- 1. 蠕虫病毒简介
- 2. 缓冲区溢出
- 3. 缓冲区溢出举例
- 4. 缓冲区溢出的危害
- 5. 内存在计算机中的排布方式
- 6. 计算机中越界访问的后果
- 7. 避免缓冲区溢出的三种方法
- 7.1 栈随机化
- 7.2 检测栈是否被破坏
- 7.3 限制可执行代码区域
- 8. 总结
蠕虫病毒是一种常见的利用Unix系统中的缺点来进行攻击的病毒。缓冲区溢出一个常见的后果是:黑客利用函数调用过程中程序的返回地址,将存放这块地址的指针精准指向计算机中存放攻击代码的位置,造成程序异常中止。为了防止发生严重的后果,计算机会采用栈随机化,利用金丝雀值检查破坏栈,限制代码可执行区域等方法来尽量避免被攻击。虽然,现代计算机已经可以“智能”查错了,但是我们还是要养成良好的编程习惯,尽量避免写出有漏洞的代码,以节省宝贵的时间!
1. 蠕虫病毒简介
蠕虫是一种可以自我复制的代码,并且通过网络传播,通常无需人为干预就能传播。蠕虫病毒入侵并完全控制一台计算机之后,就会把这台机器作为宿主,进而扫描并感染其他计算机。当这些新的被蠕虫入侵的计算机被控制之后,蠕虫会以这些计算机为宿主继续扫描并感染其他计算机,这种行为会一直延续下去。蠕虫使用这种递归的方法进行传播,按照指数增长的规律分布自己,进而及时控制越来越多的计算机。
2. 缓冲区溢出
缓冲区溢出是指计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。理想的情况是:程序会检查数据长度,而且并不允许输入超过缓冲区长度的字符。但是绝大多数程序都会假设数据长度总是与所分配的储存空间相匹配,这就为缓冲区溢出埋下隐患。操作系统所使用的缓冲区,又被称为“堆栈”,在各个操作进程之间,指令会被临时储存在“堆栈”当中,“堆栈”也会出现缓冲区溢出。
3. 缓冲区溢出举例
void echo()
{
char buf[4]; /*buf故意设置很小*/
gets(buf);
puts(buf);
}
void call_echo()
{
echo();
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
反汇编如下:
/*echo*/
