rest API更多的是一种面向资源的API接口设计方法。在早期我自己也坚持一个观点即需要安装理想化的Rest接口设计方法来设计接口。但是当前我更倾向于仅仅将Http API作为接口实现方式,是否Rest风格并不是重点。
即在接口实现中完全可以将所有接口实现POST接口方法,而不用去区分哪些必须用GET,哪些还得用PUT方法。虽然都实现为POST方法后会对一些接口的在线访问和测试带来一些不方便,但是这个完全可以通过其它方式去解决掉。
前后端分离和大量API接口暴露
API接口本身应该是粗粒度的,但是实际在很多项目里面看到往往将数据库表的CRUD方法全部暴露为了API接口方法。这个一方面是领域对象层的贫血,一个是前后端分离导致原来数据访问层的内部API接口全部都需要通过Http API接口方式暴露。
一个内部的IT系统,本身仅仅内部局域网使用,只提供PC端的BS浏览界面也没有对APP端的支撑需求,在这种情况下前后端分离没有任何必要。前后端分离反而带来了后端API接口大量暴露,前端和后端集成协同等大量问题。
在这种场景下如果IT系统划分为5个微服务模块,这5个微服务模块之间的API接口设计和集成,才是我们真正需要去关注的问题点。
在当前微服务架构设计里面,微服务间的接口协同,微服务本身前后端接口协同全部混杂在一起,实际导致了后续整个微服务体系里面的API管控治理完全失控。
基于Saga分布式事务
前面谈分布式事务的时候,更多谈的是事物补偿或者事务最终一致性保障,但是很多长周期的事务仍然是API接口的同步调用方式来实现。即当API接口同步调用的时候,微服务间并没有彻底解耦。要解耦必须是基于事件或消息模式的异步调用方式。
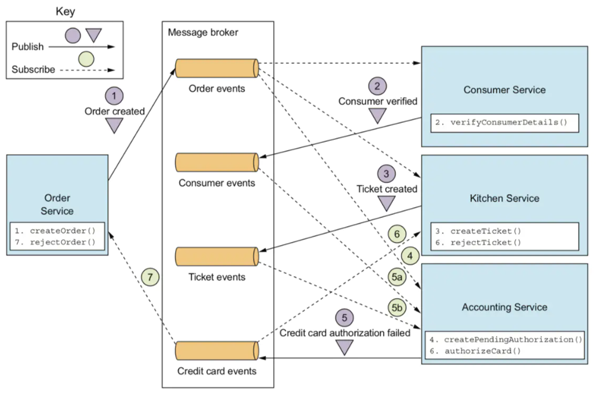
Saga即是一种异步消息事件机制下的分布式事务解决方案。Saga是由一系列的本地事务构成。每一个本地事务在更新完数据库之后,会发布一条消息或者一个事件来触发Saga中的下一个本地事务的执行。如果一个本地事务因为某些业务规则无法满足而失败,Saga会执行在这个失败的事务之前成功提交的所有事务的补偿操作。
Saga的实现有很多种方式,其中最流行的两种方式是:
基于事件的方式。这种方式没有协调中心,整个模式的工作方式就像舞蹈一样,各个舞蹈演员按照预先编排的动作和走位各自表演,最终形成一只舞蹈。
基于命令的方式。这种方式的工作形式就像一只乐队,由一个指挥家(协调中心)来协调大家的工作。协调中心来告诉Saga的参与方应该执行哪一个本地事务。
当重新来思考分布式事务的时候,再次印证我的一个观点,即微服务拆分太细导致引入了很多完全没有必要的分布式事务问题,增加了开发,集成,测试和后续监控运维的工作量和复杂度。
比如书里面谈到的一个例子,对于一个在线订餐系统提交一个订单,这个本身是一个很容易实现的功能,但是在微服务化后,订单提交涉及到用户校验,账户校验,厨房工单生成多个独立API服务接口调用。这个就涉及到这些API接口的事件编排,同时在编排中你还需要考虑出现异常时候的补偿回退,考虑消息执行顺序等诸多问题。
这些急剧了增加了一个功能实现的复杂度。当你本身开发的系统就不存在海量并发和高性能需求的时候,我实在难以找到任何理由将微服务拆分的如此细,引入这么多的复杂度。
实际上以上的分布式事务场景应该更多地应用到大系统间的分布式事务协同上面,比如采购系统提交订单的时候,同时涉及到工作流平台中的工作流实例启动,涉及到预算系统的预算校验,这个时候才要分布式事务来实现是有必要的。
跨系统出现上面这种分布式事务处理和协同场景,这个量完全可控。但是你微服务拆分得太细,你在实现应用中任何一个功能都引入上面这种分布式事务问题,基于事件的编排和补偿问题,可想而知已经不是简单的复杂度问题,而是后期的系统可靠性和可运维问题。
如何彻底解耦?
