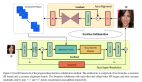
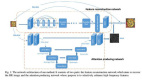
分享一篇 CVPR 2020 录用论文:PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models,作者提出了一种新的图像超分辨率方法,区别于有监督的PSNR-based和GANs-based方法,该方法是一种无监督的方法,即只需要低分辨率的图片就可以恢复高质量、高分辨率的图片。
目前代码已经开源:
https://github.com/adamian98/pulse
论文信息:

1. Motivation
图像超分辨率任务的基本目标就是把一张低分辨率的图像超分成其对应的高分辨率图像。无论是基于PNSR还是GAN的监督学习方法,或多或少都会用到pixel-wise误差损失函数,而这往往会导致生成的图像比较平滑,一些细节效果不是很好。于是作者换了一个思路:**以往的方法都是从LR,逐渐恢复和生成HR;如果能找到一个高分辨率图像HR的Manifold,并从该Manifold中搜寻到一张高分辨率的图像使其下采样能恢复到LR,那么搜寻到的那张图像就是LR超分辨率后的结果。**所以本篇文章主要解决了以下的两个问题:
如何找到一个高分辨率图像的Manifold?
如何在高分辨率图像的Manifold上搜寻到一张图片使其下采样能恢复LR?
2. Method
假设高分辨率图像的Manifold是,是M上的一个高分辨率图片,给定一个低分辨率图像,如果可以通过下采样操作DS恢复LR,那么就可以认为是LR的超分辨率结果,该问题定义如下:
即当两者的差值小于某个阈值时。令,那么本文任务其实就是找到一个如下图所示:
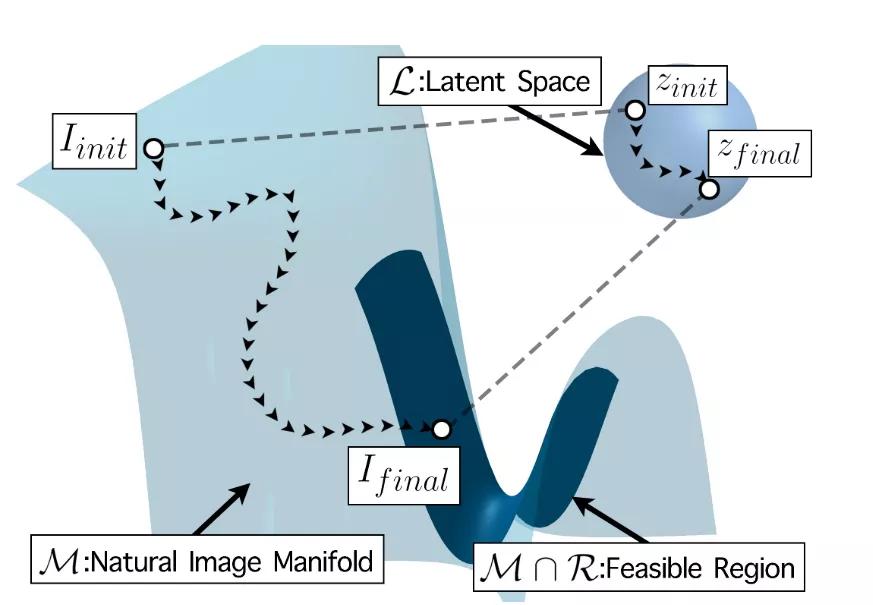