000000000040069c <echo>:
40069c:48 83 ec 18 sub $0x18,%rsp /*0X18 == 24,分配了24字节内存。计算机会多分配一些给缓冲区*/
4006a0:48 89 e7 mov %rsp,%rdi
4006a3:e8 a5 ff ff ff callq 40064d <gets>
4006a8::48 89 e7 mov %rsp,%rdi
4006ab:e8 50 fe ff ff callq callq 400500 <puts@plt>
4006b0:48 83 c4 18 add $0x18,%rsp
4006b4:c3 retq
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
/*call_echo*/
4006b5:48 83 ec 08 sub $0x8,%rsp
4006b9:b8 00 00 00 00 mov $0x0,%eax
4006be:e8 d9 ff ff ff callq 40069c <echo>
4006c3:48 83 c4 08 add $0x8,%rsp
4006c7:c3 retq
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
在这个例子中,我们故意把buf设置的很小。运行该程序,我们在命令行中输入012345678901234567890123,程序立马就会报错:Segmentation fault。
要想明白为什么会报错,我们需要通过分析反汇编来了解其在内存是如何分布的。具体如下图所示:
如下图所示,此时计算机为buf分配了24字节空间,其中20字节还未使用。
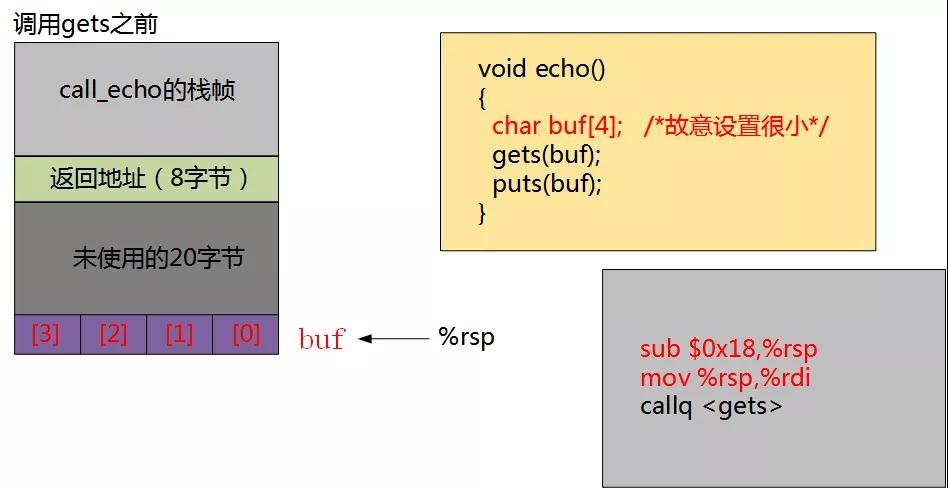
此时,准备调用echo函数,将其返回地址压栈。
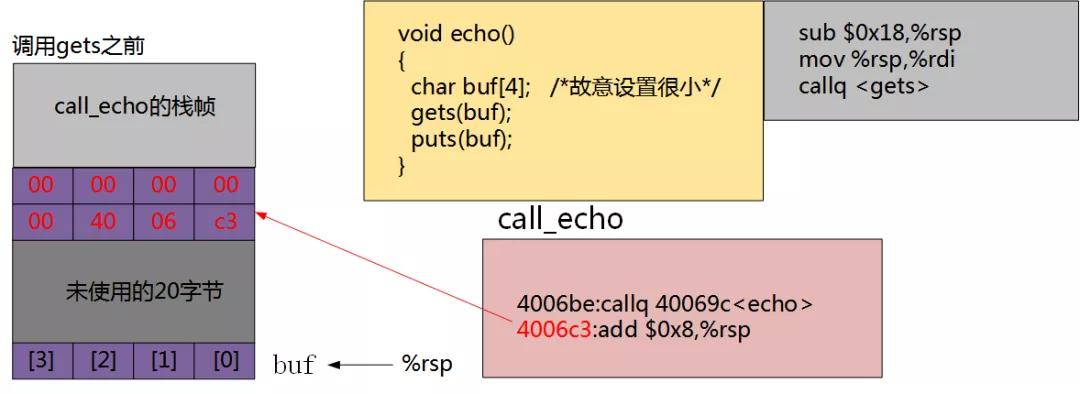
当我们输入“0123456789012345678 9012"时,缓冲区已经溢出,但是并没有破坏程序的运行状态。
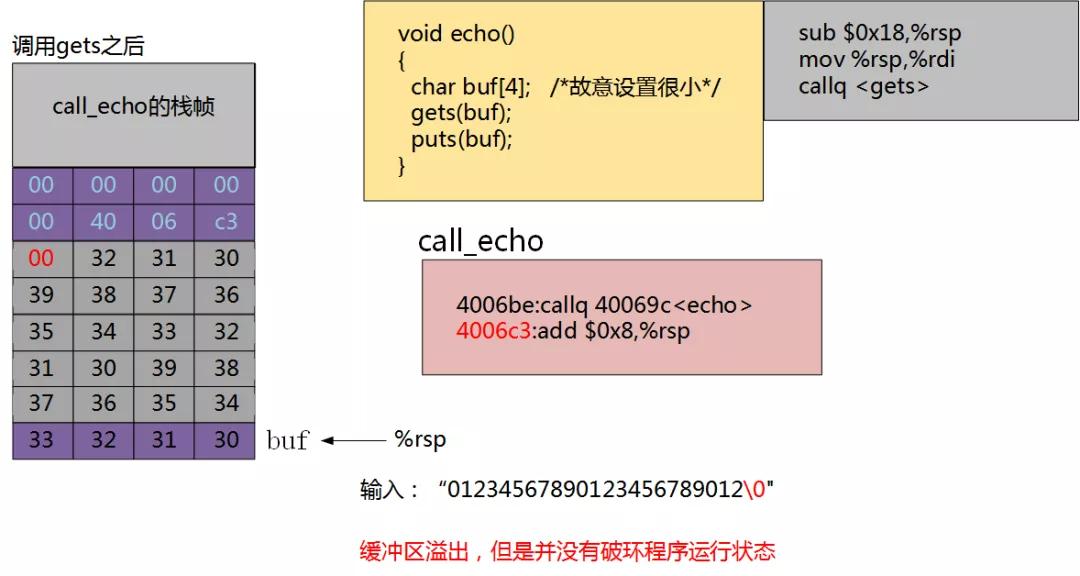