前面谈到了如果是CUD操作可以异步方式来实现解耦,那么对于查询操作如何处理。如果一个查询查找本身还涉及到多个微服务API接口的组合,这个时候如何实现解耦。
对于查询操作一般来讲都是同步操作,用户端点击查询后会等待数据的返回,这个时候如果需要调用多个微服务API接口数据进行组合,那么底层某个微服务模块如此异常,将直接导致整个查询功能持续异常。
即如果存在查询操作,那么微服务间仍然是紧耦合在一起的。我们希望的微服务间通过消息和异步来彻底解耦这个目标并没有达到。
当然实际上可以考虑两个方法来解决这个问题。
其一就是将常用数据缓存,查询的时候直接访问缓存库。
其二就是将微服务底层数据库需要共享数据进行同步,同步到一个大的共享ODS读库专门来提供查询服务能力。
在一些项目的CQRS命令查询职责分离实践中,基本即采用的这个思路。通过这种方式来实现微服务间的彻底解耦。当然也引入了另外两个依赖点,一个就是消息中间件,一个就是缓存库或分布式ODS读库。这两个点的稳定性就直接影响到整个系统的稳定性。
采用CQRS模式最大的一个问题点就是无法实现命令和查询两部分内容的强一致性保障,即很可能你界面上查询到的数据不是最新的持久化数据库里面的数据,这个本身和消息管道异步写入的实时性又关系。
其次在使用CQRS模式的时候,有一个重要假设就是在事件和命令发出后,无特殊情况在事件接收方都必须要能够接收事件成功处理,否则就存在大量的异常错误消息的异步回写,反而增加系统的复杂度。
实施CQRS引入的整体复杂度,也不是一般的小项目能够玩得起的。
同时对于CQRS框架的实施,不是简单的设计模式和开发复杂度问题,更加重要的仍然是是否能够接受最终一致性要求,同时在该要求下将传统的同步请求下业务功能和逻辑处理机制转变为异步事件价值下的事件链驱动模式。要实现这种转变就必须能够拆分出独立,自治的命令和事件,同时确保这些事件在朝后端业务功能和逻辑模块发送的时候能够处理成功(即该做的校验必须提前做完)。
微服务网关和API网关
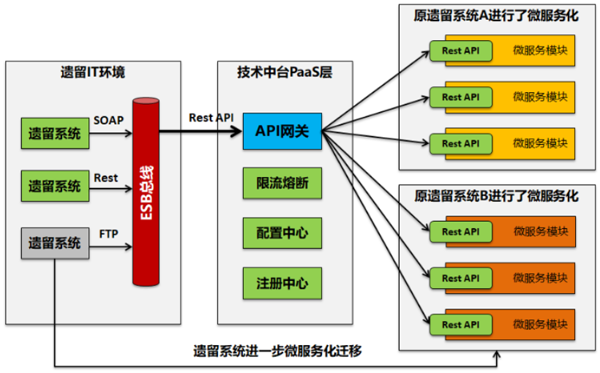
对于API网关也可以先参考我头条发布过的相关文章。
于API网关和微服务网关实际实现的核心功能基本一致,但是要注意到微服务网关一般是在微服务架构体系里面的内容。而API网关一般是可以独立在微服务架构体系之外的内容。
也就是说API网关和微服务整体框架体系更加的松耦合。
API网关一般具备独立的服务注册接入,负载均衡和路由能力,而微服务网关一般则是通过和服务注册中心的集成来实现服务注册发现,负载均衡和路由
应用范围的区别
在这里重新强调下,微服务网关和API网关实际在应用范围上有明显的区别。即微服务网关一般应用在单个微服务应用内部,特别是在存在前后端分离情况下。而对于API网关则是应用在组织级,实现多个微服务应用之间的集成和协同能力。
