本文转载自微信公众号「SH的全栈笔记」,作者SH。转载本文请联系SH的全栈笔记公众号。
基础概念Broker
首先我们要知道,使用RocketMQ时我们经历了什么。那就是生产者发送一条消息给RocketMQ,RocketMQ拿到这条消息之后将其持久化存储起来,然后消费者去找MQ消费这条消息。
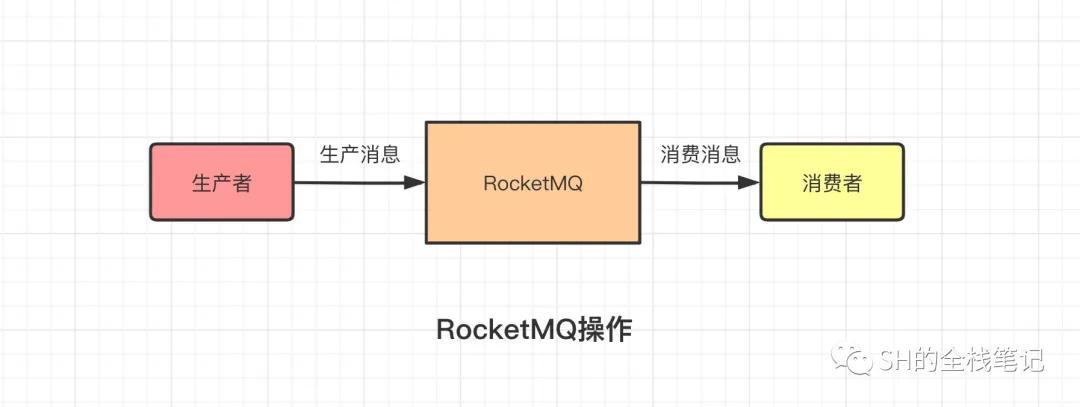
RocketMQ操作
上图中,RocketMQ被标识为了一个单点,但事实上肯定不是如此,对于可以随时横向扩展的服务来说,生产者向MQ生产消息的数量也会随之而变化,所以一个合格成熟的MQ必然是要能够处理这种情况的;而且MQ自身需要做到高可用,否则一旦这个单点宕机,那所有存储在MQ中的消息就全部丢失且无法找回了。
所以在实际的生产环境中,肯定是会部署一个MQ的集群。而在RocketMQ中,这个“实例”有个专属名词,叫做Broker。并且,每个Broker都会部署一个Slave Broker,Master Broker会定时的向Slave Broker同步数据,形成一个Broker的主从架构。
那么问题来了,在微服务的架构中,部署的服务也存在多实例部署的情况,服务之间相互调用是通过注册中心来获取对应服务的实例列表的。
拿Spring Cloud举例,服务通过Eureka注册中心获取到某个服务的全部实例,然后交给Ribbon,Ribbon联动Eureka,从Eureka处获取到服务实例的列表,然后通过负载均衡算法选出一个实例,最后发起请求。
同理,此时MQ中存在多个Broker实例,那生产者如何得知MQ集群中有多少Broker实例呢?自己应该连接哪个实例?
首先我们直接排除在代码里Hard Code,具体原因我觉得应该不用再赘述了。RocketMQ是如何解决这个问题呢?这就是接下来我们要介绍的NameServer了。
NameServer
NameServer可以被简单的理解为上一小节中提到的注册中心,所有的Broker的在启动的时候都会向NameServer进行注册,将自己的信息上报。这些信息除了Broker的IP、端口相关数据,还有RocketMQ集群的路由信息,路由信息后面再聊。
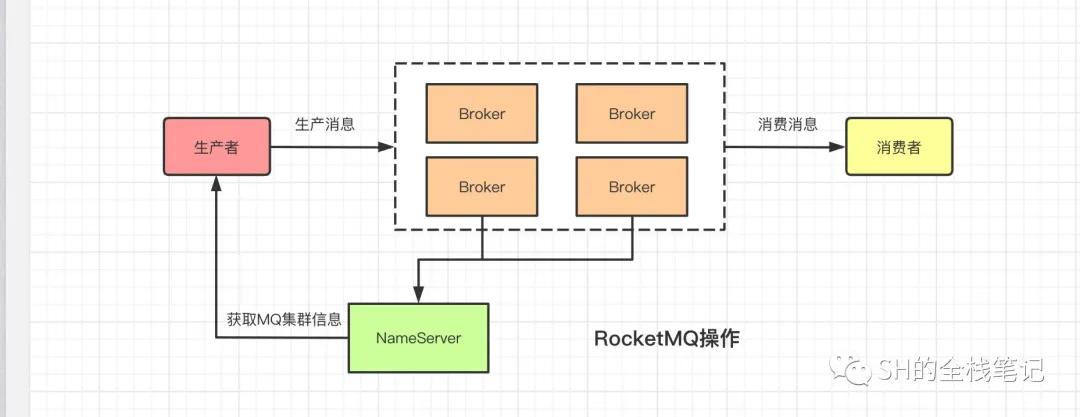
RocketMQ操作
有了NameServer,客户端启动之后会和NameServer交互,获取到当前RocketMQ集群中所有的Broker信息、路由信息。这样一来,生产者就知道自己需要连接的Broker信息了,就可以进行消息投递。
那么问题来了,如果在运行过程中,如果某个Broker突然宕机,NameServer会如何处理?