当我们输入:“012345678901234567 890123"。缓冲区溢出,返回地址被破坏,程序返回 0x0400600。
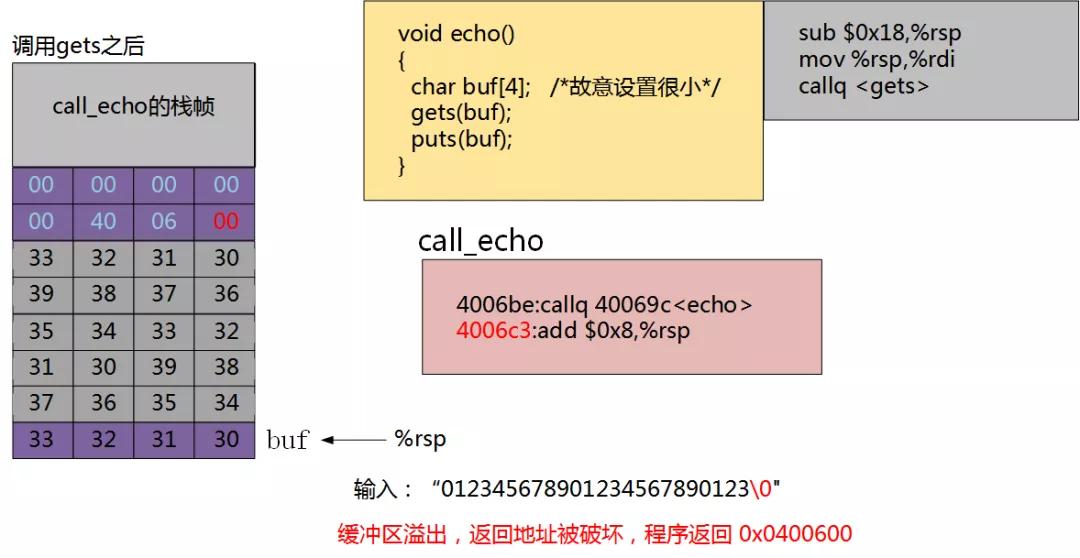
这样程序就跳转到了计算机中其他内存的位置,很大可能这块内存已经被使用。跳转修改了原来的值,所以程序就会中止运行。
黑客可以利用这个漏洞,将程序精准跳转到其存放木马的位置(如nop sled技术),然后就会执行木马程序,对我们的计算机造成破坏。
4. 缓冲区溢出的危害
缓冲区溢出可以执行非授权指令,甚至可以取得系统特权,进而进行各种非法操作。第一个缓冲区溢出攻击--Morris蠕虫,发生在二十年前,它曾造成了全世界6000多台网络服务器瘫痪。
在当前网络与分布式系统安全中,被广泛利用的50%以上都是缓冲区溢出,其中最著名的例子是1988年利用fingerd漏洞的蠕虫。而缓冲区溢出中,最为危险的是堆栈溢出。因为入侵者可以利用堆栈溢出,在函数返回时改变返回程序的地址,让其跳转到任意地址。带来的危害有两种,一种是程序崩溃导致拒绝服务,另外一种就是跳转并且执行一段恶意代码,比如得到shell,然后为所欲为。
5. 内存在计算机中的排布方式
内存在计算机中的排布方式如下,从上到下依次为共享库,栈,堆,数据段,代码段。各个段的作用简介如下:
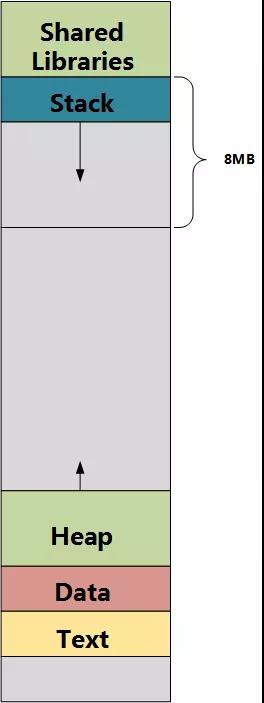
共享库:共享库以.so结尾.(so==share object)在程序的链接时候并不像静态库那样在拷贝使用函数的代码,而只是作些标记。然后在程序开始启动运行的时候,动态地加载所需模块。所以,应用程序在运行的时候仍然需要共享库的支持。共享库链接出来的文件比静态库要小得多。
栈:栈又称堆栈,是用户存放程序临时创建的变量,也就是我们函数{}中定义的变量,但不包括static声明的变量,static意味着在数据段中存放变量。
除此之外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中,由于栈的先进后出特点,所以栈特别方便用来保存、恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存,交换临时数据的内存区。在X86-64 Linux系统中,栈的大小一般为8M(用ulitmit - a命令可以查看)。
