一 前言
Vmo 是我在 18 年发布的一个工具库,用于快速创建数据模型,当时我写了一篇文章《Vmo 前端数据模型设计》得到过一段时间的关注,当时我从事三维装修相关的项目。在图形学的背景基础及海量复杂的数据的情况下,自然而然在前端则会衍生出一种数据处理、解析、消费的技术方案,也种下了我对数据模型概念的种子。
简单举个例子:需要解析一个三维装修的房子的数据会有哪些呢?
- 房子(Hourse),楼层(Layer),房间(Room),墙体(Wall),墙面(WallSpace),墙角(Corner),吊顶(Ceiling),踢脚线(Skirting),地(Floor,带厚度),地面(FloorSpace),门(Door),窗(Window)。
- 以及会延伸出来大量的变体,比如飘窗,直角飘窗,弧形窗,墙洞,楼梯等等。
在解析这些数据中存在非常多的相互关联和计算,比如 房间需要和墙面,墙面需要和墙体关联,墙体和最多 2 个房间关联,墙角和多个房间关联,墙角和多个墙体关联等等
面对这样海量、复杂的数据,如果只靠着一个 API 请求的结果消费显然是非常不可取的方案,先不说这些数据能不能正确的解析出来,就说这些数据如何维护,保存时如何收集到所有数据反向序列化给后端都是些头疼的问题。
当然这些问题在当时我们抽象的各个数据模型中得到了解决,如果想了解具体细节可以查看我之前的文章。
今天我想讲的是,在我加入阿里后,一直在思考的关于数据模型的两个问题:
- 是不是数据模型这种事情对于常规项目没有使用场景或者价值呢?常规的,像一些数据查询,或者填写一些数据提交。这种需求里面有必要使用什么抽象类,什么数据模型吗?
- 为什么在前端圈子里面,很少有看到这方面的内容,现在前端圈子里大多都是在走向函数化,Composition等等,是不是这条路子走的有问题?
在寻觅了 2 年后,主导 Lazada 商家端的商品发布页面重构时,仿佛找到了一些答案。
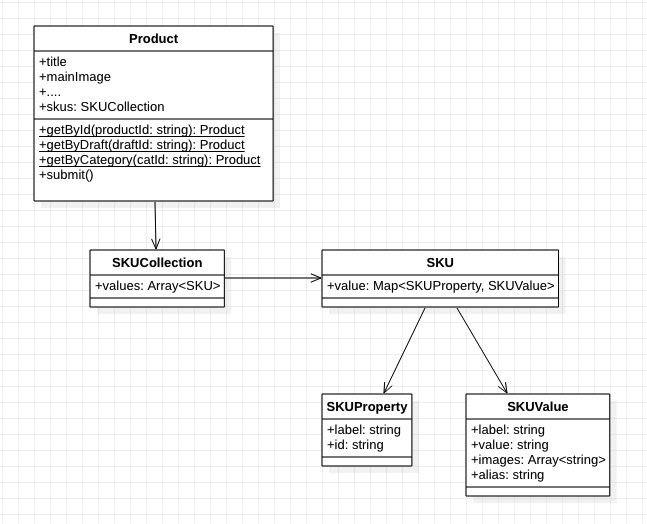
二 商品模型
首先在新增一个商品的过程中,实际上是用户在以客户端的形式制作一组商品数据,常规的前端视角来看就是提交一份“JSON”。
而编辑就是通过 API 拉取这份“JSON”解析到 Form 表单中,让用户进行编辑后,再将这份“JSON”提交。
那么粗略的将数据抽象为模型将会成为这样:
Well,到目前为止,我们做的事情都感觉像是在脱裤子放屁,多此一举。哈哈哈,各位看官暂且勿喷,稍安勿躁 。
那么为什么需要把这些数据抽象为一个类呢?我拿一下几个 Case 来说明:
1 请求数据 & 单元测试
很多时候,前端把对数据的请求和处理是写在组件中的,更优一点可能会封装在某个聚类里面,或者某个 Hook 里面,调用时轻巧的拿到状态和数据。
像商品这样的数据请求方式会存在多种:草稿中获取,编辑中获取,某个类目中获取(不同类目下,商品属性不同)。
每种获取方式请求的接口和参数组合方式可能不同,但最后前端消费的产物却是相同的。按照策略模式来说,对于一个商品模型的获取只是使用了不同的策略,但产物却是一致的,消费端无论调用何种方式,获取到的结果都是可靠的 Product 模型类。
有经验的前端都知道,很多时候,在一个项目在一轮轮的迭代后,我们的接口数据往往会存在部分数据需要前端做一定处理或者转换。
面对这样的数据处理,如果放在一个组件或者 Hook 中,是不太合适的,在做单元测试或者数据消费的时候都可能会给我们带来一些阻力。
在我看来,调试一个数据问题最好的办法,就是写一个单元测试,对单元测试预期的结果进行调试,往往比我们在浏览器中 Mock 一份数据调试数据更高效,对将来的稳定性也更有帮助。
安全感,数据消费起来,一个类和一份 JSON 给开发者带来的安全感和爽感是完全不同的。消费过数据模型 或者 次一点 消费过Interface的小伙伴,我相信对这一点是非常认同的。
哈哈,说到这里有些小伙伴可能要问了,你说的这个我们用Interface也能达到同样的效果呀。好,咱们继续...
