什么是大数据?
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
大数据应用现状

大数据技术共性
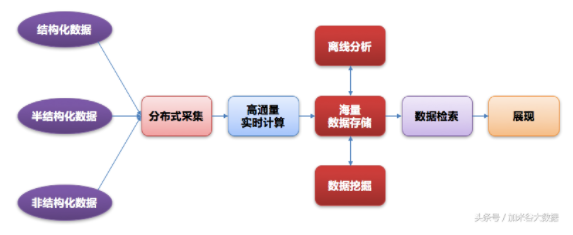
业界主流大数据技术框架
- 磁盘存储HDFS、HBASE、S3、Cassandra、MongoDB、Redis
- 内存存储Alluxio 、Redis
- 数据分析Spark(SQL、Streaming、MLlib、GraphX)、Storm、MapReduce、Mahout、Hive、Pig
- 分步式协调服务ZooKeeper
- 集群系统监控CDH-CMS, Metrics, Grafana、Ambari
- 消息总线kafka、ActiveMQ、Apollo、 Redis
- 索引系统Solr、Lucene、ElasticSearch
大数据组件应用分类
- 数据采集flume、kafka connector、sqoop、socket、sftp、mina
- 实时处理Spark Streaming、Kafka Streams、Storm、Samza、Flink
- 数据存储HDFS、HBASE、S3、Cassandra、MongoDB、Redis、Solr、ElasticSearch
- 离线处理Spark SQL、Hive、Map Reduce、Pig、Impala
- 交互式查询Drill、PresTO、Kylin
- 数据展现Echarts、Tableau、d3js
大数据组件简介
1、Hadoop是Apache开源组织的一个分布式计算框架,提供了一个分布式文件系统 (HDFS)、MapReduce分布式计算及统一资源管理框架(Yarn)的软件架构。
- 为大规模数据的存储提供解决方案(HDFS);
- 解决大规模分步式计算( MapReduce );
- 作为其周边软件Hbase、Hive、Pig、Mahout等的基础平台。

2、HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
- 解决海量数据的存储;
- 解决随机、实时读写大数据;
- 提供简化访问HDFS的编程接口。
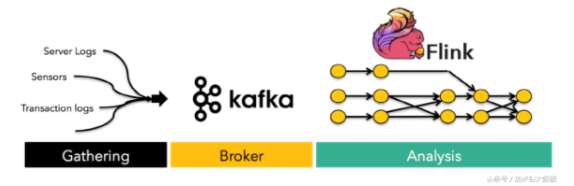
3、kafka是Apache旗下的一个高性能,高吞吐量的分步式消息总线系统。
- 分布式系统相互通信;
- 数据复制、同步;
- 日志同步;
- Delay Queue;
- 广播通知。

4、Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- 解决海量数据的存储;
- 解决大规模数据的分析:SQL。

5、MongoDB 是一个高性能,开源,无模式的文档型数据库,它在许多场景下可用于替代传统的关系型数据库或键/值存储方式。MongoDB不支持SQL,但有自己功能强大的查询语法。MongoDB使用BSON作为数据存储和传输的格式。BSON是一种类似JSON的二进制序列化文档,支持嵌套对象和数组。
- 解决海量数据在线存储;
- 许多情况下可以代替传统关系数据库;
- 代替键/值存储方式。

6、Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。从2013年5月开始,Redis的开发由Pivotal赞助。
7、Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
8、Storm是一个分布式的、容错的实时计算系统。使用Storm进行实时大数据分析。
9、Flink 是可扩展的批处理和流式数据处理的数据处理平台,设计思想主要来源于Hadoop、MPP数据库、流式计算系统等,支持增量迭代计算。
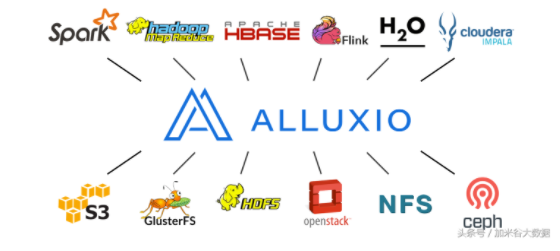
10、Alluxio A memory speed virtual distributed storage. Alluxio是一个高容错的内存分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享。典型特点就是加速读写数据的速度。
11、ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。其典型特点是全文快速检索。