这需要提到RocketMQ的这续约机制和故障感知机制。Broker在完成向NameServer的注册之后,会每隔30秒向NameServer发送心跳进行续约;如果NameServer感知到了某个Broker超过了120秒都没有发送心跳,则会认为这个Broker不可用,将其从自己维护的信息中移除。
这套机制,和Spring Cloud中的Eureka的实现如出一辙。Eureka中的Service在启动之后也会向Eureka注册自己,这样一来其他的服务就可以向该服务发起请求,交换数据。Service每隔30秒会向Eureka发送心跳续约,如果某个Service超过了90秒没有发送心跳,Eureka就会认为该服务宕机,将其从Eureka维护的注册表中移除。
上面图中我聊到了多实例部署,这个多实例部署和微服务中的多实例部署还不太一样,微服务中,所有的服务都是无状态的,可以横向的扩展,而在RocketMQ中,每个Broker所存的数据可能都不一样。
我们来看一下RocketMQ的简单使用。
- Message msg = new Message(
- "TopicTest",
- "TagA",
- ("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET)
- );
- SendResult sendResult = producer.send(msg);
可以看到,Message的第一个参数,为当前这条消息指定了一个Topic,那Topic又是什么呢?
Topic
Topic是对发送到RocketMQ中的消息的逻辑分类,例如我们的订单系统、积分系统、仓储系统都会用到这个MQ,为了对其进行区分,我们就可以为不同的系统建立不同的Topic。
那为什么说是逻辑分区呢?因为RocketMQ在真实存储中,并不是一个Broker就存储一个Topic的数据,道理很简单,如果当前这个Broker宕机,甚至极端情况磁盘坏了,那这个Topic的数据就会永久丢失。
所以在真实存储中,消息是分布式的存储在多个Broker上的,这这些分散在多个Broker上的存储介质叫MessageQueue,如果你熟悉Kafka的底层原理,就知道这个跟Kafka中的Partition是同类的实现。
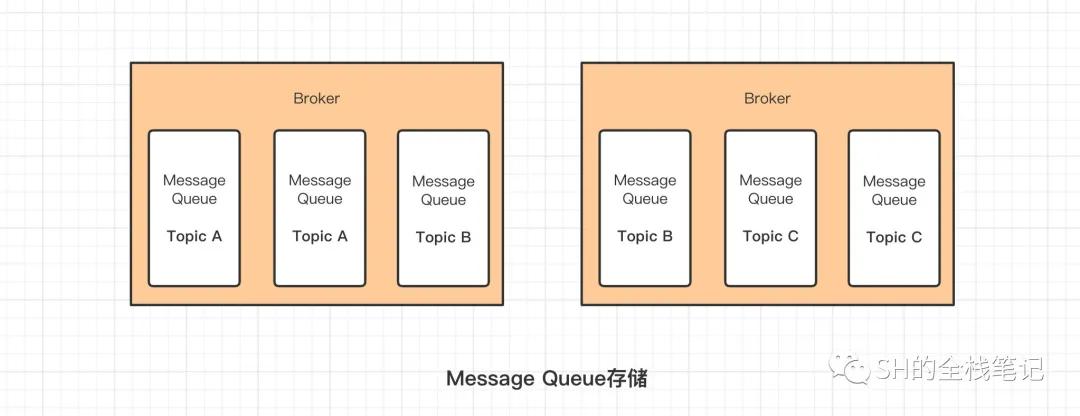
Message Queue存储
通过上图可以看出,同一个Topic的数据,被分成了好几份,分别存储在不同的Broker上,那RocketMQ为什么要这么实现?
首先,一个Topic中如果只有一个Queue,那么消费者在消费时的速度必然受到影响;而如果一个Topic有很多个Queue,那么Consumer就可以将消费操作同时进行,从而扛住更多的并发。
除此之外,单台机器的资源是有限的。一个Topic的消息量可能会非常之巨大,一台机器的磁盘很快就会被塞满。所以RocketMQ将一个Topic的数据分摊给了多台机器,进行分散存储。其本质上就是一个数据分片存储的一种机制。
所以我们知道了,发送到某个Topic的数据是分布式的存储在多个Broker中的MessageQueue上的。
Broker消息存储原理
那Producer发送到Broker中的消息,到底是以什么方式存储的呢?答案是Commit Log,Broker收到消息,会将该消息采用顺序写入的方式,追加到磁盘上的Commit Log文件中,每个Commit Log大小为1G,如果写满了1G则会新建一个Commit Log继续写,Commit Log文件的特点是顺序写、随机读。
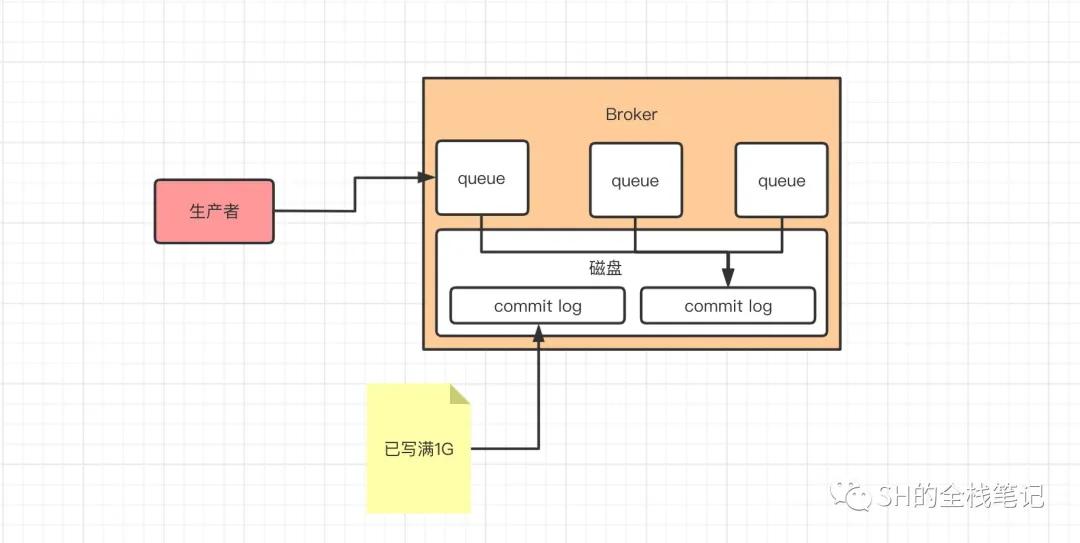
Topic详情
这就是最底层的存储的方式,那么问题来了,Consumer来取消息的时候,Broker是如何从这一堆的Commit Log中找到相应的数据呢?众所周知,一提到磁盘的I/O操作,就会联想到耗时这两个字,而RocketMQ的一大特点就是高吞吐,看似很矛盾,RocketMQ是如何做的呢?