2 计算性消费数据
什么叫计算性消费数据的,说的简单点,就比如:
上面这个例子非常经典且清晰,元数据中可能只是些基本数据,但是很多时候前端需要根据不同场景来进行元数据组装,以往这些数据往往会被封装为各个方法,或者被当做 template 写在组件中,散落在各个角落,每当用到这份数据时可能又会重新按照场景组装一遍。往往这种时候就会存在 需求缺失,比如某情况下需要将之前所有消费到 fullName 的地方改为小写。
拿到商品发布来说,计算性消费数据到底有哪些应用场景呢?
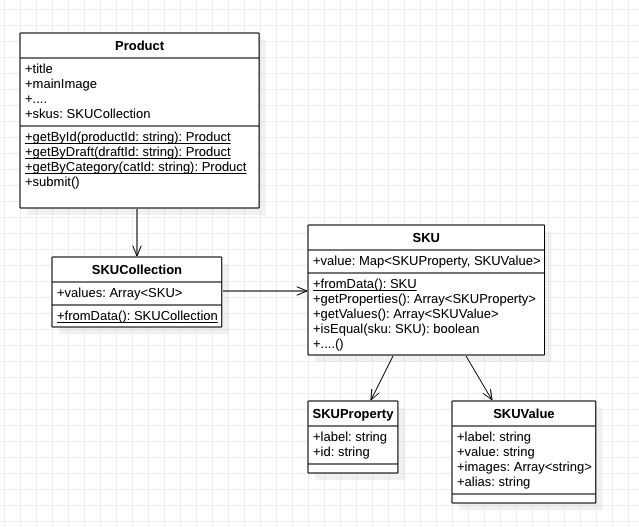
在此之前,我想先解释一下SKU这个数据模型,它其中最核心的元数据是:value: Map
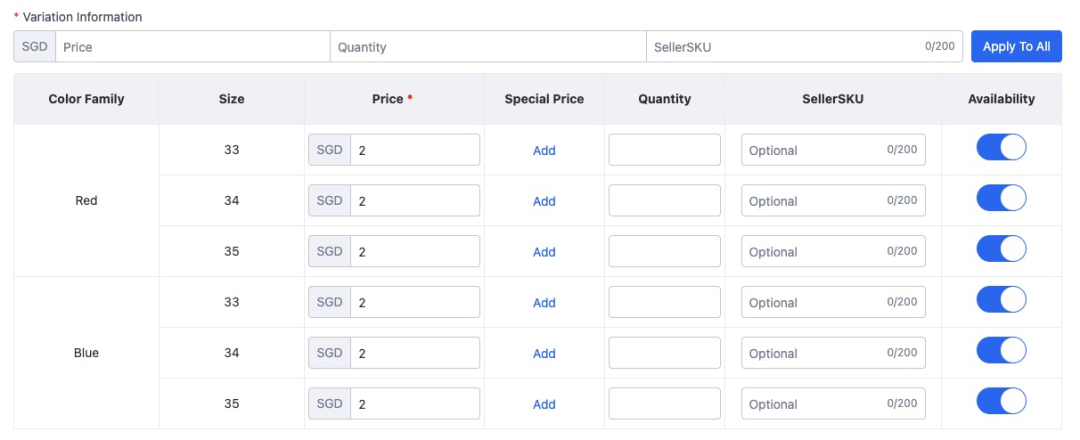
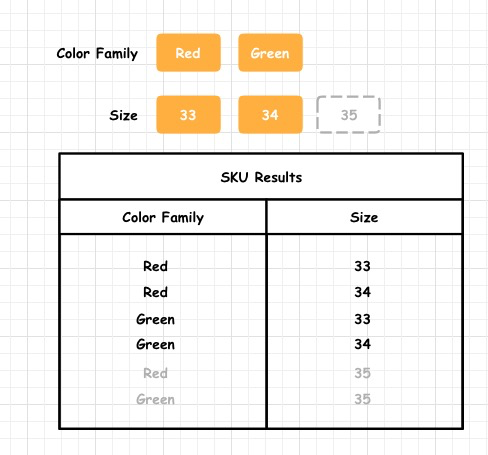
按照上图这个表格中所示,可以看到该商品共有 6 个 SKU,第一个 SKU 所对应的SKU模型数据应为:
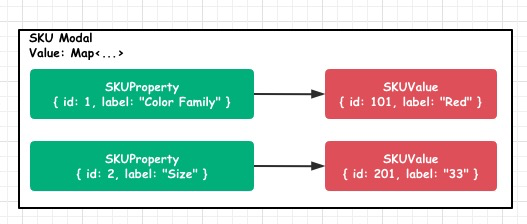
像这样一个 SKU Model,它所具备的元数据已经可以清晰描述当前 SKU,而且可以通过 SKU 的扩展方法做到很多有用的数据,比如:
- getProperties() 获取该 SKU 有所有属性,如:Color Family,Size。
- getValues() 获取该 SKU 所有Value,如:Red,33。
- isEqual(anotherSKU: SKU): boolean 比较一个 SKU 是否和当前 SKU 完全相同,这在后续的数据合并中非常有用。
- getValueByPropertyId(id: string) 通过 PropertyId,获取一个 SKUValue。
