又是一年跳槽季,最近听到最多的消息就是,我们公司又有同事离职了,所以,如果你想在职场上掌握主动权,你就需要比别人更加努力,更加夯实的技能基础,不然你拿什么去跟别人拼?所以,今天我们跟大家分享一些前端基础知识,希望对你有所帮助。
HTML页面的生命周期
HTML页面的生命周期有以下三个重要事件:
- DOMContentLoaded —— 浏览器已经完全加载了 HTML,DOM 树已经构建完毕,但是像是
<img> 和样式表等外部资源可能并没有下载完毕。
- load —— 浏览器已经加载了所有的资源(图像,样式表等)。
- beforeunload —— 当用户即将离开当前页面(刷新或关闭)时触发。正要去服务器读取新的页面时调用,此时还没开始读取;
- unload —— 在用户离开页面后触发。从服务器上读到了需要加载的新的页面,在即将替换掉当前页面时调用。
- 每个事件都有特定的用途:
- DOMContentLoaded —— DOM 加载完毕,所以 JS 可以访问所有 DOM 节点,初始化界面。
- load —— 附加资源已经加载完毕,可以在此事件触发时获得图像的大小(如果没有被在 HTML/CSS 中指定)
- beforeunload —— 该事件可用于弹出对话框,提示用户是继续浏览页面还是离开当前页面。
- unload —— 删除本地数据localstorage等
DOMContentLoaded
DOMContentLoaded 由 document 对象触发。使用 addEventListener 来监听它:
- document.addEventListener("DOMContentLoaded", () => {});
DOMContentLoaded 和脚本
当浏览器在解析 HTML 页面时遇到了<script>...</script> 标签,将无法继续构建DOM树(UI 渲染线程与 JS 引擎是互斥的,当 JS 引擎执行时 UI 线程会被挂起),必须立即执行脚本。所以 DOMContentLoaded 有可能在所有脚本执行完毕后触发。
外部脚本(带 src 的)的加载和解析也会暂停DOM树构建,所以 DOMContentLoaded 也会等待外部脚本。带 async 的外部脚本,可能会在DOMContentLoaded事件之前或之后执行。带 defer 的脚本肯定会在在DOMContentLoaded事件之前执行。
DOMContentLoaded 与样式表
外部样式表并不会阻塞 DOM 的解析,所以 DOMContentLoaded 并不会被它们影响。
load
window 对象上的 load 事件在所有文件包括样式表,图片和其他资源下载完毕后触发。
- window.addEventListener('load', function(e) {...});
- window.onload = function(e) { ... };
beforeunload
当窗口即将被卸载(关闭)时, 会触发该事件。此时页面文档依然可见, 且该事件的默认动作可以被取消。beforeunload在unload之前执行,它还可以阻止unload的执行。
- // 推荐使用
- window.addEventListener('beforeunload', (event) => {
- // Cancel the event as stated by the standard.
- event.preventDefault();
- // Chrome requires returnValue to be set.
- event.returnValue = '关闭提示';
- });
- window.onbeforeunload = function (e) {
- e = e || window.event;
- // 兼容IE8和Firefox 4之前的版本
- if (e) {
- e.returnValue = '关闭提示';
- }
- // Chrome, Safari, Firefox 4+, Opera 12+ , IE 9+
- return '关闭提示';
- };
unload
用户离开页面的时候,window 对象上的 unload 事件会被触发,无法阻止用户转移到另一个页面上。
- // 推荐使用
- window.addEventListener("unload", function(event) { ... });
- window.onunload = function(event) { ... };
readyState
document.readyState 表示页面的加载状态,有三个值:
- loading 加载 —— document仍在加载。
- interactive 互动 —— 文档已经完成加载,文档已被解析,但是诸如图像,样式表和框架之类的子资源仍在加载。
- complete —— 文档和所有子资源已完成加载。 load 事件即将被触发。
可以在 readystatechange 中追踪页面的变化状态:
- document.addEventListener('readystatechange', () => {
- console.log(document.readyState);
- });
Script标签:向HTML插入JS的方法
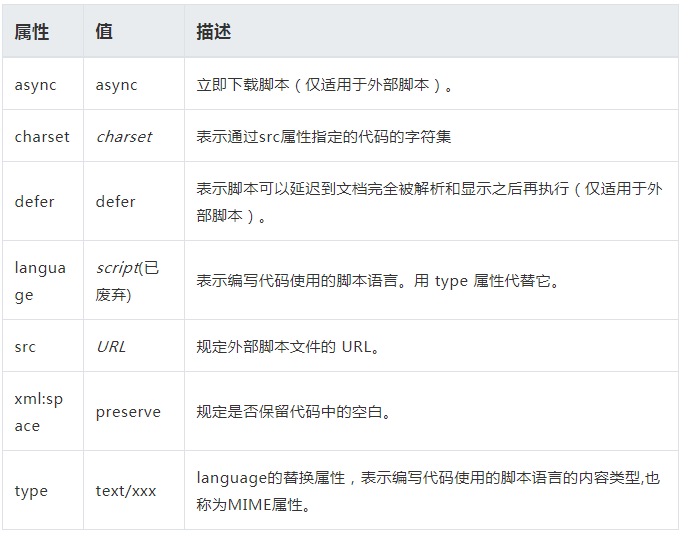
没有 defer 或 async,所有<script>元素会按照在页面出现的先后顺序依次被解析,浏览器会立即加载并执行指定的脚本, 只有解析完前面的script元素的内容后,才会解析后面的代码。
async 和 defer 属性仅仅对外部脚本起作用,在 src 不存在时会被自动忽略。
使用<script>的两种方式
1.页面中嵌入script代码, 只需指定type属性
- <script type="text/javascript">
- function sayHi() {
- console.log('hihihi');
- // 内部不能出现'</script>'字符串,如果必须出现,必须使用转义标签‘\’
- alert('<\/script>');
- }
- </script>
包含在<script>元素内的代码会从上而下依次解释,在解释器对<script>元素内的所有代码求值完毕之前,页面中的其余内容都不会被浏览器加载或显示
2.包含外部js文件, src属性是必须的。
- <script src="example.js"></script>
- // 带有src属性的元素不应该在标签之间包含额外的js代码,即使包含,只会下载并执行外部文件,内部代码也会被忽略。
与嵌入式js代码一样, 在解析外部js文件时,页面的处理会暂时停止。
改变脚本行为的方法
1. defer: 立即下载,延迟执行
加载和渲染后续文档元素的过程将和脚本的加载并行进行(异步),但是脚本的执行会在所有元素解析完成之后。脚本总会按照声明顺序执行。
在DOMContentLoaded事件之前执行。
- <script defer="defer" src="example.js"></script>
2. async: 异步脚本
加载和渲染后续文档元素的过程将和脚本的加载与执行并行进行(异步)。但是async 在下载完毕后的执行会阻塞HTML的解析。脚本加载后马上执行,不能保证异步脚本按照他们在页面中出现的顺序执行。
一定会在load事件之前执行,可能会在DOMContentLoaded事件之前或之后执行。
- <script async="async" src="example.js"></script>
区别:

meta
META标签是HTML标记HEAD区的一个关键标签,它提供的信息虽然用户不可见,但却是文档的最基本的元信息。<meta> 除了提供文档字符集、使用语言、作者等网页相关信息外,还可以设置信息给搜索引擎,目的是为了SEO(搜索引擎优化)。
HTML<meta> 元素表示那些不能由其它 HTML 元相关(meta-related)元素((<base>、<link>, <script>、<style> 或 <title>)之一表示的任何元数据信息。
属性
name
设置元数据的名称。name 和 content 属性可以一起使用,以名-值对的方式给文档提供元数据,content 作为元数据的值。
content
设置与 http-equiv 或 name 属性相关的元信息。
charset
声明了文档的字符编码。如果使用了这个属性,其值必须是与ASCII大小写无关(ASCII case-insensitive)的"utf-8"。
http-equiv
定义了一个编译指示指令,其作用类似于http协议, 告诉浏览器一些关于字符设定,页面刷新,cookie,缓存等等相关信息。属性名叫做 http-equiv 是因为所有允许的值都是HTTP头部的名称。可设置的值有:
- content-security-policy:它允许页面作者定义当前页的内容策略。内容策略主要指定允许的服务器源和脚本端点,这有助于防止跨站点脚本攻击。
- Expires:可以用于设定网页的到期时间,一旦过期则必须到服务器上重新调用。content必须使用GMT时间格式;
- content-type:如果使用这个属性,其值必须是"text/html; charset=utf-8"。注意:该属性只能用于 MIME type为 text/html 的文档,不能用于MIME类型为XML的文档。
- default-style:设置默认CSS 样式表组的名称。
- refresh:定时让网页在指定的时间n内,刷新或跳转;
如果 content 只包含一个正整数,则是n秒后, 页面刷新。
如果 content 包含一个正整数,并且后面跟着字符串 ';url=' 和一个合法的 URL,则是重定向到指定链接的时间间隔(秒)。
meta 元素定义的元数据的类型包括以下几种:
- 如果设置了 name 属性,meta 元素提供的是文档级别(document-level)的元数据,应用于整个页面。
- 如果设置了 http-equiv 属性,meta 元素则是编译指令,提供的信息与类似命名的HTTP头部相同。
- 如果设置了 charset 属性,meta 元素是一个字符集声明,告诉文档使用哪种字符编码。
- 如果设置了 itemprop 属性,meta 元素提供用户定义的元数据。
注意: 全局属性 name 在 元素中具有特殊的语义;另外, 在同一个 标签中,name, http-equiv 或者 charset 三者中任何一个属性存在时,itemprop 属性不能被使用。
使用
content值里有多个属性通过,隔开,同时设置多个属性。
- /* name */
- // 适配移动设备
- <meta name="viewport" content="width=device-width,initial-scale=1.0,minimum-scale=1.0,maximum-scale=1.0,user-scalable=no" />
- // 检测html格式:禁止把数字转化为拨号链接
- <meta name="format-detection" content="telephone=no" />
- /* charset */
- <meta charset="utf-8">
- /* http-equiv */
- <meta http-equiv="refresh" content="3;url=https://www.mozilla.org">
- <meta http-equiv="Expires" content="Mon,12 May 2001 00:20:00 GMT">
meta viewport元信息
什么是 viewport?
