被寄予厚望的深度学习,是否会让人工智能陷入又一轮 AI 寒冬?
人工智能存在于许多我们每天与之交互的技术中,比如最常见的语音助手和个性化推荐,以及不断成熟的自动驾驶。从去年到现在,AI 领域更是好消息不断,OpenAI 的 GPT-3 从自然语言处理衍生出了画画、敲代码等能力,DeepMind 推出「进阶版 AlphaGo」——MuZero,它在下棋和游戏前完全不知道游戏规则,完全通过自己摸索赢得棋局。一时间,「AI 将替代人类」的声音不绝于耳。
但另一面,人类丰满的 AI 梦,也正在撞上骨感的现实。近期,IBM 旗下的 Watson Health 被传出将甩手卖掉,这个曾想替人类解决肿瘤治疗的 AI 部门 6 年来从未盈利。更致命的是,Watson Health 的诊断精度和专家结果只有 30% 的重合。
看向国内,「AI 四小龙」中的商汤科技和旷视科技,时不时传出计划上市的消息,但似乎都中了「上市难」的魔咒。旷视科技的创始人印奇在去年 7 月,曾对媒体表示 AI 的快速爆发期发生在五六年前,现在正处于「死亡之谷」的泡沫期。繁荣表象之外的冰冷现实,都能让人想到「人工智能的寒冬」:与 AI 有关的研究或其他项目难以获得资金,人才和公司停滞不前。
清华大学人工智能研究院院长张钹曾表示,行业崇尚深度学习,但它本身的「缺陷」决定了其应用的空间被局限在特定的领域——大部分都集中在图像识别、语音识别。而目前深度学习似乎已经到了瓶颈期,就算财力和算力仍在不断投入,但深度学习的回报率却没有相应的增长。
「目前基于深度学习的人工智能在技术上已经触及天花板,此前由这一技术路线带来的『奇迹』在 AlphaGo 获胜后未再出现,而且估计未来也很难继续大量出现。」张钹说。
被寄予厚望的深度学习,是否会让人工智能陷入又一轮寒冬?「在每一次人工智能『寒冬』到来之前,科学家都会夸大他们的研究的潜力。仅仅说他们的算法擅长某一项任务还不够,他们恨不得说 AI 能解决所有事。」长期研究数据科学和 AI 的作者 Thomas Nield 说道。但真正的通用人工智能,离我们似乎还很遥远。
深度学习是什么?
就在 AI 慢慢沉寂,变成「隐学」的时候,Geoffrey Hinton、Yoshua Bengio 和 Yann LeCon 三位学者默默开始了 AI 的一个重要分支——神经网络——的研究。
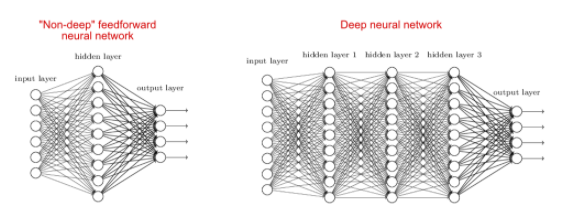
神经网络通常被比喻成一块有很多层的三明治,每层都有人工神经元,这些神经元在兴奋时会把信号传递给相连的另一个神经元
简单来说,神经网络就是一层层的数字,这些数字又被称为「神经元」。之所以这样命名,是因为科学家认为这些数字相互联系,传递信号,就像大脑里的神经元通过突触来传递神经刺激一样。而神经网络里的每一层数字都通过一些约定的数学规则从上一层的数字计算得到。
而「深度学习」的概念源于神经网络的研究,是研究神经网络的学问。这里的「深度」,指的就是神经网络含有无数隐层,深不可测。
机器要模拟人类行为,要先获取数据,然后经过预处理、特征提取、特征选择,再到推理、预测或识别。其中最关键的,就是中间的三个步骤,同时也是系统中最耗费计算的部分。在现实中,一般都是靠人工提取特征,而深度学习的思路是自动学习特征。
深度学习模型一般由输入层,隐层和输出层构成。基本思想是:上一层的输出作为下一层的输入,来实现对输入信息的分级表达,进而通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征。也就是说,机器学会「抽象思考」了。
上述三位 AI 泰斗坚持着自己的学术方向,把神经网络推广到了更多的领域,比如计算机视觉、自然语言处理等等。终于在几十年后,他们等来了属于深度学习的时代。互联网和移动端的兴起让海量的数据唾手可得,而计算机硬件在人类一次又一次挑战着纳米世界的极限中,顺着摩尔的预言一路狂奔。2012 年,深度学习暴得大名,因为 Geoffrey Hinton 基于卷积神经网络的 AlexNet 以惊人优势赢下 ImageNet 视觉识别挑战赛。另外在这个实验中,人们发现,只有图像的样本量够大,隐层够多,识别率就能大幅提高,这极大地鼓舞了学界和企业。
数据越多,越智能?