答案是ConsumeQueue,Broker在写入Commit Log的同时,还会将当前这条消息在Commit Log中的Offset、消息的Size和对应的Tag的Hash写入到ConsumeQueue文件中。每个Message Queue会有相对应的ConsumeQueue文件存储在磁盘上。
和Commit Log一样,一个ConsumeQueue包含了30W条消息,每条消息的大小为20字节,所以每个ConsumeQueue文件的大小约为5.72M;当其写满了之后,会再新建一个ConsumeQueue文件继续写入。
ConsumeQueue是一种逻辑队列,更是一种索引,让Consumer来消费的时候可以快速的从磁盘文件中定位到这条消息。
看到这你可能会想,上面提到的Tag又是个什么东西?
Tag
Tag,标签,用于对同一个Topic内的消息进行分类,为什么还需要对Topic进行消息类型划分呢?
举一个极端的例子,某一个新的服务,需要去消费订单系统的MQ,但是由于业务的特殊性,只需要去消费商品类型为数码产品的订单消息,如果没有Tag,那么该Consumer就会去做判断,该订单消息是否是数码产品类,如果不是,则丢弃,如果是则进行消费。
这样一来,Consumer侧就执行了大量的无用功。引入了Tag之后,Producer在生产消息的时候会给订单打上Tag,Consumer进行消费的时候,可以配置只消费指定的Tag的消息。这样一来就不需要Consumer自己去做这个事情了,RocketMQ会帮我们实现这个过滤。