viewport 是浏览器的可视区域,可视区域的大小是浏览器自己设置的。它可能大于移动设备可视区域,也可能小于移动设备可视区域。一般来讲,移动设备上的viewport都是大于移动设备可视区域。在控制台输出window.innerWidth查看Viewport大小。
相关概念
设备像素:设备屏幕分辨率。iphone6p 的分辨率是 1334*750;
设备独立像素:设备上程序用来描绘数据的一个个的“点”, 在控制台用 screen.width/height查看。iphone6p 的设备独立像素是375*667;
设备像素比(DPR):设备像素(宽)/设备独立像素(宽),DPR越高渲染越精致。在控制台输出window.devicePixelRatio查看设备像素比。iphone6s 的设备像素比就是 750 / 375 = 2;
CSS像素:浏览器使用的单位,用来精确度量网页上的内容。在一般情况下(页面缩放比为 1),1 个 CSS 像素等于 1 个设备独立像素。
屏幕尺寸:屏幕对角线的长度,以英尺为单位。
像素密度(PPI):每英寸屏幕拥有的像素数。
为什么要使用meta viewport?
通常情况下,移动设备上的浏览器都会把viewport设为980px或1024px,此时页面会出现横向滚动条,因为移动设备可视区域宽度是比这个默认的viewport的宽度要小。所以出现了meta 标签设置viewport 元始性进行移动端网页优化。
meta viewport 属性
width:控制 viewport 的大小,可以给它指定一个值(正整数),或者是一个特殊的值(如:device-width 设备独立像素宽度,单位缩放为 1 时);
initial-scale:初始缩放比例,即当页面第一次加载时的缩放比例,为一个数字(可以带小数);
maximum-scale:允许用户缩放到的最大比例,为一个数字(可以带小数);
minimum-scale:允许用户缩放到的最小比例,为一个数字(可以带小数);
user-scalable:是否允许用户手动缩放,值为 "no"(不允许) 或 "yes"(允许);
height:与 width 相对应(很少使用)。
基本类型和引用类型
基本类型
基本类型:undefined、null、string、number、boolean、symbol
特点
1.基本类型的值是不可变得
- // 任何方法都无法改变一个基本类型的值
- let name = 'jay';
- name.toUpperCase(); // 输出 'JAY'
- console.log(name); // 输出 'jay'
2.基本类型的比较是值的比较
- // 只有在它们的值相等的时候它们才相等
- let a = 1;
- let b = true;
- console.log(a == b); //true
- // 用==比较两个不同类型的变量时会进行一些类型转换。
- // 先会把true转换为数字1再和数字1进行比较,结果就是true了
3.基本类型的变量是存放在栈区的(栈区指内存里的栈内存)
引用类型
引用类型:Object、Array、RegExp、Date、Function等
引用类型也可以说是对象。对象是属性和方法的集合,也就是说引用类型可以拥有属性和方法,属性又可以包含基本类型和引用类型。
特点
1.引用类型的值是可变的
- // 我们可为为引用类型添加属性和方法,也可以删除其属性和方法
- let person = { name: 'pig' };
- person.age = 22;
- person.sayName = () => console.log(person.name);
- person.sayName(); // 'pig'
- delete person.name;
2.引用类型的比较是引用的比较
- let person1 = '{}';
- let person2 = '{}';
- console.log(person1 == person2); // 字符串值相同,true
- let person1 = {};
- let person2 = {};
- console.log(person1 == person2); // 两个对象的堆内存中的地址不同,false
3.引用类型的值是同时保存在栈内存和堆内存中的对象
javascript和其他语言不同,其不允许直接访问内存中的位置,也就是说不能直接操作对象的内存空间。实际上,是操作对象的引用,所以引用类型的值是按引用访问的。准确地说,引用类型的存储需要内存的栈区和堆区(堆区是指内存里的堆内存)共同完成,栈区内存保存变量标识符和指向堆内存中该对象的指针,也可以说是该对象在堆内存的地址。
作用域和执行上下文
JavaScript代码的整个执行过程,分为两个阶段,代码编译阶段与代码执行阶段。
- 编译阶段:由编译器完成,将代码翻译成可执行代码。这个阶段作用域规则会确定。
- 执行阶段:由引擎完成,主要任务是执行可执行代码。执行上下文在这个阶段创建。
作用域
简单来说作用域就是一个区域,没有变量。作用域可以嵌套。作用域规定了如何查找变量,也就是确定当前执行代码对变量的访问权限。作用域在函数定义时就已经确定了,不是在函数调用确定。
ES6 之前 JavaScript 只有全局作用域和函数作用域。ES6 后,增加了块级作用域(最近大括号的作用范围), 通过let 和 const 声明的变量。
作用域其实由两部分组成:
- 记录作用域内变量信息(假设变量,常量,函数等统称为变量)和代码结构信息的东西,称之为 Environment Record。
- 一个引用 __outer__,这个引用指向当前作用域的父作用域。全局作用域的 __outer__ 为 null。
词法作用域
JavaScript 采用词法作用域(lexical scoping),也就是静态作用域。
所谓词法(代码)作用域,就是代码在编写过程中体现出来的作用范围,代码一旦写好了,没有运行之前(不用执行),作用范围就已经确定好了,这个就是所谓的词法作用域。
词法作用域的规则:
- 函数允许访问函数外部的数据
- 整个代码结构中只有函数才能限定作用域
- 作用规则首先使用变量提升规则分析
- 如果当前作用规则里面有该名字,则不考虑外面的外面的名字
- var a = 1;
- function out() {
- var a = 2;
- inner();
- }
- function inner() {
- console.log(a)
- }
- out(); //====> 1
作用域链
当查找变量的时候,会先从当前上下文的变量对象中查找,如果没有找到,就会从父级(词法层面上的父级)执行上下文的变量对象中查找,一直找到全局上下文的变量对象,也就是全局对象。这样由多个执行上下文的变量对象构成的指针链表就叫做作用域链。
作用域链本质上是一个指向当前环境与上层环境的一系列变量对象的指针列表(它只引用但不实际包含变量对象),作用域链保证了当前执行环境对符合访问权限的变量和函数的有序访问。
例子:
用一个数组scopeChain来表示作用域链,数组的第一项scopeChain[0]为作用域链的最前端,而数组的最后一项,为作用域链的最末端,所有的最末端都为全局变量对象。
- var a = 1;
- function out() {
- var b = 2;
- function inner() {
- var c = 3;
- console.log(a + b + c);
- }
- inner();
- }
- out();
首先,代码开始运行时就创建了全局上下文环境,接着运行到out()时创建 out函数的执行上下文,最后运行到inner()时创建 inner函数的执行上下文,我们设定他们的变量对象分别为VO(global),VO(out), VO(inner)。
当函数创建时,执行上下文为:
- // 全局上下文环境
- globalEC = {
- VO: {
- out: <out reference>, // 表示 out 的地址引用
- a: undefined
- },
- scopeChain: [VO(global)], // 作用域链
- }
- // out 函数的执行上下文
- outEC = {
- VO: {
- arguments: {...},
- inner: <inner reference>, // 表示 inner 的地址引用
- b: undefined
- },
- scopeChain: [VO(out), VO(global)], // 作用域链
- }
- // inner 函数的执行上下文
- innerEC = {
- VO: {
- arguments: {...},
- c: undefined,
- },
- scopeChain: [VO(inner), VO(out), VO(global)], // 作用域链
- }
执行上下文
简单来说,当在代码执行阶段执行到一个函数的时候,就会进行准备工作,这里的“准备工作”,就叫做"执行上下文(EC)",也叫执行上下文环境,也叫执行环境。js引擎创建了执行上下文栈(Execution context stack,ECS)来管理执行上下文。
当调用一个函数时,一个新的执行上下文就会被创建。而一个执行上下文的生命周期可以分为两个阶段:
- 创建阶段:在这个阶段,执行上下文会分别创建变量对象,建立作用域链,以及确定this的指向。
- 代码执行阶段:开始执行代码,会完成变量赋值,函数引用,以及执行其他代码。
特点
- 处于活动状态的执行上下文环境只有一个, 只有栈顶的上下文处于活动状态,执行其中的代码。
- 函数每调用一次,都会产生一个新的执行上下文环境。
- 全局上下文在代码开始执行时就创建,只有唯一的一个,永远在栈底,浏览器窗口关闭时出栈。
- 函数被调用的时候创建上下文环境。
变量对象
变量对象的创建过程
- 建立arguments对象。检查当前上下文中的参数,建立该对象下的属性与属性值。
- 检查当前上下文的函数声明,也就是使用function关键字声明的函数。在变量对象中以函数名建立一个属性,属性值为指向该函数所在内存地址的引用。如果函数名的属性已经存在,那么该属性将会被新的引用所覆盖。
- 检查当前上下文中的变量声明,每找到一个变量声明,就在变量对象中以变量名建立一个属性,属性值为undefined。如果该变量名的属性已经存在,为了防止同名的函数被修改为undefined,则会直接跳过,原属性值不会被修改。
活动对象
变量对象与活动对象其实都是同一个对象,只是处于执行上下文的不同生命周期。不过只有处于函数调用栈栈顶的执行上下文中的变量对象,才会变成活动对象。
执行上下文栈
执行上下文可以理解为当前代码的执行环境,JavaScript中的运行环境大概包括三种情况:
- 全局环境:JavaScript代码运行起来会首先进入该环境
- 函数环境:当函数被调用执行时,会进入当前函数中执行代码
- eval
在代码开始执行时,首先会产生一个全局执行上下文环境,调用函数时,会产生函数执行上下文环境,函数调用完成后,它的执行上下文环境以及其中的数据都会被销毁,重新回到全局执行环境,网页关闭后全局执行环境也会销毁。其实这是一个压栈出栈的过程,全局上下文环境永远在栈底,而当前正在执行的函数上下文在栈顶。
