













本文转载自微信公众号「程序员小饭」,作者饭米粒 。转载本文请联系程序员小饭公众号。饭米粒
前言
buffer pool是什么
咱们在使用mysql的时候,比如很简单的select * from table;这条语句,具体查询数据其实是在存储引擎中实现的,大家都知道mysql数据其实是放在磁盘里面的,如果每次查询都直接从磁盘里面查询,这样势必会很影响性能,所以一定是先把数据从磁盘中取出,然后放在内存中,下次查询直接从内存中来取。但是一台机器中往往不是只有mysql一个进程在运行的,很多个进程都需要使用内存,所以mysql中会有一个专门的区域来处理这些数据,这个专门为mysql准备的区域,就叫buffer pool。
buffer pool的工作流程
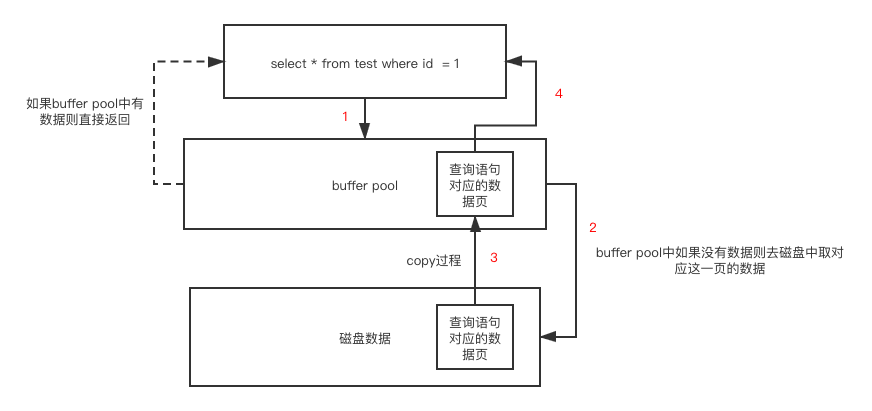
咱们以查询语句为例 1:在查询的时候会先去buffer pool(内存)中看看有没有对应的数据页,如果有的话直接返回 2:如果buffer pool中没有对应的数据页,则会去磁盘中查找,磁盘中如果找到了对应的数据,则会把该页的数据直接copy一份到buffer pool中返回给客户端 3:下次有同样的查询进来直接查找buffer pool找到对应的数据返回即可。
大家看到这里相信应该对buffer pool有了个大概的认识,有没有感觉有点缓存的感觉,当然buffer pool可没有缓存那么简单,内部结构还是比较复杂的,不过没关系,咱们继续往下看。
buffer pool数据管理
数据管理的基本单位
buffer pool毕竟是一种内存管理,数据当然不是按照一条一条的sql语句来管理的,而是按照数据页来管理的,innodb 引擎默认的数据页是16kb,而buffer pool启动的时候是默认的128M,所以是有8192个数据页的。而磁盘的数据管理也是用数据页为单位来管理的,所以每次查找数据的时候,先请求buffer pool,buffer pool中没有的话会到磁盘中找到对应的数据页,然后copy到buffer pool中给客户端返回。
free链表
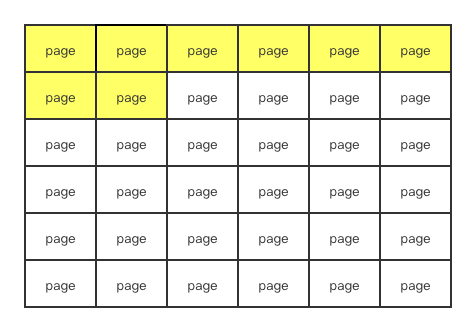
正常情况下,buffer pool肯定是从第一个数据页,不断的往后填充的,一个一个的往后写入,每次直接在后面追加就可以了。如下图(黄色部分表示已经写入数据)
但是实际生产环境中,并不是这样的,我们不光有查询操作,还有删除,修改等操作,而且已经写入buffer pool的数据不一定是始终有价值的,有一些数据是不需要的,需要释放对应的数据页的,所以就会造成buffer pool的数据其实是这种情况,间断不连续的。
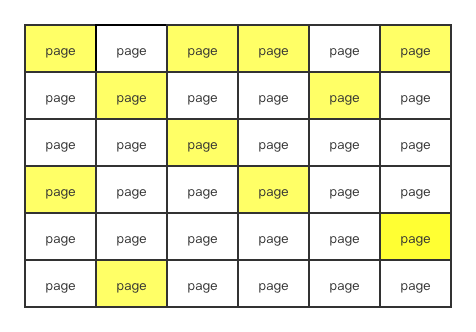
在这种情况下该如何去找到有效的空闲的数据页空间来存储数据呢?最直观的方法就是从第一个页遍历的一个一个的往后找,找到空闲的数据页即可,这种方法倒是可行,但是非常影响效率,所以mysql在处理这种问题用上了free链表的方式来管理空闲的数据页。
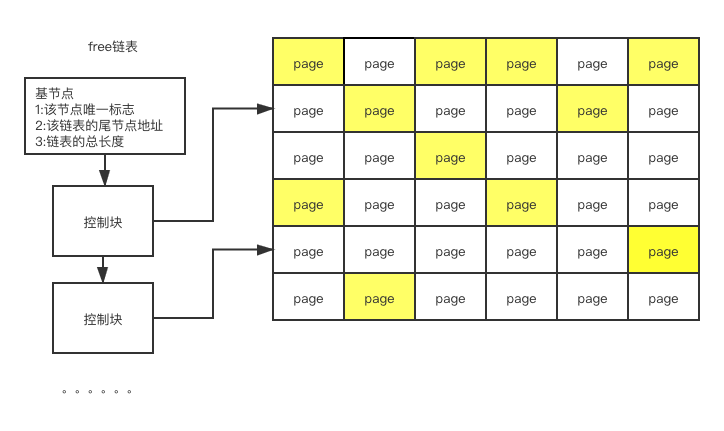
大家可以看一看free链表的结构
- free链表有一个基节点,记录了该free链表的唯一标志,该链表的尾节点地址,以及链表的总长度
- 基节点后面会有很多的控制块,控制块本身很小,只是存储了指向空闲数据页的指针而已,所以buffer pool在寻找空闲数据页的时候直接用free链表可以直接找到。
- 只要有一页数据空闲出来之后,直接把该数据页的地址追加到free链表即可。
flush链表
当然只是用free链表是解决不了所有问题的,比如:我们在执行update table test set field_a = 1;的时候,我们是先修改buffer pool里面对应的数据页,然后再更新磁盘中对应的数据页的,(当然这里会涉及到一个数据一致性的问题,mysql是用redo log解决的,这个不在咱们这篇文章的讨论范围之内)我们把buffer pool中对应修改的数据页同步修改到磁盘的时候,这个过程称之为"刷脏",刷脏是有一定策略的,可以用
select @@innodb_flush_log_at_trx_commit;
- 1.
