JVM 预热(warm-up)是一个臭名昭著的问题。尽管基于JVM的应用程序有着出色的性能,但是需要一个预热的过程,在预热期间,性能不是最佳的。它可以归因于即时(JIT)编译之类的事情,它通过收集使用情况配置文件信息来优化常用代码。最终的负面影响是,与平均时间相比,在预热期间收到的请求将具有非常高的响应时间。在容器化,高吞吐量,频繁部署和自动伸缩的环境中,此问题可能会加剧。
在这篇文章中,我将讨论我们在Kubernetes集群中使用Java服务关于JVM预热问题的经验和方法。
创世记
几年前,我们从单体架构逐步转为微服务架构,并且部署到Kubernetes中。大多数新服务都是用Java开发的。当我们启用Java服务时,我们首先遇到了这个问题。通过负载测试执行了正常的容量规划过程,并确定N个容器足以处理超出预期的峰值流量。
尽管该服务可以毫不费力地处理高峰流量,但我们开始在部署过程中发现问题。我们的每个Pod在高峰时间处理的RPM都超过10k,而我们使用的是Kubernetes滚动更新机制。在部署期间,服务的响应时间会激增几分钟,然后再稳定到通常的稳定状态。在我们的NewRelic仪表板中,我们将看到类似于以下的图形:
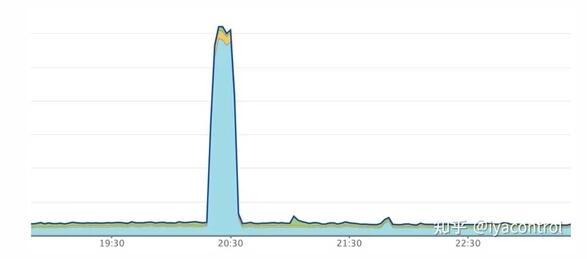
同时,依赖于我们该部署的其他服务在相关时间段内也发生了高响应时间和超时错误。
Take 1: 增加应用数目
我们很快意识到该问题与JVM预热阶段有关,但是由于正在进行其他重要事情,因此没有太多时间进行排查。因此,我们尝试了最简单的解决方案--增加容器的数量,以减少每个容器的吞吐量。我们将Pod的数量增加了几乎三倍,因此每个Pod在高峰时处理的吞吐量约为4k RPM。我们还调整了部署策略,以确保一次最多25%的部署(使用maxSurge和maxUnavailable参数)。这样就解决了问题,尽管我们的运行速度是稳态所需容量的3倍,但我们能够在我们的服务或任何相关服务中毫无问题地进行部署。
在接下来的几个月中,随着我们迁移更多服务,我们也开始在其他服务中频繁注意到该问题。然后,我们决定花一些时间来排查问题并找到更好的解决方案。
Take 2: Warm-Up 脚本
阅读各种文章之后,我们决定尝试一下热身脚本。我们的想法是运行一个预热脚本,该脚本将综合请求发送给该服务几分钟,以期预热JVM,然后才允许实际流量通过。
为了创建预热脚本,我们从生产流量中抓取了实际的URL。然后,我们创建了一个Python脚本,该脚本使用这些URL发送并行请求。我们相应地配置了就绪探针的initialDelaySeconds,以确保预热脚本在Pod准备就绪并开始接受流量之前完成。
令我们惊讶的是,尽管我们看到了一些改进,但这并不重要。我们仍然观察到响应时间和错误。另外,预热脚本引入了新问题。之前,我们的Pod可以在40-50秒内准备就绪,但是使用脚本,它们大约需要3分钟,这在部署过程中成为一个问题,但更重要的是在自动伸缩过程中。我们对热身机制进行了一些调整,例如在热身脚本和实际流量之间进行短暂的重叠,并在脚本本身中进行更改,但并没有看到明显的改进。最后,我们认为热身策略所带来的小收益是不值得的,因此完全放弃了。
Take 3: 探索启发式技术
既然我们的热身脚本想法破灭了,决定尝试一些启发式技术:
- GC (G1, CMS, and Parallel) and various GC parameters
- Heap memory
- CPU allocated
经过几轮实验,我们终于取得了突破。我们正在测试的服务配置了Kubernetes资源限制:
- resources:
- requests:
- cpu: 1000m
- memory: 2000Mi
- limits:
- cpu: 1000m
- memory: 2000Mi
我们增加了CPU请求并将其限制为2000m,并部署了该服务以查看影响。与预热脚本相比,我们在响应时间和错误方面看到了巨大的进步。
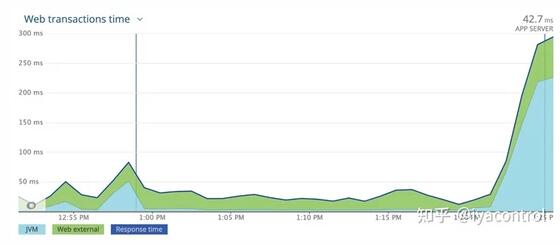
为了进一步测试,我们将配置升级到3000m CPU,令人惊讶的是,问题完全消失了。如下所示,响应时间没有峰值。