堆:堆是用来存放进程中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态分配到堆上,当利用free等函数释放内存时,被释放的内存从堆中被剔除。
堆存放new出来的对象,栈里面所有对象都是在堆里面有指向的。假如栈里指向堆的指针被删除,堆里的对象也要释放(C++需要手动释放)。当然现在面向对象程序都有'垃圾回收机制',会定期的把堆里没用的对象清除出去。
数据段:数据段通常用来存放程序中已初始化的全局变量和已初始化为非0的静态变量的一块内存区域,属于静态内存分配。直观理解就是C语言程序中的全局变量(注意:全局变量才算是程序的数据,局部变量不算程序的数据,只能算是函数的数据)
代码段:代码段通常用来存放程序执行代码的一块区域。这部分区域的大小在程序运行前就已经确定了,通常这块内存区域属于只读,有些架构也允许可写,在代码段中也有可能包含以下只读的常数变量,例如字符串常量等。
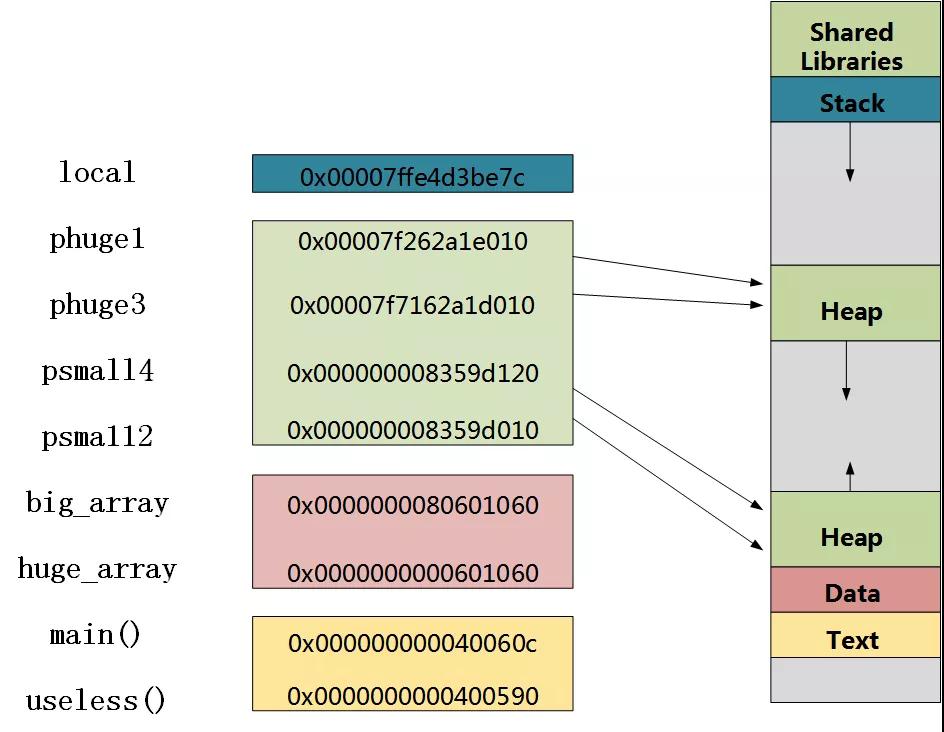
下面举个例子来看下代码中各个部分在计算机中是如何排布的。
#include <stdio.h>
#include <stdlib.h>
char big_array[1L<<24]; /*16 MB*/
char huge_array[1L<<31]; /*2 GB*/
int global = 0;
int useless() {return 0;}
int main()
{
void *phuge1,*psmall2,*phuge3,*psmall4;
int local = 0;
phuge1 = malloc(1L<<28); /*256 MB*/
psmall2 = malloc(1L<<8); /*256 B*/
phuge3 = malloc(1L<<32); /*4 GB*/
psmall4 = malloc(1L<<8); /*256 B*/