相比与只是一个 Object 对象来说,数据模型能够带来非常多的数据处理和数据扩展能力,当某种情况下需要消费由该数据产生的计算性消费数据时,可以很轻易的进行扩展使用,对于数据结构也有更好的预期和掌控力。
结合对该数据模型的单元测试,就可以清晰快速的开发数据层,当数据层可靠后,在视图层消费就会变得行云流水,得心应手了。
举个单元测试的例子:
这种SKU,是一种类型较为特殊的SKU,它其中会存在 alias 字段,当有这种字段时,在做SKU比对时,不但要对 SKUProperty,SKUValue 的ID做比对,还需要对 alias 字段做比对。
所以按照上面的单测来看,结果应该是 false,因为这两份数据中的alias是不同的。没办法,这是一个业务需求。
如果在视图层做数据比对时,使用的是纯数据进行比对,很有可能漏掉这部分逻辑,这就会导致项目变得捉襟见肘,拆东墙补西墙。
反正,在消费层遇到很多的需要对数据处理或判断时,大可以将这部分能力交给数据模型来处理,由数据模型来保证数据的稳定性。
3 数据关系
使用数据模型,还可以帮你清晰管理数据关系,比如商品和SKU之间,SKU和SKUProperty,SKUValue 之间的关系。
我举个具体案例:
这是一个商品编辑时组 笛卡尔积(Cartesian product) 的过程,当我们的SKU属性被用户添加或者修改时,将会触发笛卡尔积的重新计算出最新的排列组合结果。
比如当用户新增一个尺码为35时,笛卡尔积将会多出两项组合结果。同理,如果当维度增加一列时,比如添加材质维度,将会产生更多SKU结果。
以往,前端开发者总会将这部分计算过程封装成为一个数学方法,放在utils中随时调用,这看起没什么问题。
如果将这个过程看做是,一个 SKUCollection 数据模型的构建过程的话,一切就会将变得顺理成章:
有了这样一个数据模型结构后,就可以清晰的通过数据模型来调用其相关的数据和计算性数据。