来查看刷脏策略

我们一般都不会设置实时写,这样很影响性能,所以一般都是延迟写的,那么就会引发一个问题,mysql是如何在buffer pool中找到被修改过的脏数据的呢?这里咱们就用上了flush链表了,其实和free链表比较像
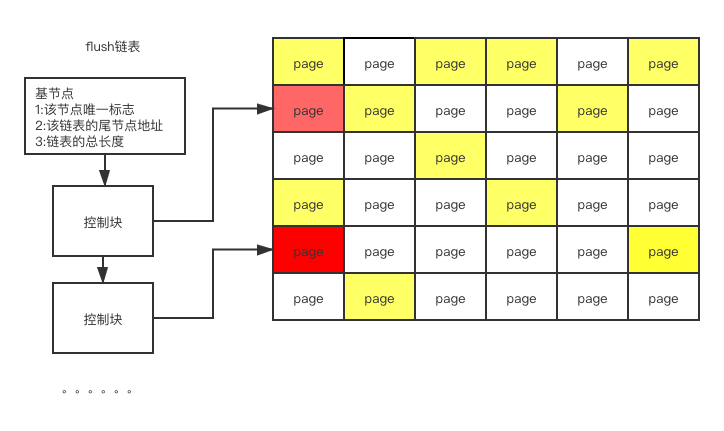
flush链表上面维护的都是脏数据页的指针。刷脏的时候直接遍历flush链表去刷脏就可以了。
lru链表
buffer pool是有一定空间限制的,默认是128M,总会有空间塞满的时候的,所以数据页是有淘汰机制的,淘汰机制就是lru(最近最少使用)。
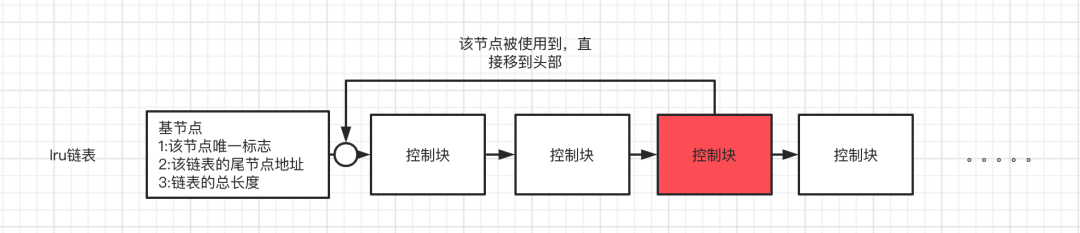
lru原理其实也很简单,使用到过的数据页,直接移动到链表的头部,然后在buffer pool满了之后直接淘汰掉链表尾部的数据页就可以了。
lru链表的优化
其实简单的lru链表是存在一定的问题的,比如咱们在工作过程中,可能会用上 select * from test这样的语句来进行一些刷数据等需求,如果test表是非常大的,很有可能一下子把buffer pool占满,把之前的数据页全部都淘汰掉,然后其余的数据在线上业务正常执行的时候,又会回来重新把之前select * from test 占用的数据页重新慢慢淘汰掉,这一来一去是非常影响线上的性能的。
所以鉴于以上所在的问题,mysql的buffer pool是在lru的基础上进行了一些优化的。
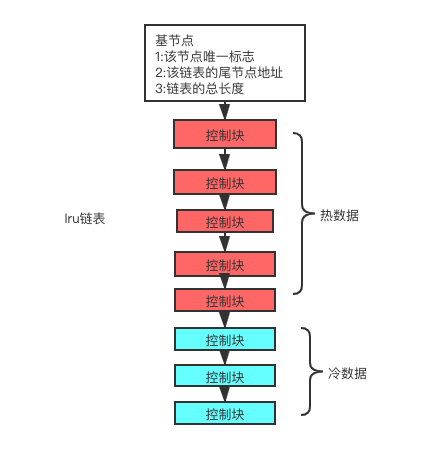
buffer pool的lru链表把数据分为了热数据块和冷数据块,比例大概5:3的样子,每次新的数据页写入都会写入冷数据区。
但是如果这样的话那么热数据区永远都不会有数据,所以冷数据区写入的时候会另外记录上写入的时间,下次访问该数据区的时候如果时间间隔大于1s,那么就会放入热数据区,这样就不会淘汰掉大量的无辜数据。所以我们在执行select * from test这种语句刷新脚本的时候,只会占用冷数据的空间,而不会影响到热数据。




