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
上述代码中,程序中的各个变量在内存的排布方式如下图所示。根据颜色可以一一对应起来。由于了local变量存放在栈区,四个指针变量使用了malloc分配了空间, 所以存放在堆上,两个数组big_ array,huge_array存放在数据段,main,useless函数的其他部分存放在代码段中。
6. 计算机中越界访问的后果
下面再看一个例子,看下越界访问内存会有什么结果。
typedef struct
{
int a[2];
double d;
}struct_t;
double fun(int i)
{
volatile struct_t s;
s.d = 3.14;
s.a[i] = 1073741824; /*可能越界*/
return s.d;
}
int main()
{
printf("fun(0):%lf\n",fun(0));
printf("fun(1):%lf\n",fun(1));
printf("fun(2):%lf\n",fun(2));
printf("fun(3):%lf\n",fun(3));
printf("fun(6):%lf\n",fun(6));
return 0;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
打印结果如下所示:
fun(0):3.14
fun(1):3.14
fun(2):3.1399998664856
fun(3):2.00000061035156
fun(6):Segmentation fault
- 1.
- 2.
- 3.
- 4.
- 5.
在上面的程序中,我们定义了一个结构体,其中 a 数组中包含两个整数值,还有 d 一个双精度浮点数。在函数fun中,fun函数根据传入的参数i来初始化a数组。显然,i的值只能为0和1。在fun函数中,同时还设置了d的值为3.14。当我们给fun函数传入0和1时可以打印出正确的结果3.14。但是当我们传入2,3,6时,奇怪的现象发生了。为什么fun(2)和fun(3)的值会接近3.14,而fun(6)会报错呢?
