研究人员表明,通过在每个视频帧中插入被称为对抗性样本(adversarial examples )的输入,探测器就可以被击败。对抗性的例子是稍微被操纵的输入,会导致人工智能系统,如机器学习模型犯错误。此外,研究小组还发现,在视频被压缩后,这种攻击仍然有效。
来自UC San Diego 的计算机工程专业博士生 Shehzeen Hussain 说:
我们的研究表明,对deepfake探测器的攻击可能是对真实世界的威胁,更令人震惊的是,我们证明,即使不知道探测器使用的机器学习模型的内部工作原理,也有可能制造出非常robust的对抗样本。

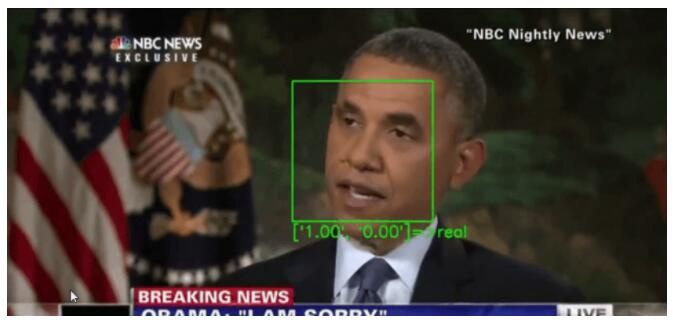
在deepfake中,主体的脸部被修改,以创造令人信服的真实事件当中的镜头,而这些事件从未真正发生过。
因此,典型的deepfakes探测器会将焦点集中在视频中的人脸上: 首先跟踪它,然后将裁剪后的人脸数据传递给神经网络,由神经网络来判断这些人脸是真是假。
例如,眨眼在deepfakes中不能很好地复制,所以探测器将注意力集中在眼睛的运动上,以此作为确定假的一种方法。最先进的“deepfakes探测器”依靠机器学习模型来识别假视频。
研究人员指出,虚假视频在社交媒体平台上的广泛传播引起了全世界的重大关切,尤其是影响了媒体的可信度。
“如果攻击者对探测系统有一定的了解,他们就可以设计输入信号,瞄准探测器的盲点,并绕过它,”论文的另一位合著者、来自加州大学圣地亚哥分校计算机科学专业的学生帕尔斯 · 尼卡拉(Paarth Neekhara)说。
研究人员为视频画面中的每一张脸创建了一个对抗性的样本。但是,虽然标准的操作,例如视频压缩和调整大小,通常会从图像中去除对抗性的样本,这些例子是建立来承受这些过程的。
攻击算法通过估计一组输入转换来实现这一点,模型将图像排序为真或假。从那里,它使用这种估计转换图像的方式,使得即使在压缩和解压缩后,对抗性的图像仍然有效。
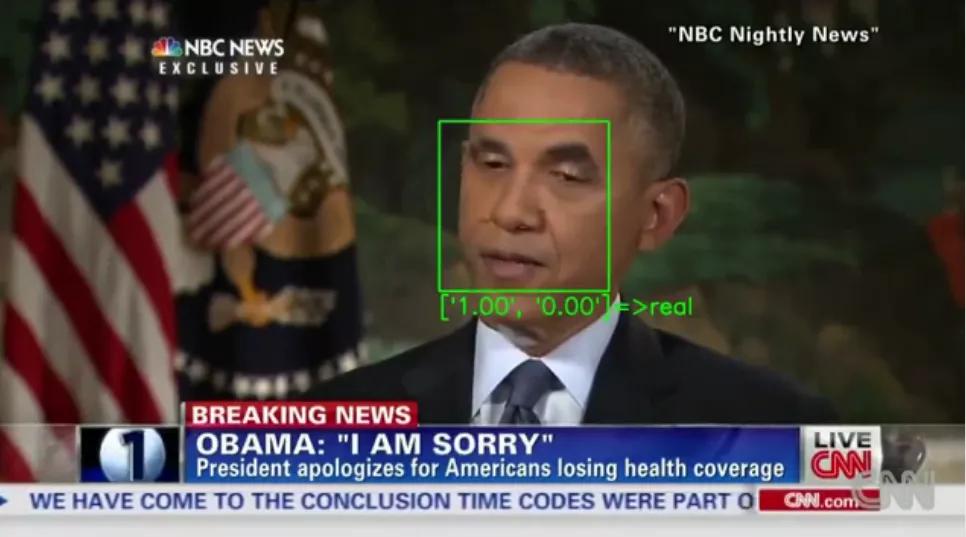
XceptionNet,一个deepfake探测器,将研究人员制作的对抗性视频标记为真。
将修改后版本的面部插入到所有的视频帧,然后对视频中的所有帧重复这个过程,以创建一个deepfake的视频。这种攻击还可以应用于对整个视频帧进行操作的探测器,而不仅仅是对面部。
成功率高
研究人员在两个场景中测试了他们的攻击: 一个场景中攻击者可以完全访问检测器模型,包括人脸提取pipeline和分类模型的结构和参数; 另一个场景中攻击者只能查询机器学习模型来计算被分类为真或假的帧的概率。
在第一种情况下,对未压缩视频的攻击成功率超过99% 。对于压缩视频,这个比例是84.96% 。在第二种情况下,对未压缩视频攻击的成功率为86.43% ,压缩视频的成功率为78.33% 。
这是第一个展示了成功攻击最先进的deepfake探测器的工作。

“为了在实践中使用这些deepfake探测器,我们认为,有必要对这些探测器进行评估,以对抗一个了解这些防御的适应性对手,这个对手正在有意地试图挫败这些防御”,研究人员表示,“如果敌方对探测器有完全甚至部分的了解,目前最先进的deepfake探测方法可以很容易地被绕过。”
为了改进探测器,研究人员还推荐了一种类似于对抗性训练的方法: 在训练期间,一个适应性的对手继续生成新的deepfake结果,这些假的结果可以绕过当前最先进的探测器; 为了检测新的deepfake结果,探测器继续改进。