随着 Facebook 的 DETR (ECCV 2020)[2] 和谷歌的 ViT (ICLR 2021)[3] 的提出,Transformer 在视觉领域的应用开始迅速升温,成为当下视觉研究的第一热点。但视觉 Transformer 受限于固定长度的位置编码,不能像 CNN 一样直接处理不同的输入尺寸,这在很大程度上限制了视觉 Transformer 的应用,因为很多视觉任务,如检测,需要在测试时动态改变输入大小。
一种解决方案是对 ViT 中位置编码进行插值,使其适应不同的图片大小,但这种方案需要重新 fine-tune 模型,否则结果会变差。
最近,美团提出了一种用于视觉 Transformer 的隐式条件位置编码 CPE [1],放宽了显式位置编码给输入尺寸带来的限制,使得 Transformer 便于处理不同尺寸的输入。实验表明,应用了 CPE 的 Transformer 性能优于 ViT 和 DeiT。
论文地址:https://arxiv.org/pdf/2102.10882.pdf
项目地址:https://github.com/Meituan-AutoML/CPVT(即将开源)
背景
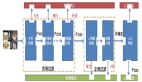
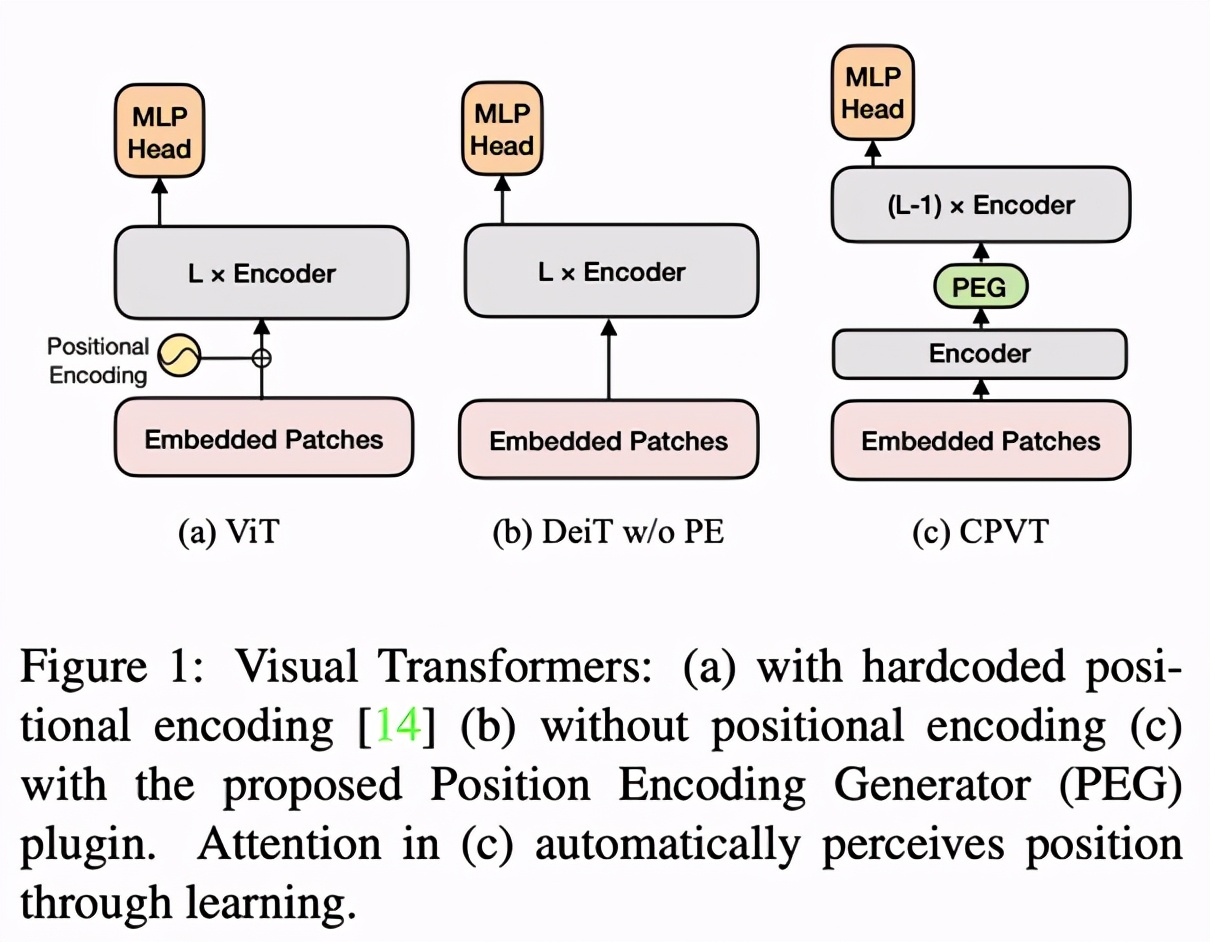
谷歌的 ViT 方法通常将一幅 224×224 的图片打散成 196 个 16×16 的图片块(patch),依次对其做线性编码,从而得到一个输入序列(input sequence),使 Transformer 可以像处理字符序列一样处理图片。同时,为了保留各个图片块之间的位置信息,加入了和输入序列编码维度等长的位置编码。DeiT [4] 提高了 ViT 的训练效率,不再需要把大数据集(如 JFT-300M)作为预训练的限制,Transformer 可以直接在 ImageNet 上训练。
对于视觉 Transformer,位置编码不可或缺
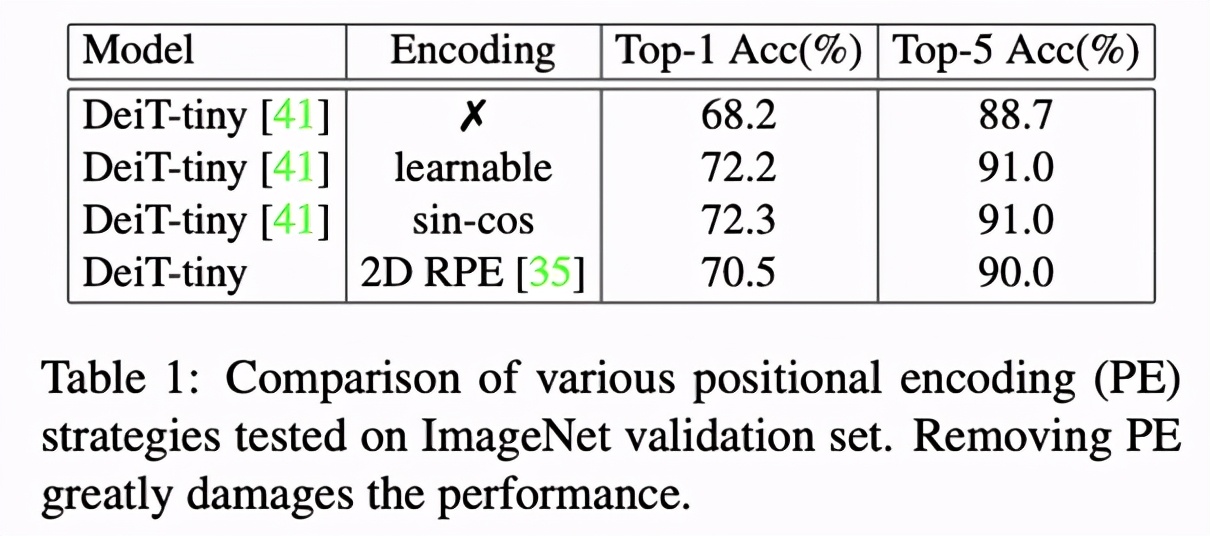
在 ViT 和 CPVT 的实验中,我们可以发现没有位置编码的 Transformer 性能会出现明显下降。除此之外,在 Table 1 中,可学习(learnable)的位置编码和正余弦(sin-cos)编码效果接近,2D 的相对编码(2D RPE)性能较差,但仍然优于去掉位置编码的情形。