单个微服务应用,完全没有必要采用API网关,直接使用微服务网关。比如当你采用SpringCLoud框架体系的时候,你直接采用框架里面的Zuul或SpringCLoud Gateway即可。
但是当你在做组织级的多个微服务应用间集成的时候,这个时候需要的脱离单个微服务框架体系的的一个外部集成中间件,因此不能和微服务框架绑定太死。其次你会看到跨应用间的集成管控的粒度不是到微服务组件,而是要细化到一个个的API接口。因此这个时候启用API网关就是必须的。
当你在组织级启用API网关的时候发现一个新问题。
即对于整个组织级来说,遗留系统和单体应用的微服务化本身有个过程,在这个过程中一定是传统架构和微服务架构共存。新的Rest API接口和老的SOAP接口和消息协议共存阶段。而API网关本身对老的接口协议适配能力并不好。对于类似ESB总线来说虽然偏重,但是可以完全兼容和覆盖API网关具备的能力。
因此在这种情况下API网关反而变得鸡肋。
API网关是否该做类似服务编排组合的事情?
简单来说API网关不应该做这件事情,传统的ESB总线往往具备这个能力,但是API网关不适合来承载这个能力。如果做了服务编排的事情一个是让API网关本身从单纯的技术中间件变成了承载业务逻辑的中间件,其次就是该能力本身也将让API网关变得更加重。
因此最好的方法仍然是独立一个微服务来实现服务组合和编排,发布组合后的领域服务或组合服务能力,这个在我前面文章专门有谈到过。
API网关本身的中心化问题
不要简单地认为中心化架构就一定不好,中心化架构本身通过集中管控和拦截的方式,可以很方便地实现类似API接口安全,日志,路由,流控等各种管控能力。
在谈微服务管控治理的时候,中心化的API网关是一个重要的实现思路和手段,当然在前面我也提到了整体的发展趋势应该ServiceMesh化,实现完全的去中心化架构。这个ServiceMesh化本身又可以和DevOps,容器云等云原生技术形成一个完整的整体。
但是要意识到的点仍然是在于组织管控和标准化推进的力度,如果在组织级很多技术标准推进不一致,应用系统改造存在前后逐步演进,那么这个时候你很难简单的去实现ServiceMesh化架构。简单来说即是:
对于传统IT架构的逐步微服务化,本身并不适合采用ServiceMesh。
在谈微服务架构的时候,经常有人谈到完全的去中心化,但是没有搞清楚为啥要去中心化。即使异步消息集成,消息中间件仍然是中心点。当组织级标准规范,技术要求不统一的时候,管控能力达不到时候很难完全去中心化,这个时候中心化方式反而是一个好的选择。
最后,做下简单总结如下:
按照理想化的微服务方法来设计和实施微服务,对于大部分传统企业信息化来说不适用,同样照搬互联网微服务架构化方法同样不适用。企业IT架构在微服务转型过程中更多应该基于业务场景和问题驱动,借鉴微服务拆分和解耦的思想,充分考虑敏捷交付,弹性扩展和性能,开发难度和资源成本投入,后期管控治理多方面的平衡。
来源:
https://www.toutiao.com/i6925193987997696516/