- var a = 1; // 1.进入全局上下文环境
- function out() {
- var b = 2;
- function inner() {
- var c = 3;
- console.log(a + b + c);
- }
- inner(); // 3. 进入inner函数上下文环境
- }
- out(); // 2. 进入out函数上下文环境
以上代码的执行会经历以下过程:
- 当代码开始执行时就创建全局执行上下文环境,全局上下文入栈。
- 全局上下文入栈后,其中的代码开始执行,进行赋值、函数调用等操作,执行到out()时,激活函数out创建自己的执行上下文环境,out函数上下文入栈。
- out函数上下文入栈后,其中的代码开始执行,进行赋值、函数调用等操作,执行到inner()时,激活函数inner创建自己的执行上下文环境,inner函数上下文入栈。
- inner函数上下文入栈后,其中的代码开始执行,进行赋值、函数调用、打印等操作,由于里面没有可以生成其他执行上下文的需要,所有代码执行完毕后,inner函数上下文出栈。
- inner函数上下文出栈,又回到了out函数执行上下文环境,接着执行out函数中后面剩下的代码,由于后面没有可以生成其他执行上下文的需要,所有代码执行完毕后,out函数上下文出栈。
- out函数上下文出栈后,又回到了全局执行上下文环境,直到浏览器窗口关闭,全局上下文出栈。
作用域与执行上下文区别
作用域只是一个“地盘”,其中没有变量。变量是通过作用域对应的执行上下文环境中的变量对象来实现的。所以作用域是静态观念的,而执行上下文环境是动态上的。有闭包存在时,一个作用域存在两个上下文环境也是有的。
同一个作用域下,对同一个函数的不同的调用会产生不同的执行上下文环境,继而产生不同的变量的值,所以,作用域中变量的值是在执行过程中确定的,而作用域是在函数创建时就确定的。
如果要查找一个作用域下某个变量的值,就需要找到这个作用域对应的执行上下文环境,再在其中找到变量的值。
变量提升
在Javascript中,函数及变量的声明都将被提升到函数的最顶部,提升的仅仅是变量的声明,变量的赋值并不会被提升。函数的声明与变量的声明是不一样的,函数表达式和变量表达式只是其声明被提升,函数声明是函数的声明和实现都被提升。
- function foo() {
- console.log("global foo");
- }
- function bar() {
- console.log("global bar");
- }
- //定义全局变量
- var v = "global var";
- function hoistMe() {
- // var bar; 被提升到顶部,并未实现
- // var v;
- console.log(typeof foo); //function
- console.log(typeof bar); //undefined
- console.log(v); //undefined
- // 函数里面定义了同名的函数和变量,无论在函数的任何位置定义这些函数和和变量,它们都将被提升到函数的最顶部。
- foo(); //local foo
- bar(); //报错,TypeError "bar is not a function"
- //函数声明,变量foo以及其实现被提升到hoistMe函数顶部
- function foo() {
- alert("local foo");
- }
- //函数表达式,仅变量bar被提升到函数顶部,实现没有被提升
- var bar = function() {
- alert("local bar");
- };
- //定义局部变量
- var v = "local";
- }
let 变量提升
- console.log(a); // Uncaught ReferenceError: a is not defined
- let a = "I am a";
- let b = "I am outside B";
- if(true){
- console.log(b); // Uncaught ReferenceError: b is not defined
- let b = " I am inside B";
- }
如果b没有变量提升,执行到console.log时应该是输出全局作用域中的b,而不是出现错误。
我们可以推知,这里确实出现了变量提升,而我们不能够访问的原因事实上是因为let的死区设计:当前作用域顶部到该变量声明位置中间的部分,都是该let变量的死区,在死区中,禁止访问该变量。由此,我们给出结论,let声明的变量存在变量提升, 但是由于死区我们无法在声明前访问这个变量。
var let 区别
- var声明的变量,只有函数才能为它创建新的作用域;
- let声明的变量,支持块级作用域,花括号就能为它创建新的作用域;
- 相同作用域,var可以反复声明相同标识符的变量,而let是不允许的;
- let声明的变量禁止在声明前访问
- // 全局变量
- var i = 0 ;
- // 定义外部函数
- function outer(){
- // 访问全局变量
- console.log(i); // 0
- function inner1(){
- console.log(i); // 0
- }
- function inner2(){
- console.log(i); // undefined
- var i = 1;
- console.log(i); // 1
- }
- inner1();
- inner2();
- console.log(i); // 0
- }
闭包
闭包就是指有权访问另一个函数作用域中的变量的函数。
官方解释:闭包是由函数以及创建该函数的词法环境组合而成。这个环境包含了这个闭包创建时所能访问的所有局部变量。(词法作用域)
通俗解释:闭包的关键在于:外部函数调用之后其变量对象本应该被销毁,但闭包的存在使我们仍然可以访问外部函数的变量对象。
当某个函数被掉用的时候,会创建一个执行环境及相应的作用域链。然后使用arguments和其他命名参数的值来初始化函数的活动对象。但在作用域链中,外部函数的活动对象始终处于第二位,外部函数的外部函数的活动对象处于第三位...直至作为作用域链终点的全局执行环境。
作用域链本质上是一个指向变量对象的指针列表,他只引用但不实际包含变量对象。
无论什么时候在函数中访问一个变量时,就会从作用域链中搜索具有相同名字的变量,一般来讲,当函数执行完毕,局部活动对象就会被销毁,内存中仅保存全部作用域的活动对象。但是,闭包不同。
创建闭包: 在一个函数内部创建另一个函数
- function add() {
- let a = 1;
- let b = 3;
- function closure() {
- b++;
- return a + b;
- }
- return closure;
- }
- // 闭包的作用域链包含着它自己的作用域,以及包含它的函数的作用域和全局作用域。
生命周期
通常,函数的作用域及其所有变量都会在函数执行结束后被销毁。但是,在创建了一个闭包以后,这个函数的作用域就会一直保存到闭包不存在为止。
当闭包中的函数closure从add中返回后,它的作用域链被初始化为包含add函数的活动对象和全局变量对象。这样closure就可以访问在add中定义的所有变量。
更重要的是,add函数在执行完毕后,也不会销毁,因为closure函数的作用域链仍然在引用这个活动对象。
换句话说,当add返回后,其执行环境的作用域链被销毁,但它的活动对象仍然在内存中,直至closure被销毁。
- function add(x) {
- function closure(y) {
- return x + y;
- }
- return closure;
- }
- let add2 = add(2);
- let add5 = add(5);
- // add2 和 add5 共享相同的函数定义,但是保存了不同的环境
- // 在add2的环境中,x为5。而在add5中,x则为10
- console.log(add2(3)); // 5
- console.log(add5(10)); // 15
- // 释放闭包的引用
- add2 = null;
- add5 = null;
闭包中的this对象
- var name = 'window';
- var obj = {
- name: 'object',
- getName: () => {
- return () => {
- return this.name;
- }
- }
- }
- console.log(obj.getName()()); // window
obj.getName()()是在全局作用域中调用了匿名函数,this指向了window。
函数名与函数功能是分割开的,不要认为函数在哪里,其内部的this就指向哪里。
window才是匿名函数功能执行的环境。
使用注意点
1)由于闭包会让包含函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除。
2)闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
使用
模仿块级作用域
私有变量
模块模式
在循环中创建闭包:一个常见错误
- function show(i) {
- console.log(i);
- }
- function showCallback(i) {
- return () => {
- show(i);
- };
- }
- // 测试1【3,3,3】
- const testFunc1 = () => {
- // var i;
- for (var i = 0; i < 3; i++) {
- setTimeout(() => show(i), 300);
- }
- }
- // 测试2 【0,1,2】
- const testFunc2 = () => {
- for (var i = 0; i < 3; i++) {
- setTimeout(showCallback(i), 300);
- }
- }
- // 测试3【0,1, 2】 闭包,立即执行函数
- // 在闭包函数内部形成了局部作用域,每循环一次,形成一个自己的局部作用域
- const testFunc3 = () => {
- for (var i = 0; i < 3; i++) {
- (() => {
- setTimeout(() => show(i), 300);
- })(i);
- }
- }
- // 测试4【0,1, 2】let
- const testFunc4 = () => {
- for (let i = 0; i < 3; i++) {
- setTimeout(() => show(i), 300);
- }
- }
setTimeout()函数回调属于异步任务,会出现在宏任务队列中,被压到了任务队列的最后,在这段代码应该是for循环这个同步任务执行完成后才会轮到它