美团、阿德莱德大学提出新型位置编码方法
位置编码的设计要求
显式的位置编码限制了输入尺寸,因此美团这项研究考虑使用隐式的根据输入而变化的变长编码方法。此外,它还需要满足以下要求:
保持很好的性能;
避免排列不变性(permutation equivariance);
易于实现。
基于上述要求,该研究提出了条件编码生成器 PEG(Positional Encoding Generator),来生成隐式的位置编码。
生成隐式的条件位置编码
在 PEG 中,将上一层 Encoder 的 1D 输出变形成 2D,再使用变换模块学习其位置信息,最后重新变形到 1D 空间,与之前的 1D 输出相加之后作为下一个 Encoder 的输入,如 Figure 2 所示。这里的变换单元(Transoformation unit)可以是 Depthwise 卷积、Depthwise Separable 卷积或其他更为复杂的模块。
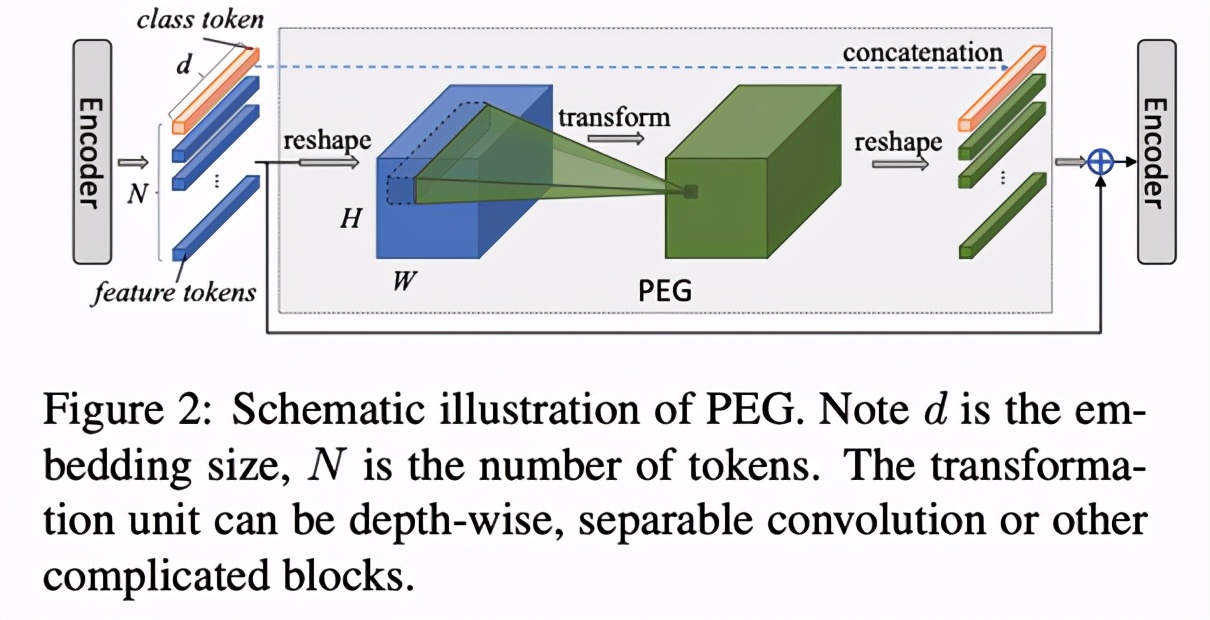