那其过滤的原理是什么?首先在Broker侧是通过消息中保存的Tag的Hash值进行过滤,然后Consumer侧在去拉取消息的时候还需要再过滤一次。
为什么在Broker过滤了,还需要在Consumer侧再过滤一次?因为Hash冲突,不同的Tag经过Hash算法之后可能会得到一样的值,所以Consumer侧在拉取消息的时候会通过字符串进行二次过滤。
Producer发送消息源码分析
流程总览
首先给出整个发送消息的大致流程,先熟悉这个流程看源码,会更加的清晰一点。
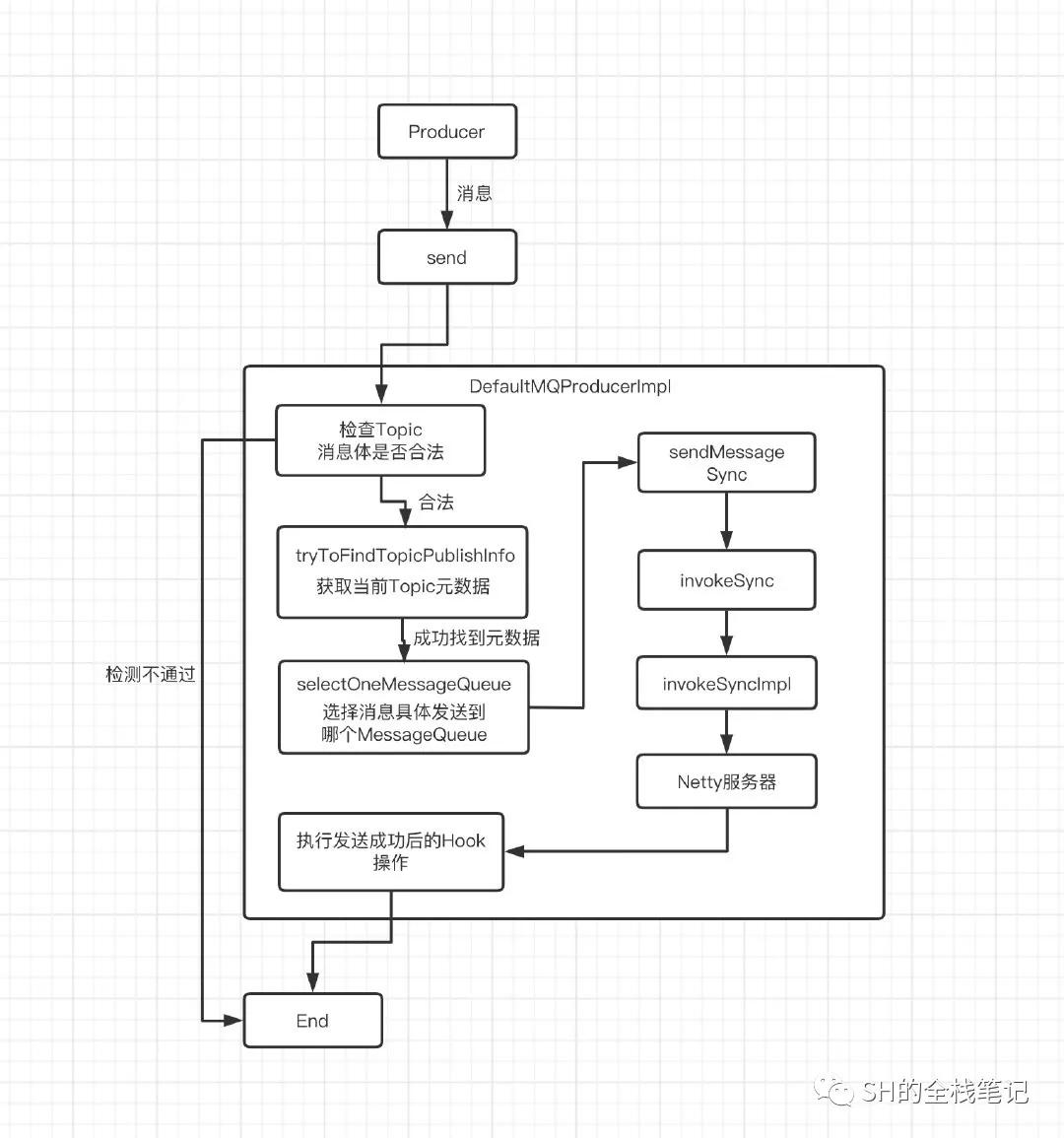
总体流程
初始化Prodcuer
还是按照下面这个例子出发。
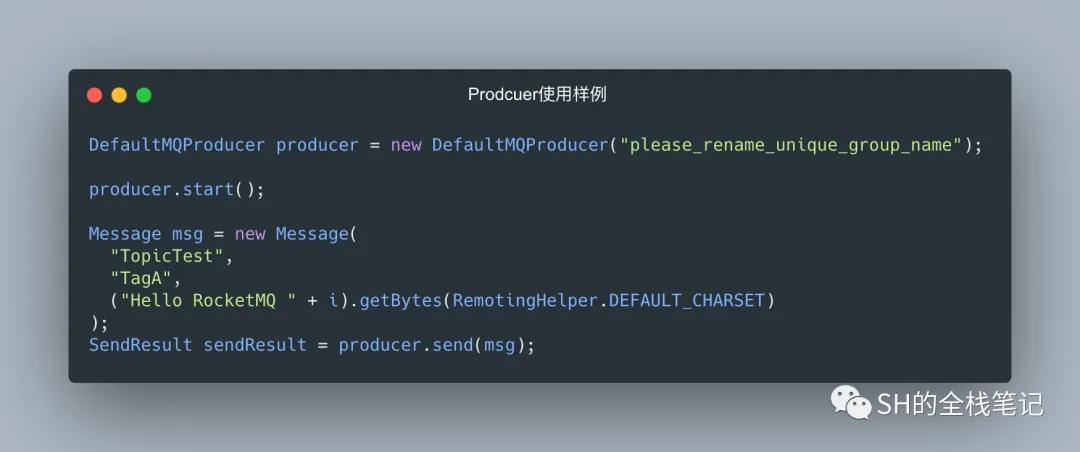
producer使用样例
首先我们会初始化一个DefaultMQProducer,RocketMQ会给这个Producer一个默认的实现DefaultMQProducerImpl。然后producer.start()会启动一个线程池。
合法性校验
接下来就是比较核心的producer.send(msg)了,首先RocketMQ会调用checkMessage来检测发送的消息是否合法。
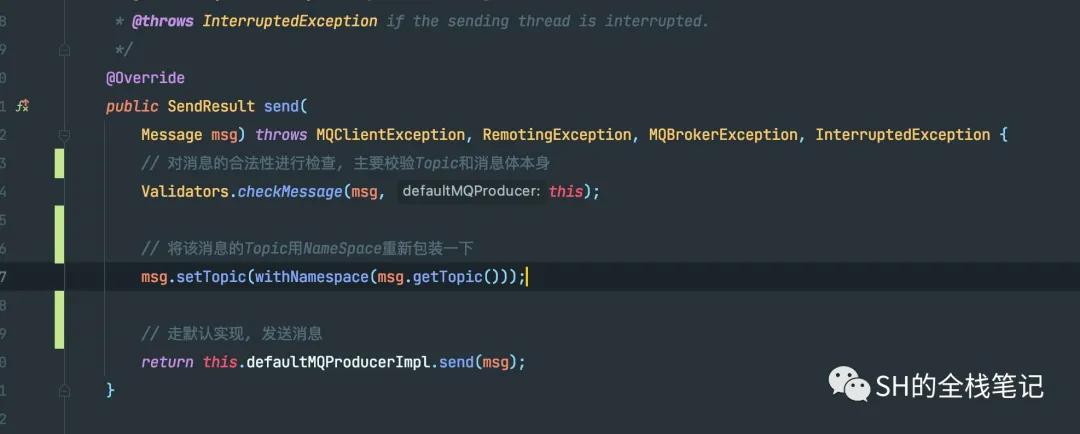
send消息
这些检测包含了待发送的消息是否为空,Topic是否为空、Topic是否包含了非法的字符串、Topic的长度是否超过了最大限制127,然后会去检查Body是否符合发送要求,例如msg的Body是否为空、msg的Body是否超过了最大的限制等等,这里消息的Body最大不能超过4M。