要搞清楚这个问题,我们要明白结构体在内存中是如何存储的,具体如下图所示。
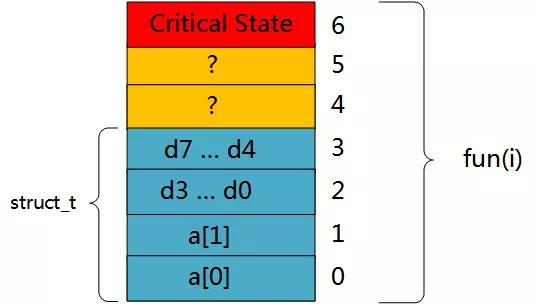
结构体在内存中的存储方式
GCC默认不检查数组越界(除非加编译选项)。而越界会修改某些内存的值,得出我们意想不到的结果。即使有些数据相隔万里,也可能受到影响。当一个系统这几天运行正常时,过几天可能就会崩溃。(如果这个系统是运行在我们的心脏起搏器,又或者是航天飞行器上,那么这无疑将会造成巨大的损失!)
如上图所示,对于最下面的两个元素,每个块代表 4 字节。a数组占用8个字节,d变量占用8字节,d排布在a数组的上方。所以我们会看到,如果我引用 a[0] 或者 a[1],会按照正常修改该数组的值。但是当我调用 fun(2) 或者 fun(3)时,实际上修改的是这个浮点数 d 所对应的内存位置。这就是为什么我们打印出来的fun(2)和fun(3)的值如此接近3.14的原因。
当输入 6 时,就修改了对应的这块内存的值。原来这块内存可能存储了其他用于维持程序运行的内容,而且是已经分配的内存。所以,我们程序就会报出Segmentation fault的错误。
7. 避免缓冲区溢出的三种方法
为了在系统中插入攻击代码,攻击者既要插入代码,也要插入指向这段代码的指针。这个指针也是攻击字符串的一部分。产生这个指针需要知道这个字符串放置的栈地址。在过去,程序的栈地址非常容易预测。对于所有运行同样程序和操作系统版本的系统来说,在不同的机器之间,栈的位置是相当固定的。因此,如果攻击者可以确定一个常见的Web服务器所使用的栈空间,就可以设计一个在许多机器上都能实施的攻击。
7.1 栈随机化
栈随机化的思想使得栈的位置在程序每次运行时都有变化。因此,即使许多机器都运行同样的代码,它们的栈地址都是不同的。实现的方式是:程序开始时,在栈上分配一段0 ~ n字节之间的随机大小的空间,例如,使用分配函数alloca在栈上分配指定字节数量的空间。程序不使用这段空间,但是它会导致程序每次执行时后续的栈位置发生了变化。分配的范围n必须足够大,才能获得足够多的栈地址变化,但是又要足够小,不至于浪费程序太多的空间。
int main()
{
long local;
printf("local at %p\n",&local);
return 0;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
这段代码只是简单地打印出main函数中局部变量的地址。在32位 Linux上运行这段代码10000次,这个地址的变化范围为0xff7fc59c到0xffffd09c,范围大小大约是。在64位 Linux机器上运行,这个地址的变化范围为0x7fff0001b698到0x7ffffffaa4a8,范围大小大约是 。
其实,一个好的黑客专家,可以使用暴力破坏栈的随机化。对于32位的机器,我们枚举个地址就能猜出来栈的地址。对于64位的机器,我们需要枚举次。如此看来,栈的随机化降低了病毒或者蠕虫的传播速度,但是也不能提供完全的安全保障。
