













1. 跳表的概念
跳表是一个动态数据结构,可以支持快速地插入、删除、查找操作,写起来也不怎么复杂,甚至可以替代红黑树。跳表的空间复杂度是 O(n),时间复杂度是 O(logn)。
对于一个有序的单链表来说,如果想要查找一个数据也只能从头到尾遍历链表。为了提高查询的效率,我们可以借助索引,即对链表构建一级索引,比如把每两个链表节点中较小的那个节点提取为一级索引节点(对于 key value 的值来说,可以只保留 key 值),一级索引节点也可以采用同样的方式提取为二级索引节点,如图所示,即为跳表的结构。
针对下图,假如想要查询 10 这个数据,那么先在二级索引层遍历,当遍历到二级索引中 7 这个索引节点之后,发现后面的一个索引节点的值是 13,那么10 这个数据节点肯定是在这两个索引节点之间。然后,我们通过 down 指针,下降到一级索引层继续遍历查找。这个时候遍历到 9 这个一级索引节点,而后面一个索引节点的值是 13,那么则继续通过 down 指针下降到原始链表继续遍历查找,从而找到 10 这个数据。
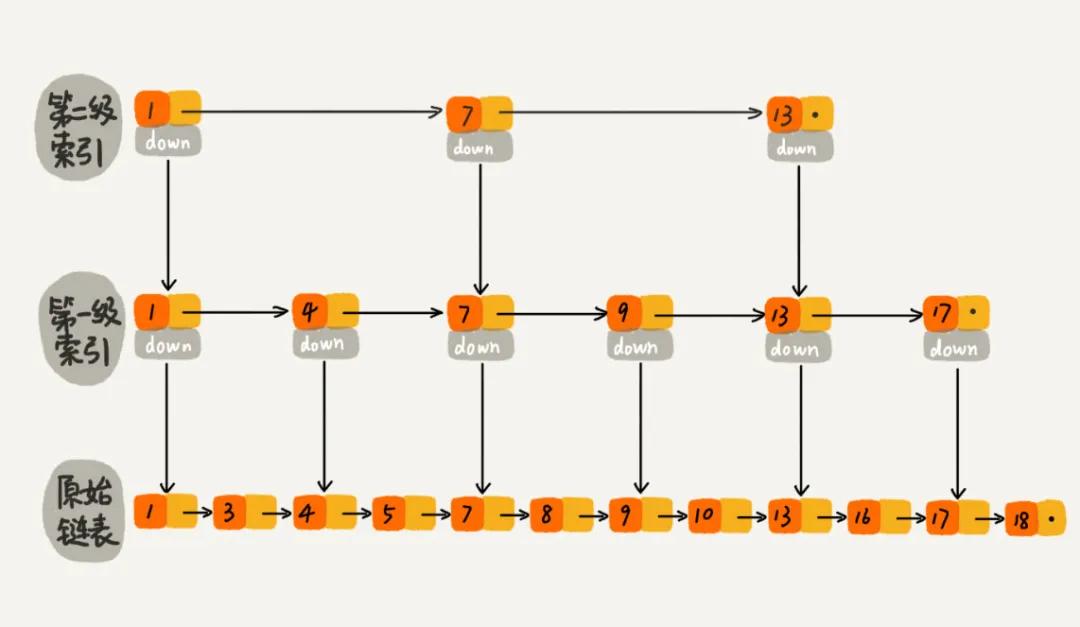
综上所述,跳表是一个值有序的链表建立多级索引之后的一种数据结构,通过上述的查找方式,我们可以看到类似于二叉查找树的查找方式,所以说跳表查找类似于链表的“二分查找”算法。
空间复杂度
假设原始链表大小为 n,那第一级链表有 n/2 个节点,第二季索引有 n/4 个节点,最顶层有 2 个节点。那么总共需要的索引节点个数就是
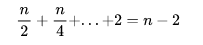
因此,跳表总的空间复杂度还是 O(n),也就说使用跳表查询数据时,需要额外 n 个节点的存储空间。虽然空间复杂度还是没变,但是使用的额外空间还是有点多的。那么,可以采用以下方法来尽可能的降低索引占用的空间复杂度:可以多几个节点抽取成一个节点,比如每 3 个节点或者 5 个节点抽取成一个节点。虽然这样子空间复杂度还是 O(n),但实际上所需的索引节点数量少了好多。
★实际的软件开发中,原始链表中存储的有可能是很大的对象,而索引节点只需要存储关键值和几个指针,并不需要存储对象,这个时候,索引节点所占用的额外空间相比大对象来说其实很小,可以忽略不计。”
2. 跳表的操作
2.1. 查找
单链表查询的时间复杂度是 O(n),那么针对一个具有多级索引的跳表,查询某个数据的时间复杂度是多少呢?能否提高查询的效率呢?