测试1错误原因:赋值给 setTimeout 的是闭包。这些闭包是由他们的函数定义和在 testFunc1 作用域中捕获的环境所组成的。这三个闭包在循环中被创建,但他们共享了同一个词法作用域,在这个作用域中存在一个变量i。这是因为变量i使用var进行声明,由于变量提升,所以具有函数作用域。当onfocus的回调执行时,i的值被决定。由于循环在事件触发之前早已执行完毕,变量对象i(被三个闭包所共享)已经指向了i的最后一个值。
测试2正确原因: 所有的回调不再共享同一个环境, showCallback 函数为每一个回调创建一个新的词法环境。在这些环境中,i 指向数组中对应的下标。
测试4正确原因:JS中的for循环体比较特殊,每次执行都是一个全新的独立的块作用域,用let声明的变量传入到 for循环体的作用域后,不会发生改变,不受外界的影响。
this指向问题
this 就是一个指针,指向我们调用函数的对象。
执行上下文: 是语言规范中的一个概念,用通俗的话讲,大致等同于函数的执行“环境”。具体的有:变量作用域(和 作用域链条,闭包里面来自外部作用域的变量),函数参数,以及 this 对象的值。
找出 this 的指向
this 的值并不是由函数定义放在哪个对象里面决定,而是函数执行时由谁来唤起决定。
- var name = "Jay Global";
- var person = {
- name: 'Jay Person',
- details: {
- name: 'Jay Details',
- print: function() {
- return this.name;
- }
- },
- print: function() {
- return this.name;
- }
- };
- console.log(person.details.print()); // 【details对象调用的print】Jay Details
- console.log(person.print()); // 【person对象调用的print】Jay Person
- var name1 = person.print;
- var name2 = person.details;
- console.log(name1()); // 【name1前面没有调用对象,所以是window】Jay Global
- console.log(name2.print()) // 【name2对象调用的print】Jay Details
this和箭头函数
箭头函数按词法作用域来绑定它的上下文,所以 this 实际上会引用到原来的上下文。箭头函数保持它当前执行上下文的词法作用域不变,而普通函数则不会。换句话说,箭头函数从包含它的词法作用域中继承到了 this 的值。
匿名函数,它不会作为某个对象的方法被调用, 因此,this 关键词指向了全局 window 对象
- var object = {
- data: [1,2,3],
- dataDouble: [1,2,3],
- double: function() {
- console.log(this); // object
- return this.data.map(function(item) { // this是当前object,object调用的double
- console.log(this); // 传给map()的那个匿名函数没有被任一对象调用,所以是window
- return item * 2;
- });
- },
- doubleArrow: function() {
- console.log(this); // object
- return this.dataDouble.map(item => { // this是当前object,object调用的doubleArrow
- console.log(this); // doubleArrow是object调用的,这就是上下文,所以是window
- return item * 2;
- });
- }
- };
- object.double();
- object.doubleArrow();
明确设置执行上下文
在 JavaScript 中通过使用内置的特性开发者就可以直接操作执行上下文了。这些特性包括:
- bind():不需要执行函数就可以将 this 的值准确设置到你选择的一个对象上。通过逗号隔开传递多个参数。设置好 this 关键词后不会立刻执行函数。
- apply():将 this 的值准确设置到你选择的一个对象上。apply(thisObj, argArray)接收两个参数,thisObj是函数运行的作用域(this),argArray是参数数组,数组的每一项是你希望传递给函数的参数。如果没有提供argArray和thisObj任何一个参数,那么Global对象将用作thisObj。最后,会立刻执行函数。
- call():将 this 的值准确设置到你选择的一个对象上。然后像bind 一样通过逗号分隔传递多个参数给函数。语法:call(thisObj,arg1,arg2,..., argn);,如果没有提供thisObj参数,那么Global对象被用于thisObj。最后,会立刻执行函数。
this 和 bind
- var bobObj = {
- name: "Bob"
- };
- function print() {
- return this.name;
- }
- var printNameBob = print.bind(bobObj);
- console.log(printNameBob()); // Bob
this 和 call
- function add(a, b) {
- return a + b;
- }
- function sum() {
- return Array.prototype.reduce.call(arguments, add);
- }
- console.log(sum(1,2,3,4)); // 10
this 和 apply
apply 就是接受数组版本的call。
- Math.min(1,2,3,4); // 返回 1
- Math.min([1,2,3,4]); // 返回 NaN。只接受数字
- Math.min.apply(null, [1,2,3,4]); // 返回 1
- function Person(name, age){
- this.name = name;
- this.age = age;
- }
- function Student(name, age, grade) {
- Person.apply(this, arguments); //Person.call(this, name, age);
- this.grade = grade;
- }
- var student = new Student("sansan", 21, "一年级");
- console.log("student:", student); // {name: 'sansan'; age: '21', grade: '一年级'}
如果你的参数本来就存在一个数组中,那自然就用 apply,如果参数比较散乱相互之间没什么关联,就用 call。
对象属性类型
数据属性
数据属性包含一个数据值的位置,在这个位置可以读取和写入值,数据属性有4个描述其行为的特性:
- Configurable: 表示是否通过delete删除属性从而重新定义属性,能否修改属性的特性,或者能否把属性修改为访问器属性。默认值是true
- Enumerable: 表示能否通过for-in循环返回属性。默认值是true
- Writable: 表述能否修改属性。默认值是true
- Value: 包含这个属性的数据值。默认值是true
访问器属性
函数式编程
函数式编程是一种编程范式,是一种构建计算机程序结构和元素的风格,它把计算看作是对数学函数的评估,避免了状态的变化和数据的可变。
纯函数
纯函数是稳定的、一致的和可预测的。给定相同的参数,纯函数总是返回相同的结果。
特性
1. 如果给定相同的参数,则得到相同的结果
我们想要实现一个计算圆的面积的函数。
不是纯函数会这样做:
- let PI = 3.14;
- const calculateArea = (radius) => radius * radius * PI;
- // 它使用了一个没有作为参数传递给函数的全局对象
- calculateArea(10); // returns 314.0
纯函数:
- let PI = 3.14;
- const calculateArea = (radius, pi) => radius * radius * pi;
- // 现在把 PI 的值作为参数传递给函数,这样就没有外部对象引入。
- calculateArea(10, PI); // returns 314.0
2. 无明显副作用
纯函数不会引起任何可观察到的副作用。可见副作用的例子包括修改全局对象或通过引用传递的参数。
现在,实现一个函数,接收一个整数并返对该整数进行加1操作且返回:
- let counter = 1;
- function increaseCounter(value) {
- counter = value + 1;
- }
- increaseCounter(counter);
- console.log(counter); // 2
该非纯函数接收该值并重新分配counter,使其值增加1。
函数式编程不鼓励可变性(修改全局对象)。
- let counter = 1;
- const increaseCounter = (value) => value + 1; // 函数返回递增的值,而不改变变量的值
- increaseCounter(counter); // 2
- console.log(counter); // 1
3. 引用透明性
如果一个函数对于相同的输入始终产生相同的结果,那么它可以看作透明的。
实现一个square 函数:
- const square = (n) => n * n;
- square(2); // 4 将2作为square函数的参数传递始终会返回4
可以把square(2)换成4,我们的函数就是引用透明的。
纯函数使用
单元测试
纯函数代码肯定更容易测试,不需要 mock 任何东西。因此我们可以使用不同的上下文对纯函数进行单元测试。
一个简单的例子是接收一组数字,并对每个数进行加 1 :
- let list = [1, 2, 3, 4, 5];
- const incrementNumbers = (list) => list.map(number => number + 1);
- incrementNumbers(list); // [2, 3, 4, 5, 6]
对于输入[1,2,3,4,5],预期输出是[2,3,4,5,6]。
纯函数也可以被看作成值并用作数据使用
- 从常量和变量中引用它。
- 将其作为参数传递给其他函数。
- 作为其他函数的结果返回它。
其思想是将函数视为值,并将函数作为数据传递。通过这种方式,我们可以组合不同的函数来创建具有新行为的新函数。
假如我们有一个函数,它对两个值求和,然后将值加倍,如下所示:
- const doubleSum = (a, b) => (a + b) * 2;
对应两个值求差,然后将值加倍:
- const doubleSubtraction = (a, b) => (a - b) * 2
这些函数具有相似的逻辑,但区别在于运算符的功能。如果我们可以将函数视为值并将它们作为参数传递,我们可以构建一个接收运算符函数并在函数内部使用它的函数。
- const sum = (a, b) => a + b;
- const subtraction = (a, b) => a - b;
- const doubleOperator = (f, a, b) => f(a, b) * 2;
- doubleOperator(sum, 3, 1); // 8
- doubleOperator(subtraction, 3, 1); // 4
Promise
Promise 必须为以下三种状态之一:等待态(Pending)、执行态(Fulfilled)和拒绝态(Rejected)。一旦Promise 被 resolve 或 reject,不能再迁移至其他任何状态(即状态 immutable)。
基本过程:
初始化 Promise 状态(pending)
执行 then(..) 注册回调处理数组(then 方法可被同一个 promise 调用多次)
立即执行 Promise 中传入的 fn 函数,将Promise 内部 resolve、reject 函数作为参数传递给 fn ,按事件机制时机处理
Promise中要保证,then方法传入的参数 onFulfilled 和 onRejected,必须在then方法被调用的那一轮事件循环之后的新执行栈中执行。
真正的链式Promise是指在当前promise达到fulfilled状态后,即开始进行下一个promise.
跨域
因为浏览器的同源策略导致了跨域。同源策略是一个重要的安全策略,它用于限制一个origin的文档或者它加载的脚本如何能与另一个源的资源进行交互。它能帮助阻隔恶意文档,减少可能被攻击的媒介。
所谓同源是指"协议+域名+端口"三者相同。不同协议,不同域名,不同端口都会构成跨域。
跨域解决方案
1. jsonp: 需要服务器配合一个callback函数
2. CORS: 需要服务器设置header :Access-Control-Allow-Origin
3. window.name + iframe: 需要目标服务器响应window.name。
4. document.domain : 仅限主域相同,子域不同的跨域应用场景。
5. html5的 postMessage + iframe: 需要服务器或者目标页面写一个postMessage,主要侧重于前端通讯。
6. nginx反向代理: 不用服务器配合,需要搭建一个中转nginx服务器,用于转发请求。
jsonp跨域
在HTML标签里,一些标签比如script、img这样的获取资源的标签是没有跨域限制的。通过动态创建script,再请求一个带参网址实现跨域通信。
- 需要前后端配合使用。一般后端设置callback ,前端给后台接口中传一个callback 即可。
- 只能实现get一种请求。
栗子
前端代码:
- <script>
- var script = document.createElement('script');
- script.type = 'text/javascript';
- // 传参一个回调函数名给后端,方便后端返回时执行这个在前端定义的回调函数
- script.src = 'http://xxxxxxx:8080/login?callback=handleCallback';
- document.head.appendChild(script);
- function handleCallback(res) {
- alert(JSON.stringify(res));
- }
- </script>
后台代码:
- <?php
- $callback = $_GET['callback'];//得到回调函数名
- $data = array('a','b','c');//要返回的数据
- echo $callback.'('.json_encode($data).')';//输出
- ?>
CORS - 跨域资源共享
CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。
CORS有两种请求,简单请求和非简单请求。只要同时满足以下两大条件,就属于简单请求。
- 请求方法是以下三种方法之一:HEAD,GET,POST
- HTTP的头信息不超出以下几种字段:Accept,Accept-Language,Content-Language,Last-Event-ID,Content-Type【只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain】,没有自定义的HTTP头部。
简单请求
- 浏览器:把客户端脚本所在的域填充到Origin header里,向其他域的服务器请求资源。
- 服务器:根据资源权限配置,在响应头中添加Access-Control-Allow-Origin Header,返回结果。
- 浏览器:比较服务器返回的Access-Control-Allow-Origin Header和请求域的Origin。如果当前域已经得到授权,则将结果返回给页面。否则浏览器忽略此次响应。
- 网页:收到返回结果或者浏览器的错误提示。
对于简单的跨域请求,只要服务器设置的Access-Control-Allow-Origin Header和请求来源匹配,浏览器就允许跨域。服务器端设置的`Access-Control-Allow-Methods和Access-Control-Allow-Headers对简单跨域没有作用。
非简单请求
- 浏览器:先向服务器发送一个OPTIONS预检请求,检测服务器端是否支持真实请求进行跨域资源访问,浏览器会在发送OPTIONS请求时会自动添加Origin Header 、Access-Control-Request-Method Header和Access-Control-Request-Headers Header。
- 服务器:响应OPTIONS请求,会在responseHead里添加Access-Control-Allow-Methods head。这其中的method的值是服务器给的默认值,可能不同的服务器添加的值不一样。服务器还会添加Access-Control-Allow-Origin Header和Access-Control-Allow-Headers Header。这些取决于服务器对OPTIONS请求具体如何做出响应。如果服务器对OPTIONS响应不合你的要求,你可以手动在服务器配置OPTIONS响应,以应对带预检的跨域请求。在配置服务器OPTIONS的响应时,可以添加Access-Control-Max-Age head告诉浏览器在一定时间内无需再次发送预检请求,但是如果浏览器禁用缓存则无效。
- 浏览器:接到OPTIONS的响应,比较真实请求的method是否属于返回的Access-Control-Allow-Methods head的值之一,还有origin, head也会进行比较是否匹配。如果通过,浏览器就继续向服务器发送真实请求, 否则就会报预检错误:请求来源不被options响应允许,请求方法不被options响应允许或请求中有自定义header不被options响应允许。
- 服务器:响应真实请求,在响应头中放入Access-Control-Allow-Origin Header、Access-Control-Allow-Methods和Access-Control-Allow-Headers Header,分别表示允许跨域资源请求的域、请求方法和请求头,并返回数据。
- 浏览器:接受服务器对真实请求的返回结果,返回给网页
- 网页:收到返回结果或者浏览器的错误提示。
Access-Control-Allow-Origin在响应options请求和响应真实请求时都是有作用的,两者必须同时包含要跨域的源。 Access-Control-Allow-Methods和Access-Control-Allow-Headers只在响应options请求时有作用。
携带cookie
在 CORS 跨域中,浏览器并不会自动发送 Cookie。对于普通跨域请求只需服务端设置,而带cookie跨域请求前后端都需要设置。
浏览器,对于跨域请求,需要设置withCredentials 属性为 true。服务端的响应中必须携带 Access-Control-Allow-Credentials: true 。
除了Access-Control-Allow-Credentials之外,跨域发送 Cookie 还要求 Access-Control-Allow-Origin不允许使用通配符。否则浏览器将会抛出The value of the 'Access-Control-Allow-Origin' header in the response must not be the wildcard '*' 错误。事实上不仅不允许通配符,而且只能指定单一域名。
计算 Access-Control-Allow-Origin
既然Access-Control-Allow-Origin只允许单一域名, 服务器可能需要维护一个接受 Cookie 的 Origin 列表, 验证 Origin 请求头字段后直接将其设置为Access-Control-Allow-Origin的值。在 CORS 请求被重定向后 Origin 头字段会被置为 null, 此时可以选择从Referer头字段计算得到Origin。
具体实现
服务器端的响应头配置
Access-Control-Allow-Origin 可以设置为* ,表示可以与任意域进行数据共享。
- // 设置服务器接受跨域的域名
- "Access-Control-Allow-Origin": "http://127.0.0.1:8080",
- // 设置服务器接受跨域的请求方法
- 'Access-Control-Allow-Methods': 'OPTIONS,HEAD,DELETE,GET,PUT,POST',
- // 设置服务器接受跨域的headers
- 'Access-Control-Allow-Headers': 'x-requested-with, accept, origin, content-type',
- // 设置服务器不用再次预检请求时间
- 'Access-Control-Max-Age': 10000,
- // 设置服务器接受跨域发送Cookie
- 'Access-Control-Allow-Credentials': true
document.domain
此方案仅限主域相同,子域不同的跨域应用场景。
实现原理:两个页面都通过js强制设置document.domain为基础主域,就实现了同域。
栗子:
在父页面 http://xxx.com/a.html 中设置document.domain