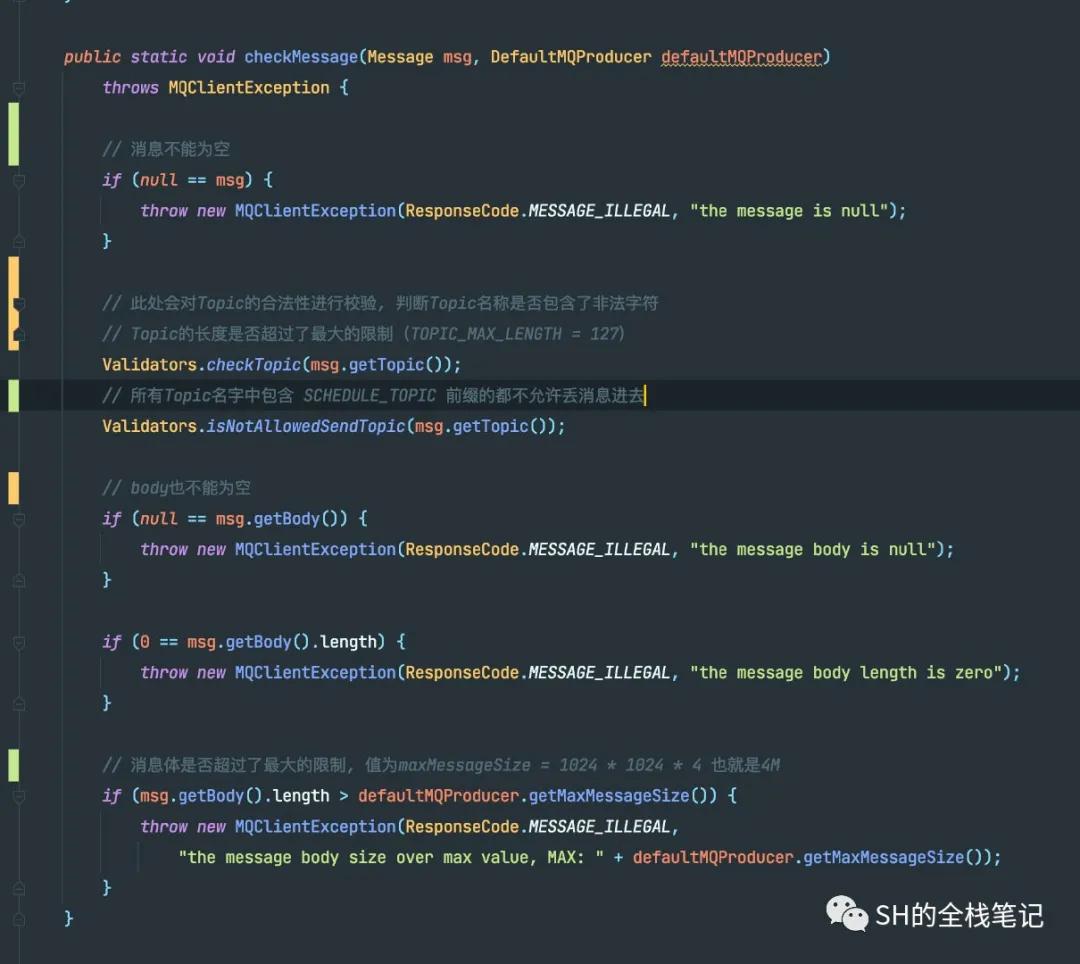
检查消息合法性源码
调用发送消息
对于msg的Topic,RocketMQ会用NameSpace将其包装一层,然后就会调用DefaultMQProducerImpl中的sendDefaultImpl默认实现,发送消息给Broker,默认的发送消息Timeout是3秒。
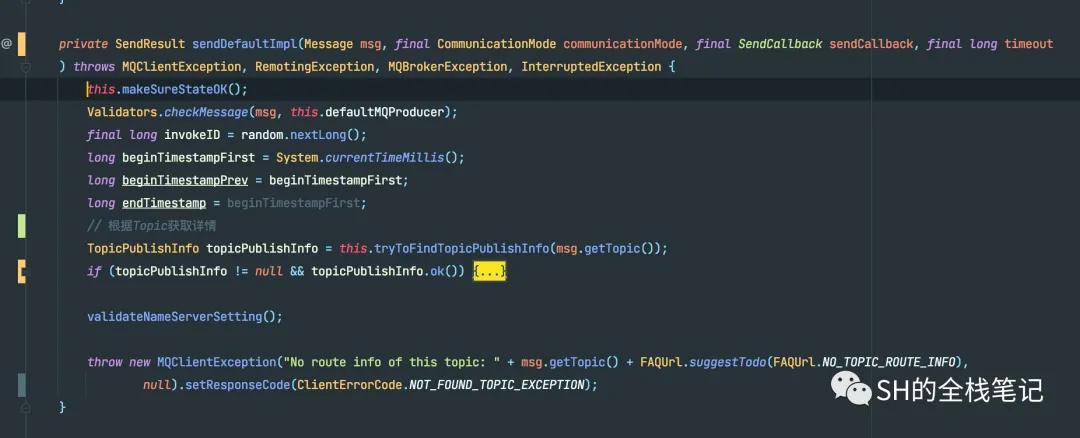
发送消息默认实现
发送消息中,MQ会再次调用checkMessage对消息的合法性再次进行检查,然后就会去尝试获取Topic的详细信息。
所有的Topic的信息都会存在一个叫topicPublishInfoTable的 ConcurrentHashMap中,这个Map中Key就是Topic的字符串,而Value则是TopicPublishInfo。
这个TopicPublishInfo中就包含了之前在基础概念中提到的,从Broker中获取到的相应的元数据,其中就包含了关键的MessageQueue和集群元数据,其基础的结构如下。
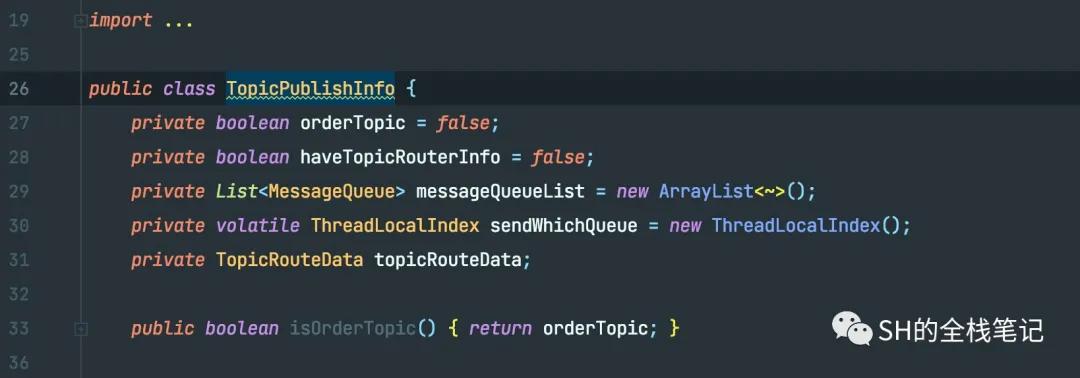
Topic详情
messageQueueList包含了该Topic下的所有的MessageQueue,每个MessageQueue的所属Topic,每个MessageQueue所在的Broker的名称以及专属的queueId。
topicRouteData包含了该Topic下的所有的Queue、Broker相关的数据。
获取Topic详细数据