7.2 检测栈是否被破坏
??计算机的第二道防线是能够检测到何时栈已经被破坏。我们在echo函数示例中看到,当访问缓冲区越界时,会破坏程序的运行状态。在C语言中,没有可靠的方法来防止对数组的越界写。但是,我们能够在发生了越界写的时候,在造成任何有害结果之前,尝试检测到它。
GCC在产生的代码中加人了一种栈保护者机制,来检测缓冲区越界。其思想是在栈帧中任何局部缓冲区与栈状态之间存储一个特殊的金丝雀值,如下图所示:
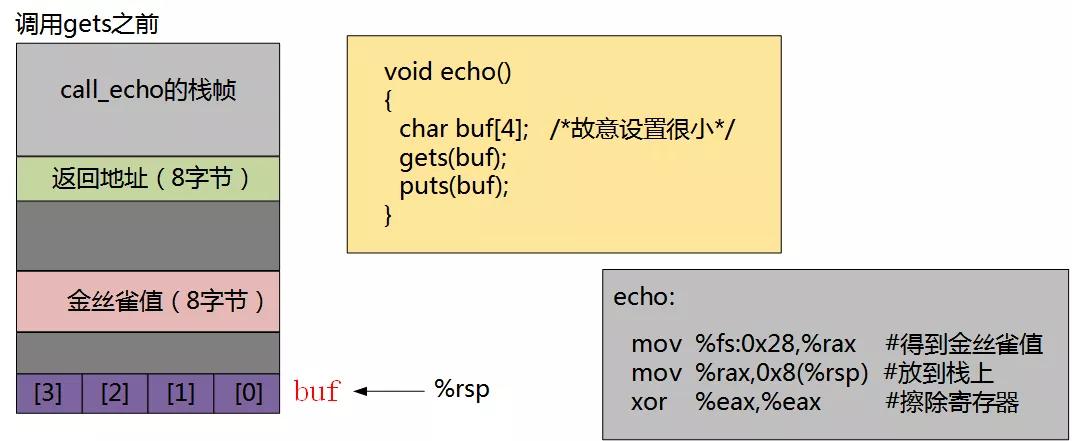
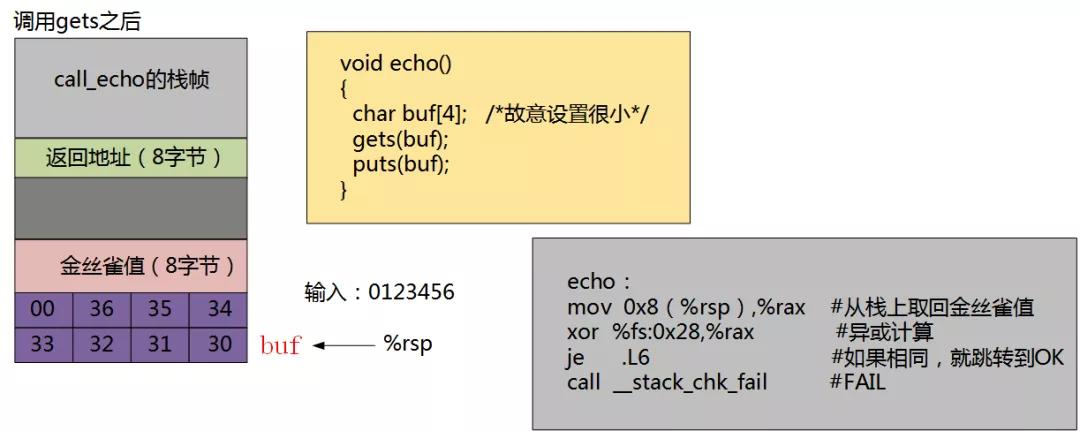
这个金丝雀值,也称为哨兵值,是在程序每次运行时随机产生的,因此,攻击者很难猜出这个哨兵值。在恢复寄存器状态和从函数返回之前,程序检查这个金丝雀值是否被该函数的某个操作或者该函数调用的某个函数的某个操作改变了。如果是的,那么程序异常中止。
英国矿井饲养金丝雀的历史大约起始1911年。当时,矿井工作条件差,矿工在下井时时常冒着中毒的生命危险。后来,约翰·斯科特·霍尔丹(John Scott Haldane)在经过对一氧化碳一番研究之后,开始推荐在煤矿中使用金丝雀检测一氧化碳和其他有毒气体。金丝雀的特点是极易受有毒气体的侵害,因为它们平常飞行高度很高,需要吸入大量空气吸入足够氧气。因此,相比于老鼠或其他容易携带的动物,金丝雀会吸入更多的空气以及空气中可能含有的有毒物质。这样,一旦金丝雀出了事,矿工就会迅速意识到矿井中的有毒气体浓度过高,他们已经陷入危险之中,从而及时撤离。
GCC会试着确定一个函数是否容易遭受栈溢出攻击,并且自动插入这种溢出检测。实际上,对于前面的栈溢出展示,我们可以使用命令行选项“-fno- stack- protector”来阻止GCC产生这种代码。当用这个选项来编译echo函数时(允许使用栈保护),得到下面的汇编代码
//void echo
subq $24,%rsp Allocate 24 bytes on stack
movq %fs:40,%rax Retrieve canary
movq %rax,8(%rsp) Store on stack
xorl %eax, %eax Zero out register //从内存中读出一个值
movq %rsp, %rdi Compute buf as %rsp
call gets Call gets
movq ‰rsp,%rdi Compute buf as %rsp
call puts Call puts
movq 8(%rsp),%rax Retrieve canary
xorq %fs:40,%rax Compare to stored value //函数将存储在栈位置处的值与金丝雀值做比较
je .L9 If =, goto ok
call __stack_chk_fail Stack corrupted