将 PEG 插入到模型中(如 Figure 1 中添加在第一个 Encoder 后),即可对各个 Encoder 添加位置编码信息。这种编码好处在于不需要显式指定,长度可以依输入变化而变化,因此被称为隐式的条件位置编码。
实验
ImageNet 数据集
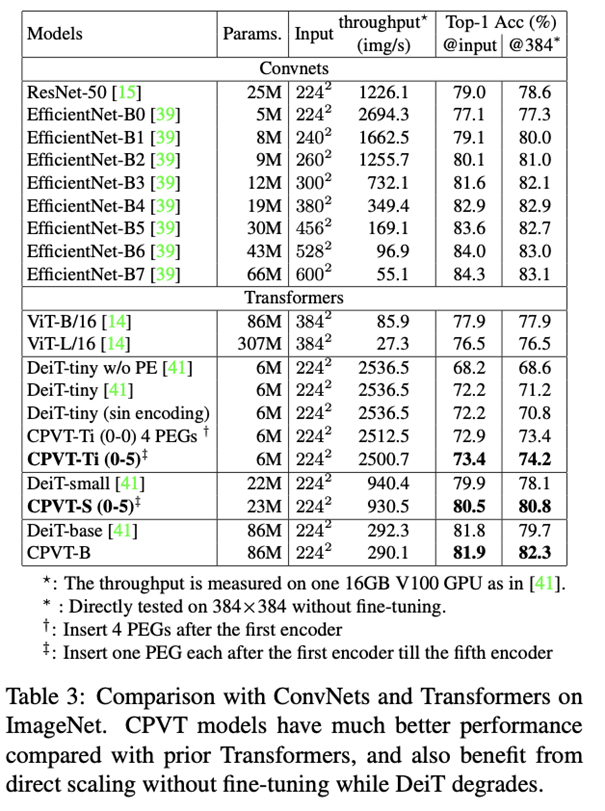
该研究将添加了 PEG 的 Vision Transformer 模型命名为 CPVT(Conditional Position encodings Visual Transformer)。在 ImageNet 数据集上,相同量级的 CPVT 模型性能优于 ViT 和 DeiT。得益于隐式条件编码可以根据输入动态调整的特性,基于 224×224 输入训练好的模型可以直接处理 384×384 输入(Table 3 最后一列),无需 fine-tune 就能直接获得性能提升。相比之下,其他显式编码没有 fine-tune 则会出现性能损失。
与其他编码方式的对比
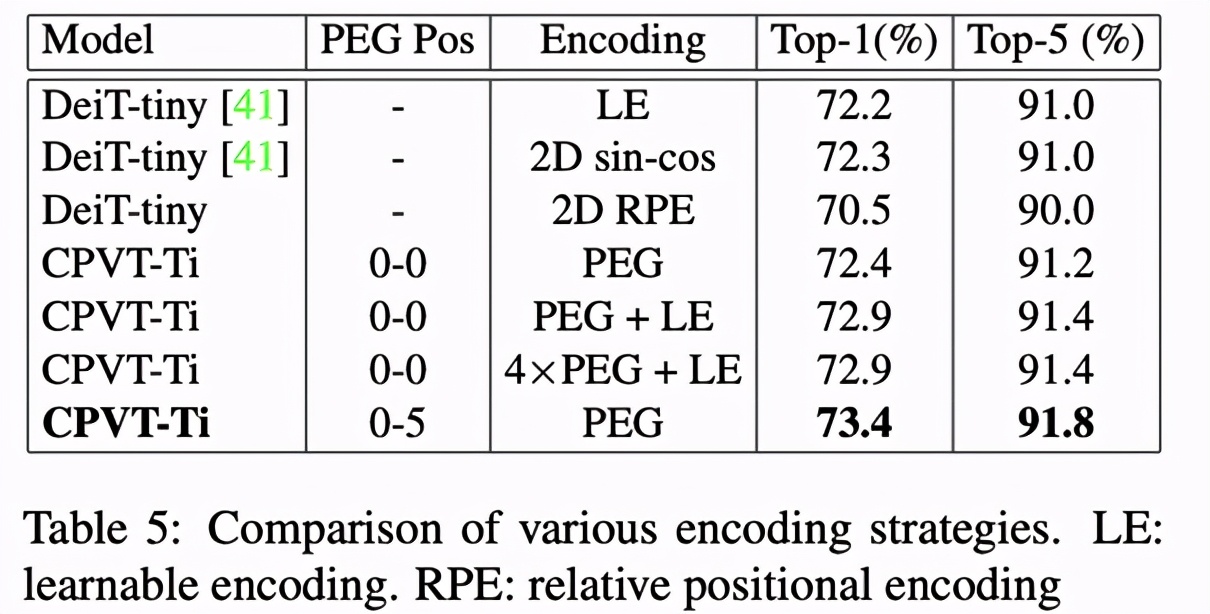