在最终发送消息前,需要获取到Topic的详情,例如像Broker地址这样的数据,Producer中是通过tryToFindTopicPublishInfo方法获取的,详细的注释我已经写在了下图中。
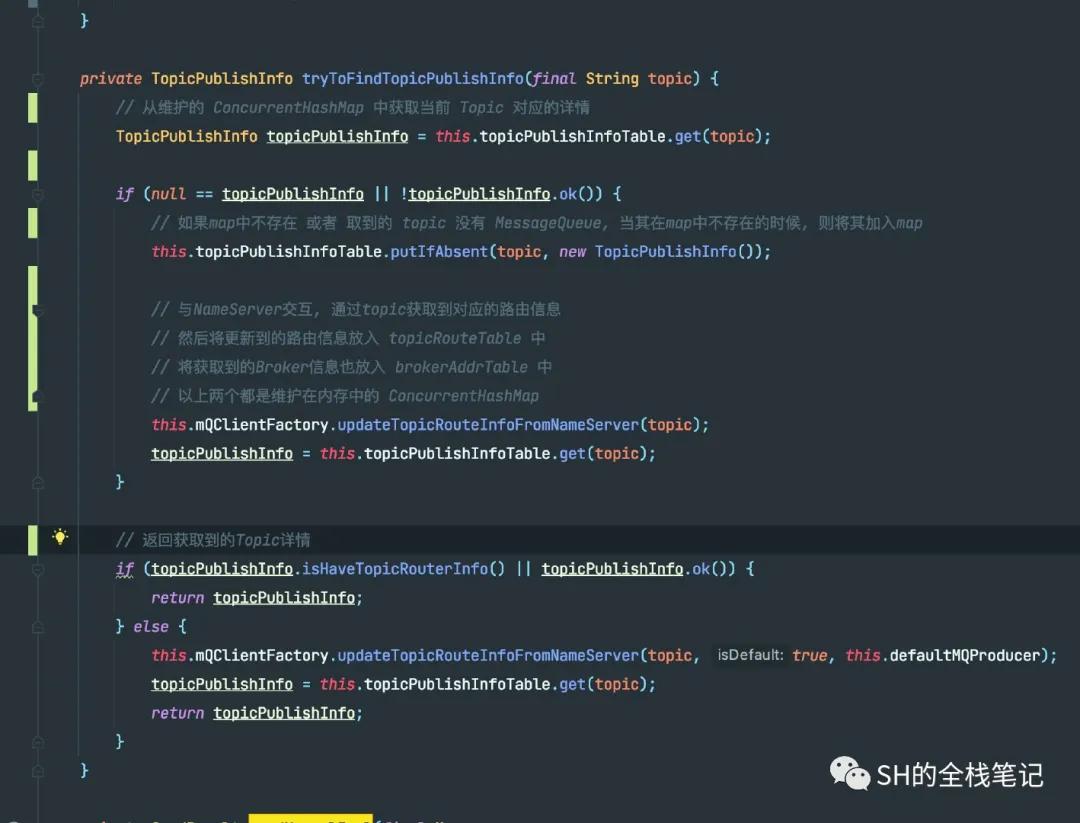
获取topic详情
对于首次使用的Topic,在上面的Map肯定是不存在的。所以RocketMQ会将其加入到Map中去,并且调用方法updateTopicRouteInfoFromNameServer从NameServer处获取该Topic的元数据,将其一并写入Map。初次之外,还会将路由信息、Broker的详细信息分别放入topicRouteTable和brokerAddrTable中,这两个都是Producer维护在内存中的ConcurrentHashMap。
获取到了Topic的详细信息之后,接下来会确认一个发送的重试次数timesTotal,假设timesTotal为N,那么发送消息如果失败就会重试N次。不过当且仅当发送失败的时候才会进行重试,其余的case都不会,例如超时、或者没有选择到合适的MessageQueue。
这个重试的次数timesTotal受到参数communicationMode的影响;CommunicationMode有三个值,分别是SYNC、ASYNC和ONEWAY。RocketMQ默认的实现中,选择了SYNC同步。
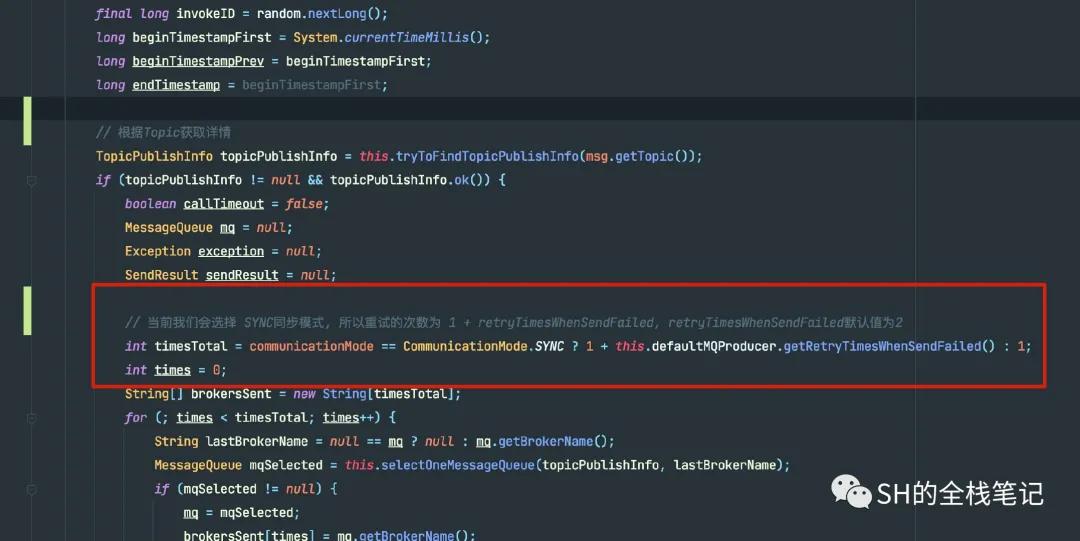
计算重试次数