- <iframe id = "iframe" src="http://xxx.com/b.html" onload = "test()"></iframe>
- <script type="text/javascript">
- document.domain = 'xxx.com';//设置成主域
- function test(){
- alert(document.getElementById('iframe').contentWindow);
- //contentWindow 可取得子窗口的 window 对象
- }
- </script>
在子页面http://xxx.com/b.html 中设置document.domain
- <script type="text/javascript">
- document.domain = 'xxx.com';
- //在iframe载入这个页面也设置document.domain,使之与主页面的document.domain相同
- </script>
window.postMessage
window.postMessage是html5的功能,是客户端和客户端直接的数据传递,既可以跨域传递,也可以同域传递。
postMessage(data, origin)方法接受两个参数:
- data:html5规范支持任意基本类型或可复制的对象,但部分浏览器只支持字符串,所以传参时最好用JSON.stringify()序列化。
- origin:协议+主机+端口号,也可以设置为"*",表示可以传递给任意窗口,如果要指定和当前窗口同源的话设置为"/"。
栗子:
假如有一个页面,页面中拿到部分用户信息,点击进入另外一个页面,另外的页面默认是取不到用户信息的,你可以通过window.postMessage把部分用户信息传到这个页面中。(需要考虑安全性等方面。)
发送消息:
- // 弹出一个新窗口
- var domain = 'http://haorooms.com';
- var myPopup = window.open(`${domain}/windowPostMessageListener.html`,'myWindow');
- // 发送消息
- setTimeout(function(){
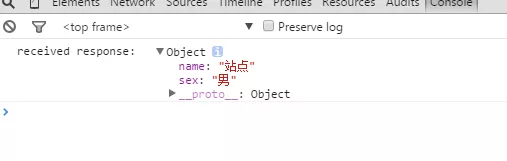
- var message = {name:"站点",sex:"男"};
- console.log('传递的数据是 ' + message);
- myPopup.postMessage(message, domain);
- }, 1000);
接收消息:
- // 监听消息反馈
- window.addEventListener('message', function(event) {
- // 判断域名是否正确
- if (event.origin !== 'http://haorooms.com') return;
- console.log('received response: ', event.data);
- }, false);
如下图,接受页面得到数据
如果是使用iframe,代码应该这样写:
- // 捕获iframe
- var domain = 'http://haorooms.com';
- var iframe = document.getElementById('myIFrame').contentWindow;
- // 发送消息
- setTimeout(function(){
- var message = {name:"站点",sex:"男"};
- console.log('传递的数据是: ' + message);
- iframe.postMessage(message, domain);
- },1000);
接收数据并反馈信息:
- // 响应事件
- window.addEventListener('message',function(event) {
- if(event.origin !== 'http://haorooms.com') return;
- console.log('message received: ' + event.data, event);
- event.source.postMessage(event.origin);
- }, false);
几个比较重要的事件属性:
- source – 消息源,消息的发送窗口/iframe。
- origin – 消息源的URI(可能包含协议、域名和端口),用来验证数据源。
- data – 发送方发送给接收方的数据。
- window.name
原理:
window对象有个name属性,该属性有个特征:即在一个窗口(window)的生命周期内,窗口载入的所有的页面都是共享一个window.name,每个页面对window.name都有读写的权限,window.name是持久存在一个窗口载入过的所有页面中的。
栗子:
在子页面(b.com/data.html) 设置window.name:
- /* b.com/data.html */
- <script type="text/javascript">
- window.name = 'I was there!';
- // 这里是要传输的数据,大小一般为2M,IE和firefox下可以大至32M左右
- // 数据格式可以自定义,如json、字符串
- </script>
在父页面(a.com/app.html)中创建一个iframe,把其src指向子页面。在父页面监听iframe的onload事件,获取子页面数据:
- /* a.com/app.html */
- <script type="text/javascript">
- var iframe = document.createElement('iframe');
- iframe.src = 'http://b.com/data.html';
- function iframelLoadFn() {
- var data = iframe.contentWindow.name;
- console.log(data);
- // 获取数据以后销毁iframe,释放内存;这也保证了安全(不被其他域frame js访问)。
- iframeDestoryFn();
- }
- function iframeDestoryFn() {
- iframe.contentWindow.document.write('');
- iframe.contentWindow.close();
- document.body.removeChild(iframe);
- }
- if (iframe.attachEvent) {
- iframe.attachEvent('onload', iframelLoadFn);
- } else {
- iframe.onload = iframelLoadFn;
- }
- document.body.appendChild(iframe);
- </script>
http-proxy-middleware
http-proxy-middleware用于把请求代理转发到其他服务器的中间件。
安装:
npm install http-proxy-middleware --save-dev
配置如下:
- module.exports = {
- devServer: {
- contentBase: path.resolve(__dirname, 'dev'),
- publicPath: '/',
- historyApiFallback: true,
- proxy: {
- // 请求到 '/device' 下的请求都会被代理到target:http://target.com中
- '/device/*': {
- target: 'http://target.com',
- secure: false, // 接受运行在https上的服务
- changeOrigin: true
- }
- }
- }
- }
使用如下:
- fetch('/device/space').then(res => {
- // 被代理到 http://target.com/device/space
- return res.json();
- });
- // 使用的url 必须以/开始 否则不会代理到指定地址
- fetch('device/space').then(res => {
- // http://localhost:8080/device/space 访问本地服务
- return res.json();
- });
nginx反向代理
反向代理(Reverse Proxy)方式是指以代理服务器来接受客户端的连接请求,然后将请求转发给内部网络上的服务器;并将从服务器上得到的结果返回给客户端,此时代理服务器对外就表现为一个服务器。
反向代理服务器对于客户端而言它就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理 的命名空间(name-space)中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端,就像这些内容 原本就是它自己的一样。
模块化
AMD/CMD/CommonJs都是JS模块化开发的标准,目前对应的实现是RequireJS,SeaJs, nodeJs;
CommonJS:服务端js
CommonJS 是以在浏览器环境之外构建 javaScript 生态系统为目标而产生的写一套规范,主要是为了解决 javaScript 的作用域问题而定义的模块形式,可以使每个模块它自身的命名空间中执行。
实现方法:模块必须通过 module.exports 导出对外的变量或者接口,通过 require() 来导入其他模块的输出到当前模块的作用域中;
主要针对服务端(同步加载文件)和桌面环境中,node.js 遵循的是 CommonJS 的规范;CommonJS 加载模块是同步的,所以只有加载完成才能执行后面的操作。
- require()用来引入外部模块;
- exports对象用于导出当前模块的方法或变量,唯一的导出口;
- module对象就代表模块本身。
- // 定义一个module.js文件
- var A = () => console.log('我是定义的模块');
- // 1.第一种返回方式
- module.exports = A;
- // 2.第二种返回方式
- module.exports.test = A
- // 3.第三种返回方式
- exports.test = A;
- // 定义一个test.js文件【这两个文件在同一个目录下】
- var module = require("./module");
- //调用这个模块,不同的返回方式用不同的方式调用
- // 1.第一种调用方式
- module();
- // 2.第二种调用方式
- module.test();
- // 3.第三种调用方式
- module.test();
- // 执行文件
- node test.js
AMD:异步模块定义【浏览器端js】