Table 5 给出了 CPVT-Ti 模型在不同编码策略下的表现。其中在从第 0 个到第 5 个 Encoder 各插入一个 PEG 的性能最优,Top-1 准确率达到 73.4%。CPVT 单独使用 PEG 或与可学习编码相结合也优于 DeiT-tiny 在各种编码策略下的表现。
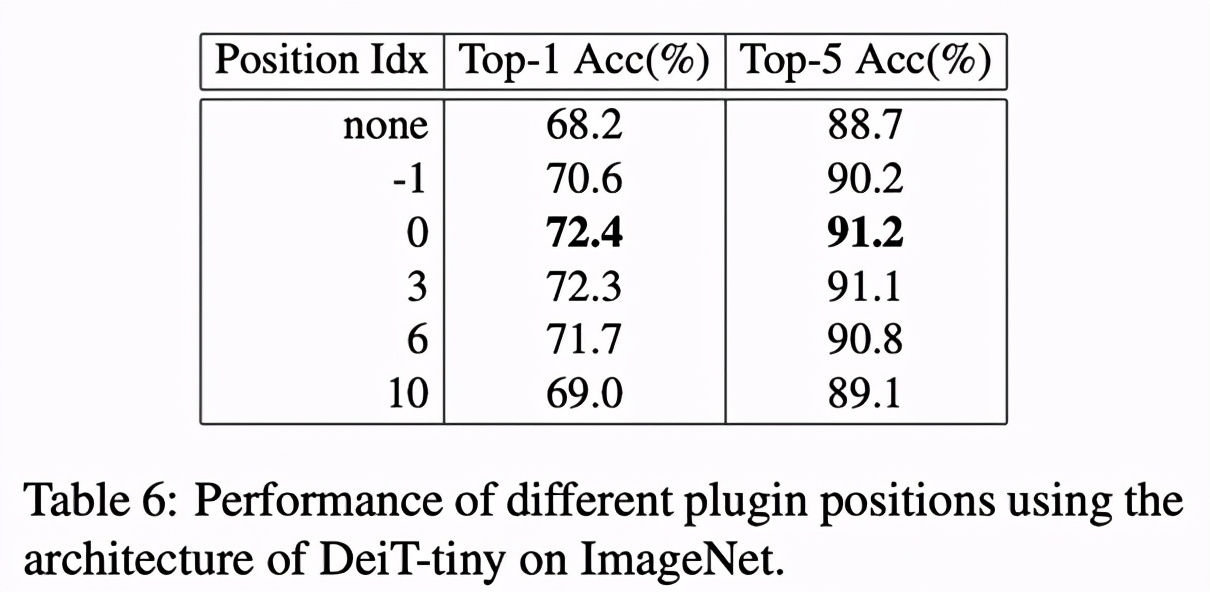
PEG 在不同位置的作用
ViT 主干由 12 个 Encoder 组成,CPVT 对比了 PEG 位于 -1、0、3、6、10 等处的结果。实验表明,PEG 用于第一个 Encoder 之后表现最好 (idx 0)。该研究认为,放在第一个 encoder 之后不仅可以提供全局的接受域,也能够保证模型尽早地利用到位置信息。
结论
CPVT 提出的隐式位置编码是一个即插即用的通用方法。它放宽了对输入尺寸的限制,因而有望促进 Vision Transformer 在分割、检测、超分辨率等任务中的进一步应用,提升其性能。这项研究对后续 Vision Transformer 的发展将产生积极的影响。