通过代码我们可以看到,如果是communicationMode是SYNC的话,timesTotal的值为1+retryTimesWhenSendFailed,而retryTimesWhenSendFailed的值默认为2,代表在消息发送失败之后的重试次数。
这样一来,如果我们选择了SYNC的方式,Producer在发送消息的时候默认的重试次数就为3。不过当且仅当发送失败的时候才会进行重试,其余的case都不会。
MessageQueue选择机制
我们之前聊过,一个Topic的数据是分片存储在一个或者多个Broker上的,底层的存储介质为MessageQueue,之前的图中,我们没有给出Producer是如何选择具体发送到哪个MessageQueue,这里我们通过源码来看一下。
Producer中是通过selectOneMessageQueue来进行的Message Queue选择,该方法通过Topic的详细元数据和上次选择的MessageQueue所在的Broker,来决定下一个的选择。
核心的选择逻辑
其核心的选择逻辑是什么呢?用大白话来说,就是选出一个index,然后将其和当前Topic的MessageQueue数量取模。这个index在首次选择的时候,肯定是没有的, RocketMQ会搞一个随机数出来。然后在该值的基础上+1,因为为了通用,在外层看来,这个index上次已经用过了,所以每次获取你都直接帮我+1就好了。
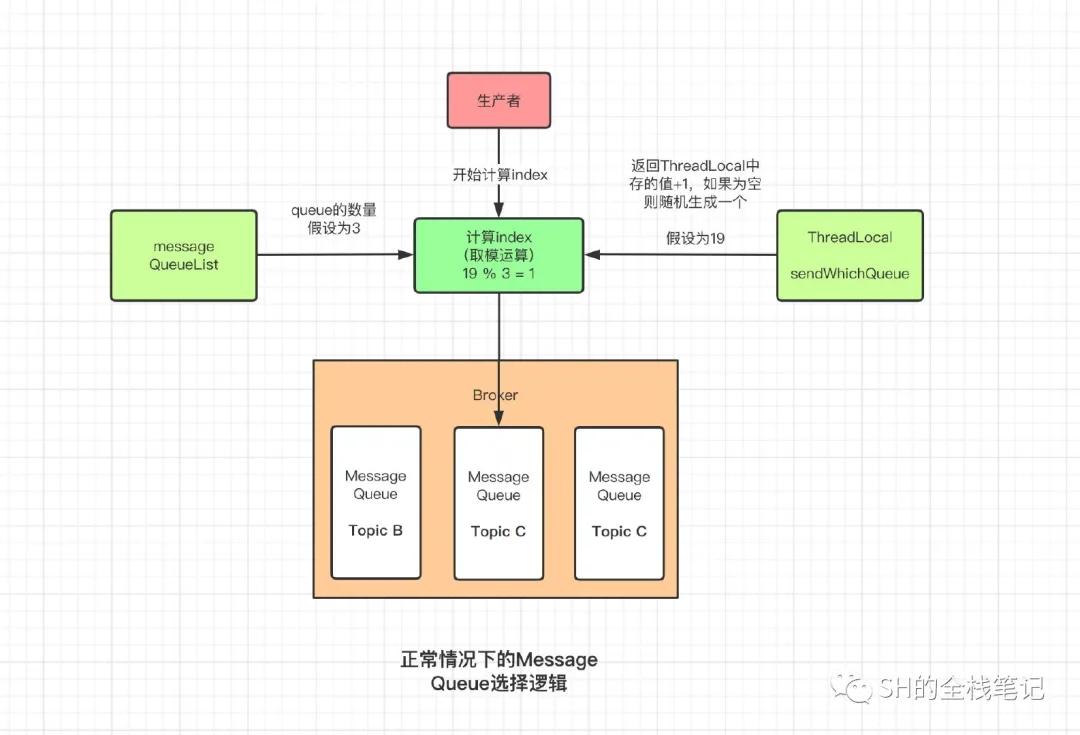
核心的选择机制
上图就是MessageQueue最核心的、最底层的原则机制了。但是由于实际的业务情况十分复杂, RocketMQ在实现中还额外的做了很多的事情。