AMD 是 Asynchronous Module Definition 的缩写,意思是异步模块定义;采用的是异步的方式进行模块的加载,在加载模块的时候不影响后边语句的运行。主要是为前端 js 的表现指定的一套规范。
实现方法:通过define方法去定义模块,通过require方法去加载模块。
define(id?,dependencies?,factory): 它要在声明模块的时候制定所有的依赖(dep),并且还要当做形参传到factory中。没什么依赖,就定义简单的模块(或者叫独立的模块)
require([modules], callback): 第一个参数[modules],是需加载的模块名数组;第二个参数callback,是模块加载成功之后的回调函数
主要针对浏览器js,requireJs遵循的是 AMD 的规范;
- // module1.js文件, 定义独立的模块
- define({
- methodA: () => console.log('我是module1的methodA');
- methodB: () => console.log('我是module1的methodB');
- });
- // module2.js文件, 另一种定义独立模块的方式
- define(() => {
- return {
- methodA: () => console.log('我是module2的methodA');
- methodB: () => console.log('我是module2的methodB');
- };
- });
- // module3.js文件, 定义非独立的模块(这个模块依赖其他模块)
- define(['module1', 'module2'], (m1, m2) => {
- return {
- methodC: () => {
- m1.methodA();
- m2.methodB();
- }
- };
- });
- //定义一个main.js,去加载这些个模块
- require(['module3'], (m3) => {
- m3.methodC();
- });
- // 为避免造成网页失去响应,解决办法有两个,一个是把它放在网页底部加载,另一个是写成下面这样:
- <script src="js/require.js" defer async="true" ></script>
- // async属性表明这个文件需要异步加载,避免网页失去响应。
- // IE不支持这个属性,只支持defer,所以把defer也写上。
- // data-main属性: 指定网页程序的主模块
- <script data-main="main" src="js/require.js"></script>
- // 控制台输出结果
- 我是module1的methodA
- 我是module2的methodB
CMD:通用模块定义【浏览器端js】
CMD 是 Common Module Definition 的缩写,通过异步的方式进行模块的加载的,在加载的时候会把模块变为字符串解析一遍才知道依赖了哪个模块;
主要针对浏览器端(异步加载文件),按需加载文件。对应的实现是seajs
AMD和CMD的区别
- 对于依赖的模块,AMD 是提前执行,CMD 是延迟执行。不过 RequireJS 从 2.0 开始,也改成可以延迟执行(根据写法不同,处理方式不同)。CMD 推崇 as lazy as possible(尽可能的懒加载,也称为延迟加载,即在需要的时候才加载)。
- CMD 推崇依赖就近,AMD 推崇依赖前置。
- // CMD
- define(function(require, exports, module) {
- var a = require('./a');
- a.doSomething();
- // ...
- var b = require('./b'); // 依赖可以就近书写
- b.doSomething();
- // ...
- })
- // AMD
- define(['./a', './b'], function(a, b) { // 依赖必须一开始就写好
- a.doSomething();
- // ...
- b.doSomething();
- //...
- })
import和require区别
import和require都是被模块化使用。
- require是CommonJs的语法(AMD规范引入方式),CommonJs的模块是对象。import是es6的一个语法标准(浏览器不支持,本质是使用node中的babel将es6转码为es5再执行,import会被转码为require),es6模块不是对象。
- require是运行时加载整个模块(即模块中所有方法),生成一个对象,再从对象上读取它的方法(只有运行时才能得到这个对象,不能在编译时做到静态化),理论上可以用在代码的任何地方。import是编译时调用,确定模块的依赖关系,输入变量(es6模块不是对象,而是通过export命令指定输出代码,再通过import输入,只加载import中导的方法,其他方法不加载),import具有提升效果,会提升到模块的头部(编译时执行)
export和import可以位于模块中的任何位置,但是必须是在模块顶层,如果在其他作用域内,会报错(es6这样的设计可以提高编译器效率,但没法实现运行时加载)。
require是赋值过程,把require的结果(对象,数字,函数等),默认是export的一个对象,赋给某个变量(复制或浅拷贝)。import是解构过程(需要谁,加载谁)。
require/exports:
- // require: 真正被require出来的是来自module.exports指向的内存块内容
- const a = require('a') //
- // exports: 只是 module.exports的引用,辅助module.exports操作内存中的数据
- exports.a = a
- module.exports = a
import/export:
- // import
- import a from 'a';
- import { default as a } from 'a';
- import * as a from 'a';
- import { fun1,fun2 } from 'a';
- // export
- export default a;
- export const a = 1;
- export functon a { ... };
- export { fun1, fun2 };
http和https
Http:超文本传输协议(Http,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。设计Http最初的目的是为了提供一种发布和接收HTML页面的方法。它可以使浏览器更加高效。
Http协议是以明文方式发送信息的,如果黑客截取了Web浏览器和服务器之间的传输报文,就可以直接获得其中的信息。
Https:是以安全为目标的Http通道,是Http的安全版。Https的安全基础是SSL。SSL协议位于TCP/IP协议与各种应用层协议之间,为数据通讯提供安全支持。SSL协议可分为两层:SSL记录协议(SSL Record Protocol),它建立在可靠的传输协议(如TCP)之上,为高层协议提供数据封装、压缩、加密等基本功能的支持。
SSL握手协议(SSL Handshake Protocol),它建立在SSL记录协议之上,用于在实际的数据传输开始前,通讯双方进行身份认证、协商加密算法、交换加密密钥等。
HTTP与HTTPS的区别
1、HTTP是超文本传输协议,信息是明文传输,HTTPS是具有安全性的SSL加密传输协议。
2、HTTPS协议需要ca申请证书,一般免费证书少,因而需要一定费用。
3、HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样。前者是80,后者是443。
4、HTTP连接是无状态的,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,安全性高于HTTP协议。
https的优点
尽管HTTPS并非绝对安全,掌握根证书的机构、掌握加密算法的组织同样可以进行中间人形式的攻击,但HTTPS仍是现行架构下最安全的解决方案,主要有以下几个好处:
1)使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;
2)HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性。
3)HTTPS是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
4)谷歌曾在2014年8月份调整搜索引擎算法,并称“比起同等HTTP网站,采用HTTPS加密的网站在搜索结果中的排名将会更高”。
Https的缺点
1)Https协议握手阶段比较费时,会使页面的加载时间延长近。
2)Https连接缓存不如Http高效,会增加数据开销,甚至已有的安全措施也会因此而受到影响;
3)SSL证书通常需要绑定IP,不能在同一IP上绑定多个域名,IPv4资源不可能支撑这个消耗。
4)Https协议的加密范围也比较有限。最关键的,SSL证书的信用链体系并不安全,特别是在某些国家可以控制CA根证书的情况下,中间人攻击一样可行。
遍历方法
for
在for循环中,循环取得数组或是数组类似对象的值,譬如arguments和HTMLCollection对象。
不足:
- 在于每次循环的时候数组的长度都要去获取;
- 终止条件要明确;
foreach(),map()
两个方法都可以遍历到数组的每个元素,而且参数一致;
forEach(): 对数组的每个元素执行一次提供的函数, 总是返回undefined;
map(): 创建一个新数组,其结果是该数组中的每个元素都调用一个提供的函数后返回的结果。返回值是一个新的数组;
- var array1 = [1,2,3,4,5];
- var x = array1.forEach((value,index) => {
- console.log(value);
- return value + 10;
- });
- console.log(x); // undefined
- var y = array1.map((value,index) => {
- console.log(value);
- return value + 10;
- });
- console.log(y); // [11, 12, 13, 14, 15]
for in
经常用来迭代对象的属性或数组的每个元素,它包含当前属性的名称或当前数组元素的索引。
当遍历一个对象的时候,变量 i 是循环计数器 为 对象的属性名, 以任意顺序遍历一个对象的可枚举属性。对于每个不同的属性,语句都会被执行。
当遍历一个数组的时候,变量 i 是循环计数器 为 当前数组元素的索引
不足:
for..in循环会把某个类型的原型(prototype)中方法与属性给遍历出来.