另外,不同的数据模型虽然相互依赖,但对数据解析和计算性数据缺相互独立,可以做到独立使用和单元测试。
三 异常模型
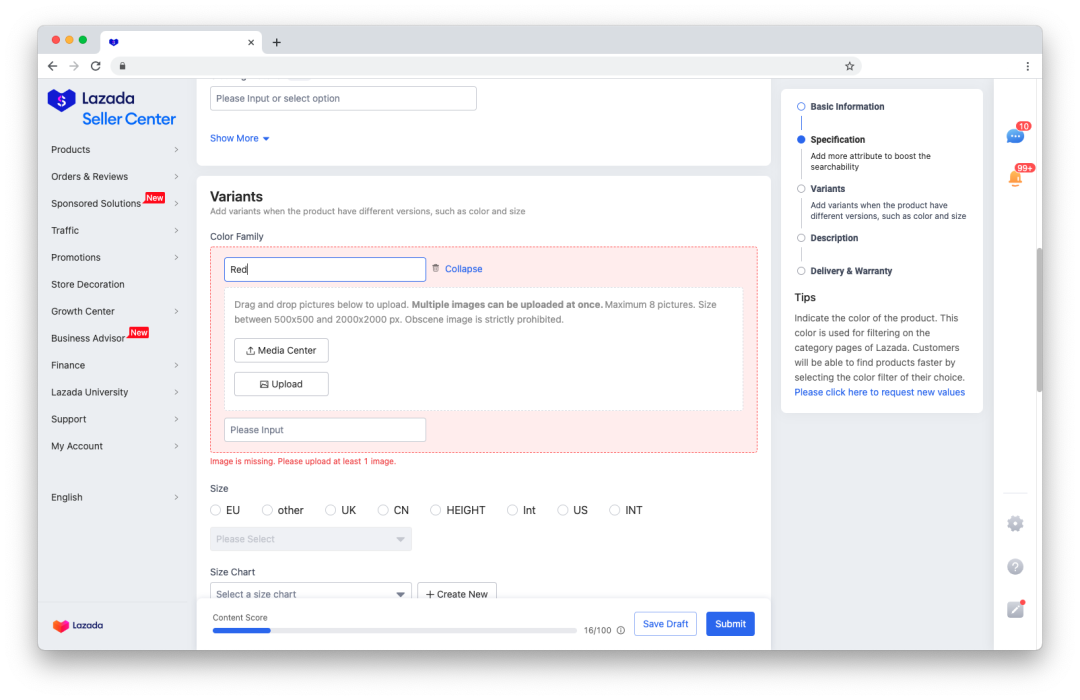
商品发布本质上是一个较为复杂的表单提交页面。由于字段多,交互复杂等原因,在产品设计过程中,就已经将很多字段先拆分为不同模块,来减轻用户心理负担。
比如会存在:基础信息,商品属性,详描,运费等。
在填写过程中,会存在部分 前端校验 + 后端校验 的场景。
在数据提交或者其他数据写入过程中,后端同时会处理字段校验,当后端发现某个字段填写错误时,服务端将返回错误信息及错误字段信息。
为了更好的交互体验,前端将会根据返回获取到字段信息,定位到对应的字段位置,显示错误信息并报红,另外还需要根据当前字段判断其所归属的模块进行报错。
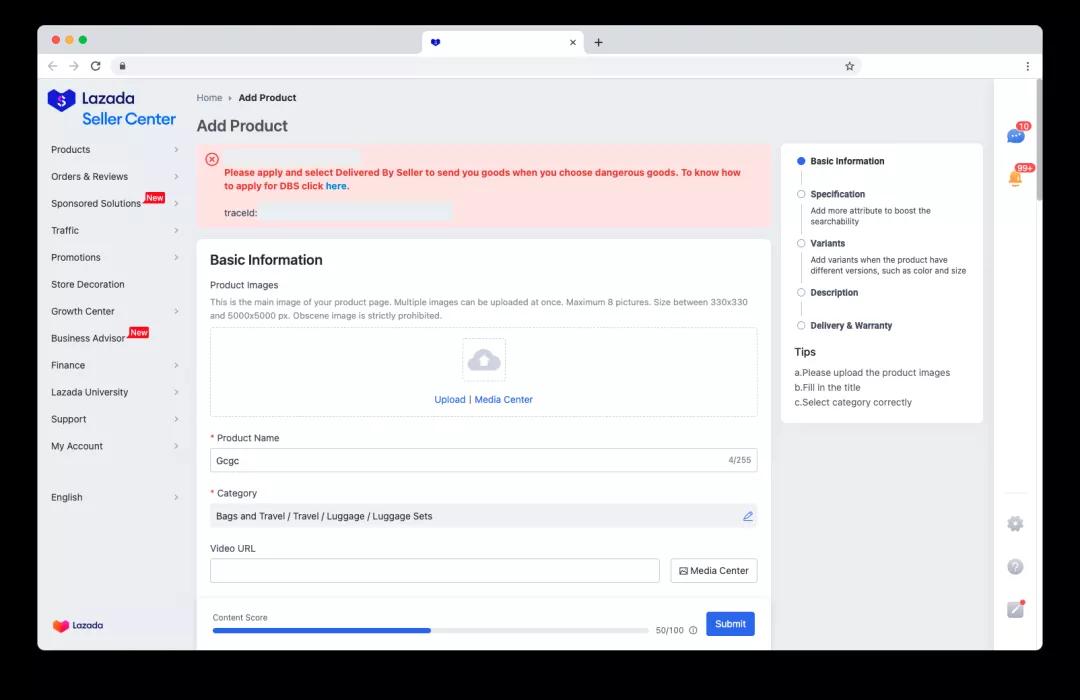
还有一种情况是:服务端的第一层校验通过,调用其他商品上游链路时抛出异常,此时上游链路可能已经丢失字段信息,面对这样的异常数据,前端需要展示在表单顶部,并且提供traceId,以便追踪定位异常。
就商品发布来说,显而易见的"保存"的动作是一个需要处理异常的情况,所以我们会在提交的地方写上很多后端返回异常时的处理逻辑。
当有一天,有另外一个迭代需要写入操作时,同样也会产生异常的情况,这些的异常情况再次处理时又会有很多数据转换和错误显示的逻辑。
如果收到这份后端返回数据,将他转换为异常数据模型,然后交由视图层消费,这样会让所有异常模型下需要处理的逻辑复用避免交互逻辑丢失。
当然,视图层如何更巧妙的消费该数据模型又是另外一个有意思的设计,此处暂且不表,后面我还会写一篇专门介绍商品发布的视图层状态管理设计。
四 总结
在商品发布中,除了上述提到的几个数据模型以外,其实还构建了一些其他类型的数据模型,如:运费模型,商品质量分模型,类目推荐模型等... 然后由这些多个子模型共同组合成为一个商品的模型。