发送故障延迟下的选择逻辑
在实际的选择过程中,会判断当前是否启用了发送延迟故障,这个由变量sendLatencyFaultEnable的值决定,其默认值是false,也就是默认是不开启的,从代码里我暂时没找到其开启的位置。
不过我们可以聊聊开启之后,会发生什么。它同样会开启for循环,次数为MessageQueue的数量,计算拿到确定的Queue之后,会通过内存的一张表faultItemTable去判断当前这个Broker是否可用,该表是每次发送消息的时候都会去更新它。
如果当前没有可用的Broker,则会触发其兜底的逻辑,再选择一个MessageQueue出来。
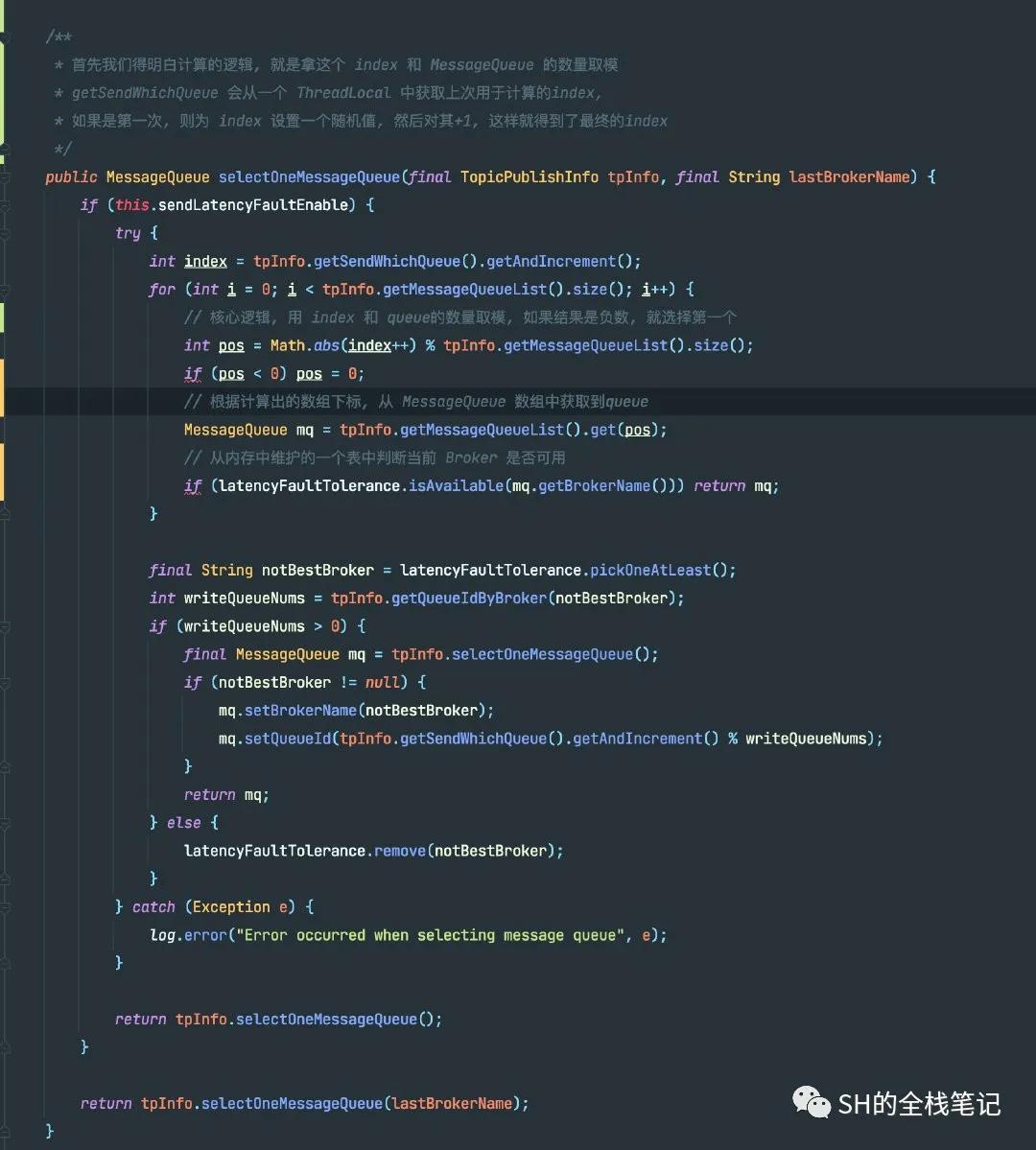
选择queue的源码
常规的选择逻辑
如果当前发送故障延迟没有启用,则会走常规逻辑,同样的会去for循环计算,循环中取到了MessageQueue之后会去判断是否和上次选择的MessageQueue属于同一个Broker,如果是同一个Broker,则会重新选择,直到选择到不属于同一个Broker的MessageQueue,或者直到循环结束。这也是为了将消息均匀的分发存储,防止数据倾斜。
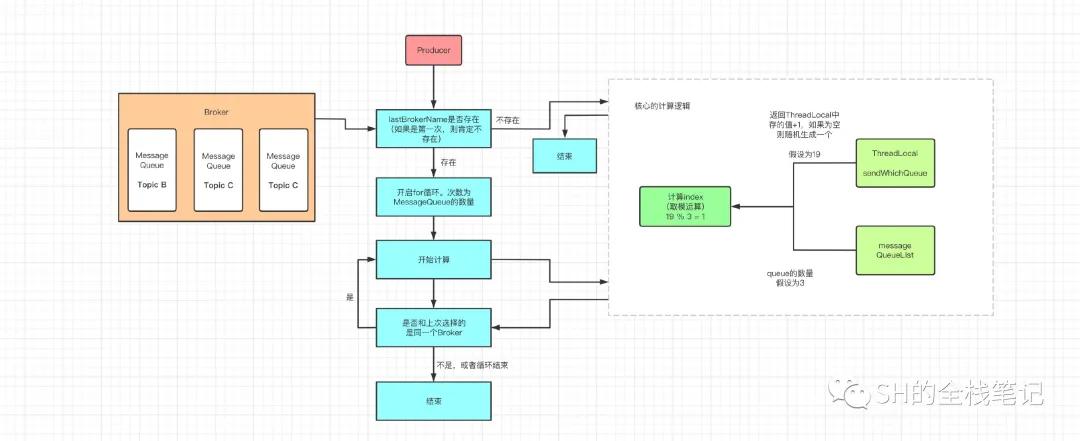
常规逻辑下的选择逻辑
消息发送
最后就会调用Netty相关的组件,将消息发送出去了。
EOF关于RocketMQ中的一些基础的概念,和RocketMQ的Producer发送消息的源码就先分析到这里,后续看缘分再分享其他部分的源码吧。