假设链表中有 n 个节点,我们假设每两个节点抽出一个节点作为上一级的索引节点,那么第一级的索引节点个数是 n/2,第二级的索引节点个数是 n/2^2。依次类推,第 k 级的索引节点个数是 n/2^k。假设索引层最高有 h 级,而最高层的索引节点有 2 个节点,那么得到 ,加上原始链表这一层,一共有 层。
我们在跳表中查询某个数据的时候,如果每一层都要编译 m 个,那么跳表一个数据的时间复杂度就是 O(mlogn)。由于我们是每两个节点抽出一个节点,而且最高层也只有两个节点,所以每一层最多比较 3 个节点。比如我们要查找的数据是 x,当在第 k 级索引层遍历到 y 节点之后,发现 x 大于 y 但是小于 y 后面的 z 节点,那么则通过 y 的down 指针从 k 级索引下降到 k-1 级索引,而在 k-1 级索引中最多只需要遍历 3 个节点即可。
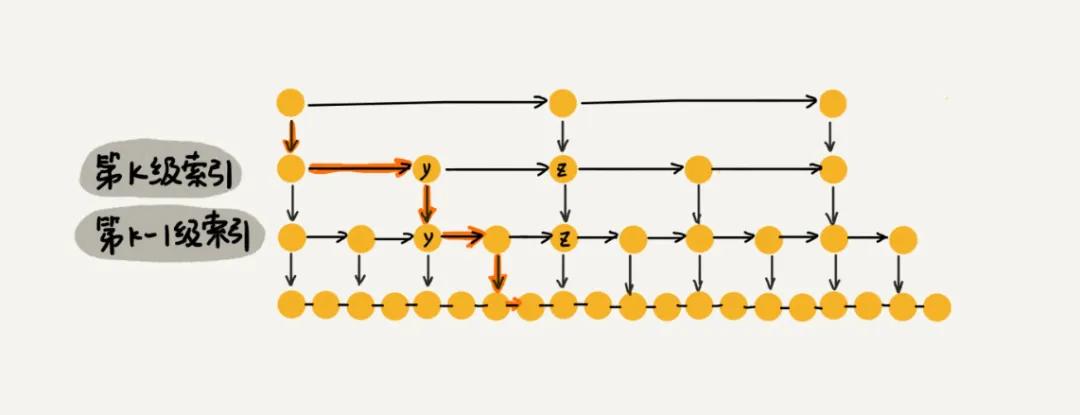
因此,在跳表中查询数据的时间复杂度是 O(logn),这个时间复杂度和二分查找是一样的。不过,这种查询效率的提升,提前是建立了很多级索引,使用了空间换时间的设计思路。
2.2. 插入
在单链表中,假如定位到了要插入的位置,那么插入节点这个操作的时间复杂度很低,为 O(1)。但是要定位到插入的位置的时间复杂度是 O(n),比如原始链表中数据有序,那么需要遍历链表才能找到要插入的位置。
对于跳表来说,由于查找某个节点的时间复杂度是 O(logn),而插入实际上就是链表中的插入,因此插入操作的时间复杂度也就是 O(logn)。
2.3. 删除
删除操作也是类似的,但是如果这个节点在索引中也有出现的话,除了要删除原始链表中的节点之外,还要删除索引中的。由于删除节点需要前驱节点,因此使用双向链表的话,可以很方便的删除一个节点。
综上,删除操作的时间复杂度也可以做到 O(logn)。
2.4. 索引更新
当我们不停地往跳表中插入数据而不更新索引节点的话,那么 2 个索引节点之间的数据可能会非常的多。极端情况下,跳表可能会退化为单链表。因此,我们需要某种手段来维护索引与原始链表大小之间的平衡,也就是说如果链表中的节点变多了,索引节点也相应地增加一些,避免查找、插入、删除的性能下降。
跳表通过随机函数的方式来维护这种平衡性。当我们往跳表中插入数据的时候,我们通过一个随机函数,来决定将这个在哪几层索引层中添加。比如随机函数生成了值 k,那么我们就在第一级到第 k 级这 k 级索引中添加相应的索引节点。
★对于平衡二叉树来说,比如红黑树、AVL,它们是通过左右旋的方式来保持左右子树的平衡。”
3. 应用
Redis 中的有序集合就是用跳表来实现的,另外还用到了散列表。为什么使用跳表而不是红黑树实现呢?最主要的是跳表它支持区间查找。
Redis 中的有序集合支持的核心操作中主要有:
- 插入、删除、查找一个数据;
- 按照区间查找数据(比如查找值在 [100, 356] 之间的数据)
- 迭代输出有序序列
其中插入、删除、查找操作,红黑树也可以很快完成,时间复杂度也是 O(logn)。但是按照区间来查找数据这个操作,红黑树的效率没有跳表高。跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。
★实际上,在有序集合中,每个成员对象有两个重要的属性:key 和 value。我们有时候不仅需要通过 value 来查找数据,还会通过 key 来查找数据。我们可以按照 value 将成员对象组织成跳表的结构,那么此时根据 value 来查找对象很方便,但是当我们想要通过 key 查找对象时又会很麻烦。那么,我们可以结合散列表,也就相当于把散列表和跳表结合。此时,根据 key 来查找、删除、插入一个成员对象的时间复杂度就变成了 O(1)。”
4. 总结
跳表是一种动态数据结构,使用了空间换时间的设计思想来提高查询的效率,简单来说就是在原始链表的基础之上构建了多级索引层来提高查询的效率,在查找方式上有点类似于二分查找。
综上,跳表的查询、插入、删除的时间复杂度都是 O(logn),而空间复杂度是 O(n)。
5. 参考
https://juejin.im/post/6844903446475177998
本文转载自微信公众号「多选参数」,可以通过以下二维码关注。转载本文请联系多选参数公众号。


