OpenAI 最新的自然语言处理模型 GPT-3,几乎是把整个互联网的浩瀚内容全部读完了。它总共阅读了大约 5000 亿词,模型大概有 1750 亿参数。系统有上万个 CPU/GPU,它们 24 小时不间断地「阅读」任何领域的信息,半个月读完了整个互联网的内容。猛灌数据量,是这个 AI 模型的「暴力」所在。

但 GPT-3 也并不能因此变得完全像人,比如,它对不符合人类常理的「伪问题」也会应答,这恰恰证明它并不理解问题本身。前 Uber 人工智能实验室的负责人 Gary Marcus 就曾对深度学习多次泼冷水:「人类可以根据明确的规律学习,比如学会一元二次方程的三种形式以后就可以用来解各种题目;见过了京巴、柴犬之后,再见到德牧就知道它也是一种狗。然而深度学习不是这样的,「越多的数据 = 越好的模型表现」,就是深度学习的基本规律,它没有能力从字面上给出的规律学习。」
「深度学习是寻找那些重复出现的模式,因此重复多了就被认为是规律(真理),因此谎言重复一千遍就被认为真理,所以为什么大数据有时会做出非常荒唐的结果,因为不管对不对,只要重复多了它就会按照这个规律走,就是谁说多了就是谁。」张钹院士也表示深度学习「没有那么玄」。
由于它不能真正理解知识,「深度学习学到的知识并不深入,而且很难迁移。」Marcus 说道。而 AI 系统动辄拥有千亿参数,俨然就是一个黑匣子一般的谜。深度学习的不透明性将引致 AI 偏见等系列问题。最主要的是,AI 还是要为人所用,「你要它做决策,你不理解它,飞机就让它开,谁敢坐这架飞机?」张钹强调 AI 必须拥有可解释性。
最主要的是,给 AI 猛灌数据的做法极其考验算力。MIT 研究人员理解深度学习性能和算力之间的联系,分析了 Arxiv.org 上的 1058 篇论文和资料,主要分析了图像分类、目标检测、问题回答、命名实体识别和机器翻译等领域两方面的计算需求:
每一网络遍历的计算量,或给定深度学习模型中单次遍历(即权值调整)所需的浮点运算数。
训练整个模型的硬件负担,用处理器数量乘以计算速度和时间来估算。
结论显示,训练模型的进步取决于算力的大幅提高,具体来说,计算能力提高 10 倍相当于 3 年的算法改进成果。换言之,算力提高的背后,其实现目标所隐含的计算需求——硬件、环境和金钱等成本将变得无法承受。
摩尔定律假定计算能力每两年翻一番。OpenAI 一项研究表明,AI 训练中使用的计算能力每三到四个月翻一番。自 2012 年以来,人工智能要求计算能力增加三十万倍,而按照摩尔定律,则只能将 AI 提升 7 倍。人们从来没有想到芯片算力极限会这么快到来。
算力供不起是一回事,但业界甚至认为这种「暴力」模式方向错了。「知识、经验、推理能力,这是人类理性的根本。现在形成的人工智能系统都非常脆弱容易受攻击或者欺骗,需要大量的数据,而且不可解释,存在非常严重的缺陷,这个缺陷是本质的,由其方法本身引起的。」张钹表示,「深度学习的本质就是利用没有加工处理过的数据用概率学习的『黑箱』处理方法来寻找它的规律,它只能找到重复出现的模式,也就是说,你光靠数据,是无法达到真正的智能。」
深度学习红利将尽,但 AI 还在发展
在张钹看来,既然深度学习在根子上就错了,那么技术改良也就很难彻底解决 AI 的根本性缺陷。正是这些缺陷决定了其应用的空间被局限在特定的领域——大部分都集中在图像识别、语音识别两方面。「我看了一下,中国人工智能领域 20 个独角兽 30 个准独角兽企业,近 80% 都跟图像识别或者语音识别有关系。」
他表示,「只要选好合适的应用场景,利用成熟的人工智能技术去做应用,还有较大的空间。目前在学术界围绕克服深度学习存在的问题,正展开深入的研究工作,希望企业界,特别是中小企业要密切注视研究工作的进展,及时地将新技术应用到自己的产品中。当然像谷歌、BAT 这样规模的企业,他们都会去从事相关的研究工作,他们会把研究、开发与应用结合起来。」
一直在给深度学习泼冷水的 Gary Marcus, 提出要为深度学习祛魅:「我不认为我们就要放弃深度学习。相反,我们需要将它重新概念化:它不是一种万能药,而仅仅是作为众多工具中的一种,在这个世界上,就像我们还需要锤子、扳手和钳子。」
「深度学习只是目前人工智能技术的一部分,人工智能还有更大更宽的领域需要去研究,知识表示、不确定性处理、人机交互,等等一大片地方,不能说深度学习就是人工智能。」张钹说。
另外,中科院自动化研究所副所长刘成林曾表示,「如今的 AI 热潮其实主要依赖模式识别和深度学习的成功。深度学习的红利将逐渐用尽,但 AI 的很多方向(感知、认知、学习语言理解、机器人、混合智能、博弈等)还会继续发展,总体上不会跌入深谷。