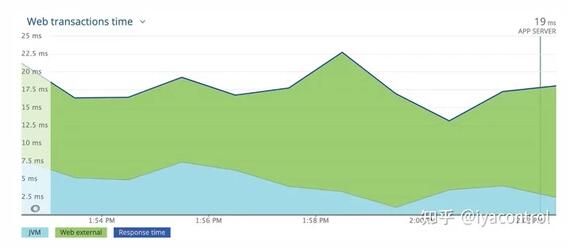
很快就发现问题出在CPU节流。显然,在预热阶段,JVM需要比平均稳态更多的CPU时间,但是Kubernetes资源处理机制(CGroup)正在按照配置的限制来限制CPU。
有一种直接的方法可以验证这一点。 Kubernetes公开了每个容器的度量标准 container_cpu_cfs_throttled_seconds_total ,它表示自此容器启动以来已为它节流了多少秒的CPU。如果我们在1000m配置下遵守此指标,则应该在开始时看到很多节流,然后在几分钟后稳定下来。我们使用此配置进行了部署,这是Prometheus中所有Pod的 container_cpu_cfs_throttled_seconds_total 图表:

正如预期的那样,在容器启动的前5到7分钟内会有很多节流--通常在500秒到1000秒之间,但是随后它稳定下来,证实了我们的假设。
当我们使用3000m CPU配置进行部署时,我们观察到下图:
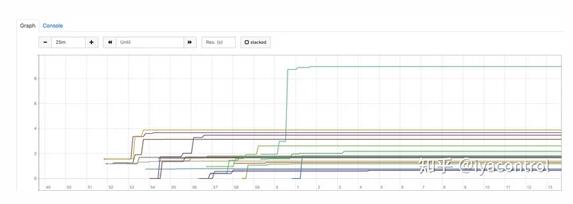
CPU节流几乎可以忽略不计(几乎所有Pod不到4秒),这就是部署顺利进行的原因。
Take 4: 配置 Burstable Qos
尽管我们发现了造成此问题的瓶颈,但从成本方面来看,该解决方案(增加CPU请求/限制三倍)并不可行。此解决方案实际上可能比运行更多的Pod更糟糕,因为Kubernetes根据请求调度Pod,这可能会导致集群自动伸缩器频繁触发,从而向集群添加更多节点。
再次思考这个问题:
在最初的预热阶段(持续几分钟),JVM需要比配置的限制(1000m)更多的CPU(〜3000m)。预热后,即使CPU限制为1000m,JVM也可以充分发挥其潜力。 Kubernetes使用“请求”而不是“限制”来调度Pod。
一旦我们以清晰,平静的心态阅读问题陈述,答案就会出现:Kubernetes Burstable QoS。
Kubernetes根据配置的资源请求和限制将QoS类分配给Pod。
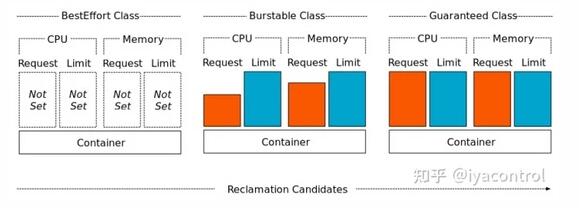
到目前为止,我们一直在通过使用相等值(最初都是1000m,然后都是3000m)指定请求和限制来使用保证的QoS类。尽管QoS保证有其好处,但在整个Pod生命周期的整个周期中,我们不需要3个CPU的全部功能,我们只需要在最初的几分钟内使用它即可。 Burstable QoS类就是这样做的。它允许我们指定小于限制的请求,例如
- resources:
- requests:
- cpu: 1000m
- memory: 2000Mi
- limits:
- cpu: 3000m
- memory: 2000Mi
由于Kubernetes使用请求中指定的值来调度Pod,因此它将找到具有1000m备用CPU容量的节点来调度此Pod。但是,由于此限制在3000m处要高得多,因此,如果应用程序在任何时候都需要超过1000m的CPU,并且该节点上有可用的CPU备用容量,则不会在CPU上限制应用程序。如果可用,它可以使用长达3000m。
最后,是时候检验假设了。我们更改了资源配置并部署了应用程序。而且有效!我们再进行了几次部署,以测试我们是否可以重复结果,并且该结果始终如一。此外,我们监控了 container_cpu_cfs_throttled_seconds_total 指标,这是其中一种部署的图表:
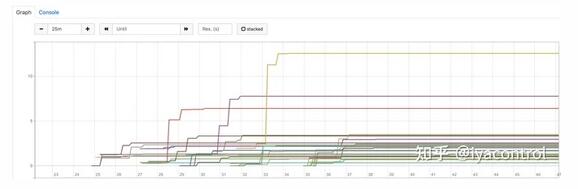
如我们所见,此图与3000m CPU的“保证的QoS”设置非常相似。节流几乎可以忽略不计,它证实了具有Burstable QoS的解决方案有效。
结论
Kubernetes资源限制是一个重要的概念,我们在所有基于Java的服务中实施了该解决方案,并且部署和自动扩展都可以正常工作,没有任何问题。
以下三个关键点需要大家注意:
- container_cpu_cfs_throttled_seconds_total