本文转载自微信公众号「码农私房话」,作者GoQeng 。转载本文请联系码农私房话公众号。
通常情况下,SQL 慢查询一般只会导致应用服务响应变慢,但在去年双十一活动时,我碰到了一个慢查询把整个网站搞崩溃的问题。

慢查询请求流程
案发现场
在去年双十一晚,我突然收到产品经理的“催魂电话”并告知:整个网站的页面一直在转菊花,无法显示数据,吓得我立马掏出电脑。
登录服务器后竟发现服务内存占用率接近 100%,CPU 长期负荷高,我迅速地检查是否代码中出现死循环、大对象内存泄露等问题,但经过排查发现代码是正常。
接着使用 jstatck pid 命令把线程堆栈信息 dump 出来,发现很多业务线程均处于 BLOCKED 状态,同时也用 jstat -gcutil 观察到 FULL GC 相当频繁。
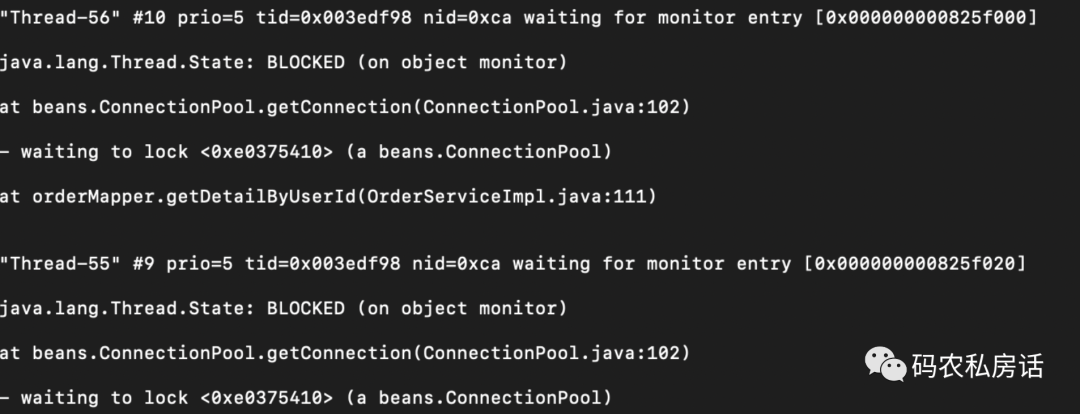
jstack 线程堆栈
经分析 dump 文件的内容及代码,发现是线程无法获取数据库连接,大量处于等待状态。
随后使用 show processlist 命令发现某个 SQL 查询耗时接近 10s 多,查询的表数据量约在 1500W 左右。
我迫不及待地分析了慢 SQL select * from t_order where merchant_id= 1349865679 limit 0 10; 从表面看起来似乎用到了索引,可是为什么扫描到行还是这么多呢?
我就去看看表结构,期望能从中找到点有价值的东西,通过 show index from t_order;后发现以下有用的信息:

从上述结果中看到 merchant_id 索引的离散程度还算大,它的 Cardinality 值接近于 PRIMARY 的值,说明是比较正常的。
既然 merchant_id 索引没问题,那么猜想就是使用姿势不对的问题,我再通过 explain select * from t_order WHERE merchant_id= 1349865679 limit 0,10; 分析运行的SQL,发现确实索引没生效。

最后经过耐心地对比代码与 SQL 后,发现 SQL 中 merchant_id 传的是整形,而数据库实际上是字符串,于是我更改字段值为字符串,再次执行 explain select * from t_order WHERE merchant_id= '1349865679' limit 0,10; ,发现索引居然生效了。

此时我自信不疑,就是字段类型转换导致的慢查询,MySQL 不会自动帮我们做字段值类型转换,定位出原因后,剩下只需要把字段的值改为字符串就可以了。
慢查询会造成系统奔溃?
1、TCP 连接、端口耗尽,无法响应请求
首先我们先看看请求的流程:

从上述图可发现,用户的请求在服务器等待数秒后才向数据库发起执行命令,而当时双十一活动火爆,请求量高,导致数据库连接耗尽,大量请求阻塞在服务器上,同时系统不断地创建 TCP 连接,这些连接直至整个请求结束后才会释放、销毁。因此,当堆积大量请求无法及时处理时,则出现服务无法响应,进一步恶化为资源挂占。
2、对象在堆内存无法回收,导致内存不足
相信大家知道,每个用户发出请求、执行逻辑时都需分配 JVM 内存,当前面的请求线程处于阻塞时,后面又越来越多新请求不断申请内存分配,但旧请求中的对象无法回收并释放内存,最终导致内存暴涨、系统响应缓存,进一步演化为系统奔溃,整个请求过程如下:
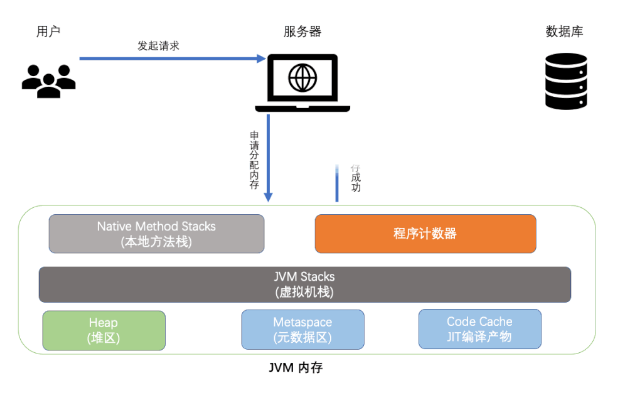
请求时线程申请资源流程
为什么会出现慢查询?
在遇到慢查询的情况时, SQL 编写问题是最常见的因素,但实际上导致慢 SQL 有很多因素,甚至包括硬件和 MySQL 本身的 Bug 等,以下情况都有可能导致慢 SQL 的出现:
- SQL 编写问题
- 锁竞争激烈
- 业务实例相互干绕,争用 IO/CPU 资源
- 服务器硬件配置
- MySQL Bug
而本次的问题是属于 SQL 编写导致,其根本原因是索引使用不当,查询时进行全表扫描。
如何优化 SQL 编写的慢查询
针对 SQL 编写导致的慢查询,正确地使用索引就能加快查询速度,避免全表扫描。
SQL 全表扫描数据流程
然而在编写 SQL 时需要注意与索引相关的一些规则:
- 字段类型转换导致索引失效,如字符串类型的不用引号,数字类型的用引号等,这可能使索引失效导致全表扫描;
- MySQL 不支持函数转换,因此索引字段上不能加函数,否则这将用不到索引;
- 不在索引字段上做计算,对于需要计算的字段,可考虑将计算方法放在“=”后面;
- like 模糊查询,一般禁止使用 % 前导,防止索引失效,如 like %liew;
- 不使用 select *,应按需加载需要的字段,查询无用的列在数据传输和解析绑定过程中会增加网络IO及CPU的开销;
- 排序请尽量使用升序 ,因为倒序多了文件排序操作,执行效率变低,而 MySQL 8 开始支持降序索引解决排序性能问题;
- 尽量使用 union 代替 or,使用 or 可能会导致放弃使用索引而全表扫描;
- 最左匹配原则,索引是有顺序的,查询条件中缺失索引列之后的,其他条件都不会走索引,比如(a, b, c)索引,只使用b, c索引,就不会走索引;
- 在 order by / group by 子查询的字段尽量建立索引,减少文件排序;
除了上述索引使用规则外,在编写 SQL 时还需要特别注意一下几点:
- 尽量规避大事务的 SQL,大事务的 SQL 会影响数据库的并发性能及主从同步;
- 删除表所有记录请使用 truncate,而不用 delete,因为 truncate 执行时不会生成 UNDO 信息;
- 在 InnoDB 引擎上请谨慎使用 select count(*) 语句,该统计可能会全表扫描数据,而 MyISAM内置了一个计数器可直接获取总数;
- 慎用 oder by rand(),因为 rand() 放在 order by 子句中会被执行多次,效率很低;
- 负向查询一般都不会走索引,如 !=, <>, not in, not like等;
- 删除不再使用或很少使用的索引,从而减少索引对更新操作的影响;
避免、发现慢查询的措施
针对 SQL 编写导致的慢查询,正确地使用索引能加快查询速度,避免全表扫描。
在工作中,每个公司使用 MySQL 的版本可能都大不相同,总会存在一些莫名其妙、不确定的问题,因此为了验证索引的有效性,推荐把主要的 SQL 都通过 explain 命令查看一下执行计划,是否会用到索引。
- explain select * from t_order WHERE merchant_id= '1349865679' limit 0 , 10;

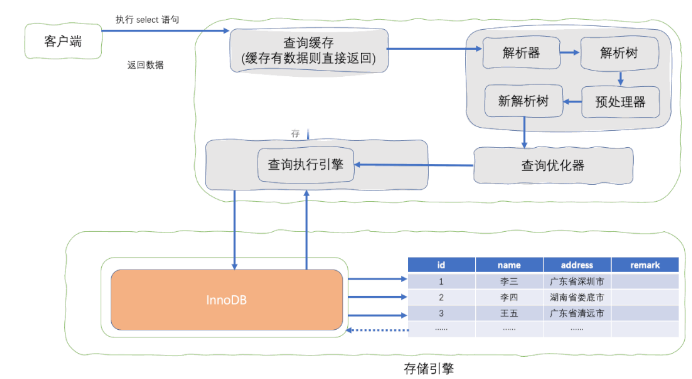
然而 explain 工具分析的结果只是 MySQL 评估反馈的执行计划,最终还是依赖 MySQL 执行引擎会根据一定算法落地:
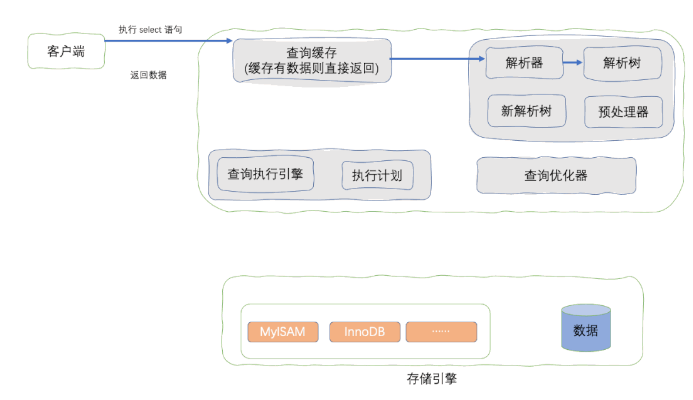
SQL 执行流程
因此有可能 explain 分析的结果显示索引生效,但实际执行 SQL 语句时却是全表扫描。
这时候就需要开启 MySQL 的慢查询功能,再通过监控工具 Zabbix 或Grafana辅助及时发现慢查询 SQL 、连接数过多等问题并告警 。
写在最后
慢查询的破坏力很大,轻则出现系统响应缓慢,重则导致系统瘫痪、无法使用。
因此在日常开发中,我们需合理地设计、使用索引,避免出现慢查询,同时利用工具实时监控数据库的连接数、慢查询语句等,并建立告警机制,以便能主动地及时发现、定位问题,尽可能减少给客户带来的损失。