.L9
addq $24,%rsp Deallocate stack space
ret
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
这个版本的函数从内存中读出一个值(第4行),再把它存放在栈中相对于%rsp偏移量为8的地方。指令参数各fs:40指明金丝雀值是用段寻址从内存中读入的。段寻址机制可以追溯到80286的寻址,而在现代系统上运行的程序中已经很少见到了。将金丝雀值存放在一个特殊的段中,标记为只读,这样攻击者就不能覆盖存储金丝雀值。在恢复寄存器状态和返回前,函数将存储在栈位置处的值与金丝雀值做比较(通过第10行的xorq指令)。如果两个数相同,xorq指令就会得到0,函数会按照正常的方式完成。非零的值表明栈上的金丝雀值被修改过,那么代码就会调用一个错误处理例程。
栈保护很好地防止了缓冲区溢出攻击破坏存储在程序栈上的状态。一般只会带来很小的性能损失。
7.3 限制可执行代码区域
最后一招是消除攻击者向系统中插入可执行代码的能力。一种方法是限制哪些内存区域能够存放可执行代码。在典型的程序中,只有保存编译器产生的代码的那部分内存才需要是可执行的。其他部分可以被限制为只允许读和写。
许多系统都有三种访问形式:读(从内存读数据)、写(存储数据到内存)和执行(将内存的内容看作机器级代码)。以前,x86体系结构将读和执行访问控制合并成一个1位的标志,这样任何被标记为可读的页也都是可执行的。栈必须是既可读又可写的,因而栈上的字节也都是可执行的。已经实现的很多机制,能够限制一些页是可读但是不可执行的,然而这些机制通常会带来严重的性能损失。
8. 总结
计算机提供了多种方式来弥补我们犯错可能产生的严重后果,但是最关键的还是我们尽量减少犯错。
例如,对于gets,strcpy等函数我们应替换为 fgets,strncpy等。在数组中,我们可以将数组的索引声明为size_t类型,从根本上防止它传递负数。此外,还可以在访问数组前来加上num小于ARRAY_MAX 语句来检查数组的上界。总之,要养成良好的编程习惯,这样可以节省很多宝贵的时间。同时最后也推荐两本相关书籍如下所示。
代码大全(第二版)
高质量程序设计指南
本文参考:《深入理解计算机系统》 https://baike.baidu.com/item/%E7%BC%93%E5%86%B2%E5%8C%BA%E6%BA%A2%E5%87%BA/678453?fr=aladdin#reference-[1]-36638-wrap https://baike.baidu.com/item/%E8%A0%95%E8%99%AB%E7%97%85%E6%AF%92/4094075?fr=aladdin https://zhuanlan.zhihu.com/p/185792677
本文转载自微信公众号「嵌入式与Linux那些事」,可以通过以下二维码关注。转载本文请联系嵌入式与Linux那些事公众号。