以上就是本篇文章的核心内容,下面我们结合代码来看一下具体是怎么实现的。
首先我们需要一个生成模型来近似高分辨率的Manifold,在本文中,作者采用的是StyleGAN的预训练模型:
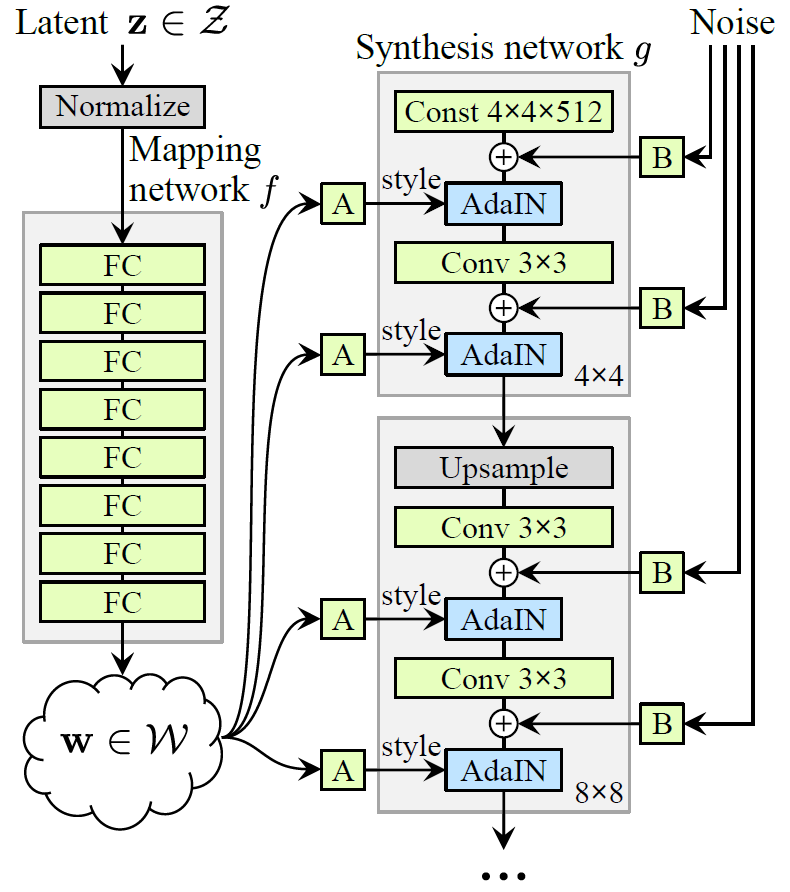
StyleGAN的生成器网络中有两个部分,一个是Mapping Network用于将latent code映射为style code,一个Synthesis Network用于将映射后得到的style code用于指导图像的生成。这里需要注意的是,本篇文章只是使用了StyleGAN的预训练模型,并不训练更新其参数。加载两个部分的参数之后,随机构造100000个随机latent code,经过Mapping Network,用得到新的latent code计算均值与方差:
- latent = torch.randn((1000000,512),dtype=torch.float32, device="cuda")
- latent_out = torch.nn.LeakyReLU(5)(mapping(latent))
- self.gaussian_fit = {"mean": latent_out.mean(0), "std": latent_out.std(0)}
这个均值与方差就可以用来映射新的latent code。接下就是随机初始化latent code和noise(StyleGAN需要):
- # 初始化latent code
- latent = torch.randn((batch_size, 18, 512), dtype=torch.float, requires_grad=True, device='cuda')
- # 初始化noise
- for i in range(18): # [?, 1, 4, 4] -> [?, 1, 1024, 1024]
- res = (batch_size, 1, 2**(i//2+2), 2**(i//2+2))
- new_noise = torch.randn(res, dtype=torch.float, device='cuda')
- if (i < num_trainable_noise_layers): # num_trainable_noise_layers
- new_noise.requires_grad = True
- noise_vars.append(new_noise)
- noise.append(new_noise)
**从这里我们可以看出,模型优化的其实是latent code与noise的前5层,而不是模型参数。**初始化完成了之后就可以执行前向了:
- # 根据之前的求得的均值和方差,映射latent code
- latent_in = self.lrelu(latent_in*self.gaussian_fit["std"] + self.gaussian_fit["mean"])
- # 加载Synthesis Network用于生产图像
- # 把图像结果从[-1, 1]修改到[0, 1]
- gen_im = (self.synthesis(latent_in, noise)+1)/2
根据原始的低分辨率图像和生成的高分辨率图像计算loss。在代码中,loss由两个部分组成:
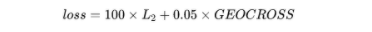
其中L2损失是将生成的高分辨率图像gen_im通过bicubic下采样恢复LR,并与输入的LR计算pixel-wise误差,GEOCROSS是测地线距离。
最后优化器选择的是球面优化器:
- # opt = SphericalOptimizer(torch.optim.Adam, [x], lr=0.01)
- class SphericalOptimizer(Optimizer):
- def __init__(self, optimizer, params, **kwargs):
- self.opt = optimizer(params, **kwargs)
- self.params = params
- with torch.no_grad():
- self.radii = {param: (param.pow(2).sum(tuple(range(2,param.ndim)),keepdim=True)+1e-9).sqrt() for param in params}
- @torch.no_grad()
- def step(self, closure=None):
- loss = self.opt.step(closure)
- for param in self.params:
- param.data.div_((param.pow(2).sum(tuple(range(2,param.ndim)),keepdim=True)+1e-9).sqrt())
- param.mul_(self.radii[param])
- return loss
3. Result

从结果可以看出,PULSE生成的图像细节更丰富,包括头发丝、眼睛和牙齿这些比较细微的地方都能生成的很好。而且对于有噪声的LR,也能生成的很好,说明该算法有很强的鲁棒性:

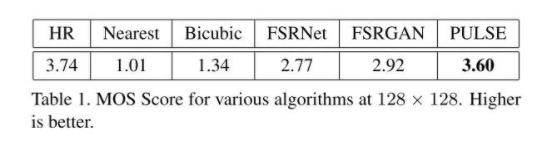
最终的比较指标采用的是MOS:
4. Questions
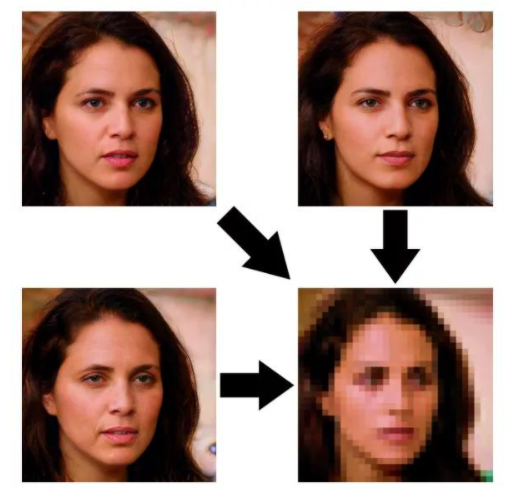
PULSE是一个无监督的图像超分辨率模型,其图像的质量其实很大程度上取决于所选取的生成模型的好坏。另一方面,由于PULSE的基础原理就是找到一个高分辨率的图像,使其下采样之后能恢复LR,那么意味着结果不唯一,可能生成的图像很清楚,但是已经失去了身份信息:
5. Resource
PaperPULSE:https://arxiv.org/pdf/2003.03808.pdfStyleGAN: https://arxiv.org/abs/1812.04948Random Vectors in High Dimen- sions: https://www.sci-hub.ren/10.1017/9781108231596.006
Github: https://github.com/adamian98/pulse.git