- const array = ["admin","manager","db"];
- array.color = 'red';
- array.prototype.name= "zhangshan";
- for(var i in array){
- if(array.hasOwnProperty(i)){
- console.log(array[i]); // admin,manager,db,color
- }
- }
- // hasOwnProperty(): 对象的属性或方法是非继承的,返回true
for … of
迭代循环可迭代对象(包括Array,Map,Set,String,TypedArray,arguments 对象)等等。不能遍历对象。只循环集合本身的元素
- var a = ['A', 'B', 'C'];
- var s = new Set(['A', 'B', 'C']);
- var m = new Map([[1, 'x'], [2, 'y'], [3, 'z']]);
- a.name = 'array';
- for (var x of a) {
- console.log(x); //'A', 'B', 'C'
- }
- for (var x of s) {
- console.log(x);//'A', 'B', 'C'
- }
- for (var x of m) {
- console.log(x[0] + '=' + x[1]);//1='x',2='y',3='z'
- }
继承
- // 定义一个动物类
- function Animal(name) {
- // 属性
- this.name = name || 'Animal';
- // 实例方法
- this.sleep = function(){
- console.log(this.name + '正在睡觉!');
- }
- }
- // 原型方法
- Animal.prototype.eat = function(food) {
- console.log(this.name + '正在吃:' + food);
- };
原型链继承
核心: 将父类的实例作为子类的原型。
- function Dog(age) {
- this.age = age;
- }
- Dog.protoType = New Animal();
- Dog.prototype.name = 'dog';
- const dog = new Dog(12);
- console.log(dog.name);
- console.log(dog.eat('age'));
- console.log(dog instanceof Animal); //true
- console.log(dog instanceof Dog); //true
new 创建新实例对象经过了以下几步:
1.创建一个新对象
2.将新对象的_proto_指向构造函数的prototype对象
3.将构造函数的作用域赋值给新对象 (也就是this指向新对象)
4.执行构造函数中的代码(为这个新对象添加属性)
5.返回新的对象
- // 1. 创建一个新对象
- var Obj = {};
- // 2. 将新对象的_proto_指向构造函数的prototype对象
- Obj._proto_ = Animal.prototype();
- // 3. 执行构造函数中的代码(为这个新对象添加属性)
- Animal.call(Obj);
- // 4. 返回新的对象
- return Obj;
特点:
1.实例可继承的属性有:实例的构造函数的属性,父类构造函数属性,父类原型的属性
2.非常纯粹的继承关系,实例是子类的实例,也是父类的实例
3.父类新增原型方法/原型属性,子类都能访问到
缺点:
1.新实例无法向父类构造函数传参。
2.继承单一。
3.所有新实例都会共享父类实例的属性。(原型上的属性是共享的,一个实例修改了原型属性,另一个实例的原型属性也会被修改!)
4.要想为子类新增原型上的属性和方法,必须要在new Animal()这样的语句之后执行,不能放到构造器中
构造函数继承
核心:使用父类的构造函数来增强子类实例,等于是复制父类的实例属性给子类(没用到原型)
- function Dog(name) {
- Animal.apply(this, 'dog');
- this.name = name;
- }
- const dog = new Dog();
- console.log(dog.name);
- console.log(dog.eat('age'));
- console.log(dog instanceof Animal); //false
- console.log(dog instanceof Dog); //true
重点:用.call()和.apply()将父类构造函数引入子类函数(在子类函数中做了父类函数的自执行(复制))
特点:
1.只继承了父类构造函数的属性,没有继承父类原型的属性。
2.解决了原型链继承缺点1、2、3。
3.可以实现多继承,继承多个构造函数属性(call多个)。
4.在子实例中可向父实例传参。
缺点:
1.能继承父类构造函数的属性。
2.无法实现构造函数的复用。(每次用每次都要重新调用)
3.每个新实例都有父类构造函数的副本,臃肿。
4.实例并不是父类的实例,只是子类的实例
组合继承(原型链继承和构造函数继承)(常用)
核心:通过调用父类构造,继承父类的属性并保留传参的优点,然后通过将父类实例作为子类原型,实现函数复用
- function Cat(name){
- Animal.call(this, name);
- this.name = name;
- }
- Cat.prototype = new Animal();
- Cat.prototype.constructor = Cat;
- var cat = new Cat();
- console.log(cat.name);
- console.log(cat.sleep());
- console.log(cat instanceof Animal); // true
- console.log(cat instanceof Cat); // true
重点:结合了两种模式的优点,传参和复用
特点:
1.可以继承父类原型上的属性,可以传参,可复用。
2.每个新实例引入的构造函数属性是私有的。
3.既是子类的实例,也是父类的实例
缺点:
调用了两次父类构造函数(耗内存),子类的构造函数会代替原型上的那个父类构造函数。
原型式继承
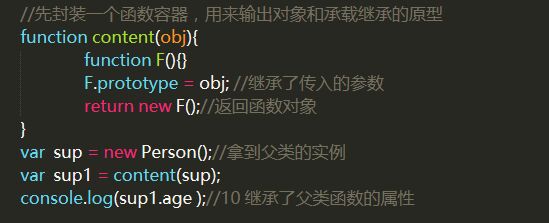
重点:用一个函数包装一个对象,然后返回这个函数的调用,这个函数就变成了个可以随意增添属性的实例或对象。object.create()就是这个原理。
特点:
类似于复制一个对象,用函数来包装。
缺点:
1.所有实例都会继承原型上的属性。
2.无法实现复用。(新实例属性都是后面添加的)
寄生式继承
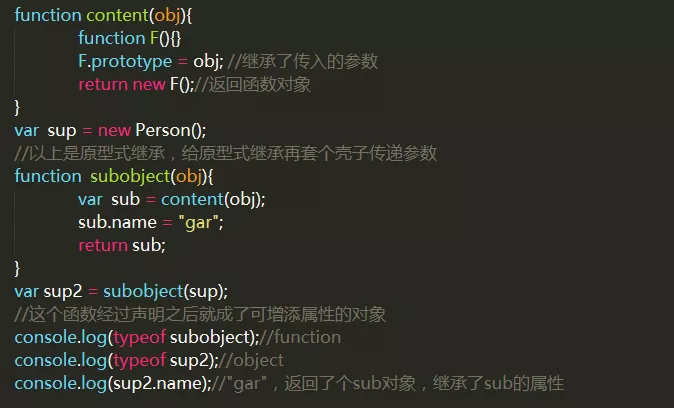
重点:就是给原型式继承外面套了个壳子。
优点:没有创建自定义类型,因为只是套了个壳子返回对象(这个),这个函数顺理成章就成了创建的新对象。
缺点:没用到原型,无法复用。
寄生组合式继承(常用)
寄生:在函数内返回对象然后调用
组合:
1、函数的原型等于另一个实例。
2、在函数中用apply或者call引入另一个构造函数,可传参。
- function Cat(name){
- Animal.call(this);
- this.name = name || 'Tom';
- }
- (function(){
- // 创建一个没有实例方法的类
- var Super = function(){};
- Super.prototype = Animal.prototype;
- //将实例作为子类的原型
- Cat.prototype = new Super();
- })();
- var cat = new Cat();
- Cat.prototype.constructor = Cat; // 需要修复下构造函数
- console.log(cat.name);
- console.log(cat.sleep());
- console.log(cat instanceof Animal); // true
- console.log(cat instanceof Cat); //true
重点:修复了组合继承的问题。