这样的数据模型在消费起来,开发者其实不会太过关心究竟需要请求什么API,返回的数据究竟是什么样的,他们的返回是否要处理、转换、兼容等问题。
同时,这样高质量的数据模型其实不依赖于视图层的框架,它可以被抽离作为一个独立的包来管理维护,然后在其他页面引入使用,比如商品域可能遇到的:商品管理,商品选择,运费编辑,商品质量分预览等等...
回到开头,我提到的问题:
- 是不是数据模型这种事情对于常规项目没有使用场景或者价值呢?常规的,像一些数据查询,或者填写一些数据提交。这种需求里面有必要使用什么抽象类,什么数据模型吗?
- 为什么在前端圈子里面,很少有看到这方面的内容,现在前端圈子里大多都是在走向函数化,Composition等等,是不是这条路子走的有问题?
首先肯定的是,在我所使用的过程中,数据模型确实非常清晰,有力,牢固的解决了我所面到的业务问题,所以它是有价值的。
至于和常规的需求,到底应该用什么好呢?哈哈,这个问题有个比较无赖的回答,小孩子才考虑什么要什么不要,成年人什么都要,没有什么技术是非黑即白的。
Vite 就只能在 Vue 的项目里面使用吗?
什么合适用什么,简单的数据查询展示不需要这么精细的数据处理,当然可以直接拿来即用咯,解决业务问题的方法就是好方法!
至于Composition API,其实在商品发布的重构过程中,基本绝大多数都是使用这种设计思路来实现的,这样的设计确实能让我们清晰的分辨每个方法是干什么的,是否会影响交互,以及这样的交互是在做什么,每个交互都在一个位置维护和处理,后面我会单独写一篇介绍。
实践过程中发现,数据模型和Composition API并不冲突,一个是用来处理数据层,一个是用来处理视图层,它们相辅相成结合一些订阅模式的设计,就会让整个项目的划分异常清晰,我十分建议大家在以后遇到单点项目较为复杂时能够使用这一套思路来解决业务问题!