在移动互联网技术加持下,音频社交不仅可以满足多场景下的社交需求,体验也迎来了革新,尤其是AI+5G技术,对音频社交的驱动将更为明显。很多社交产品会基于音频技术增加变声、美声、立体声、混响和场景化音效等,来丰富用户的听感体验。本篇拍乐云Pano的技术分享就来讲讲音频社交场景中的变声是应用了哪些算法来实现的。
01 变声是如何实现的?
当我们日常观看视频时,有时会使用倍速播放。在加快播放速度时,我们会感觉视频中的男声听起来有点像“女声”;在放慢播放速度时,我们能听到类似于《疯狂动物城》中那个说话慢吞吞的“树懒声”。这些其实就是简单的变声。
从技术的角度并不难理解,如果我们用16k的采样率去采集一个100Hz的正弦波,而用32k或者8k的采样率去播放的话,那么这个正弦波的频率就会提升一倍(200Hz)或者降低一倍(50Hz)。这样将音频的频率升高或者降低的方法很简单,提升一倍就是每隔一个丢弃一个样本,放慢一倍就是进行一个线性插值。用专业的术语来说,这是一个重采样的过程。按照重采样方法是可以实现一个变调的,但同时也很容易发现,音频的时间变长或者变短了,和我们原始输入的音频长度不一致了,这在实时通信中是不能接受的。在实时通信中,我们要的是一个变调不变速的变声功能,单一的重采样方法是做不到的。当然除了重采样,我们还有其他的一些变声方法能够实现变调不变速的需求。
02 变声有哪些常见的算法?
常见的变调算法有时域、频域和参量法。时域较易实现,多采用变速不变调+重采样实现变调不变速等。频域以及参量法就相对复杂,并且计算量相比于时域大了很多。本次主要简单介绍一些常见的时域和频域算法。
在时域内主要是OLA(Overlap-Add)类算法:OLA,同步波形叠加法(Synchronized Overlap-Add, SOLA)、固定同步波形叠加法(Synchronized Overlap-Add and Fixed Synthesis, SOLAFS)、时域基音同步叠加法(Time-Domain Pitch Synchronized Overlap-Add, TD-PSOLA) 波形相似叠加法(waveform similarity overlap-and-add, WSOLA)等,频域内主要是基音同步波形叠加算法(Pitch-Synchronized OLA, PSOLA)等。
1)OLA
OLA是最简单粗暴的一种TSM方式。对原始语音进行分帧后,间隔一段采样点,重复或者丢弃其中某些语音帧来重新建立语音。这样就实现简单的变音效果。原理如下图所示:
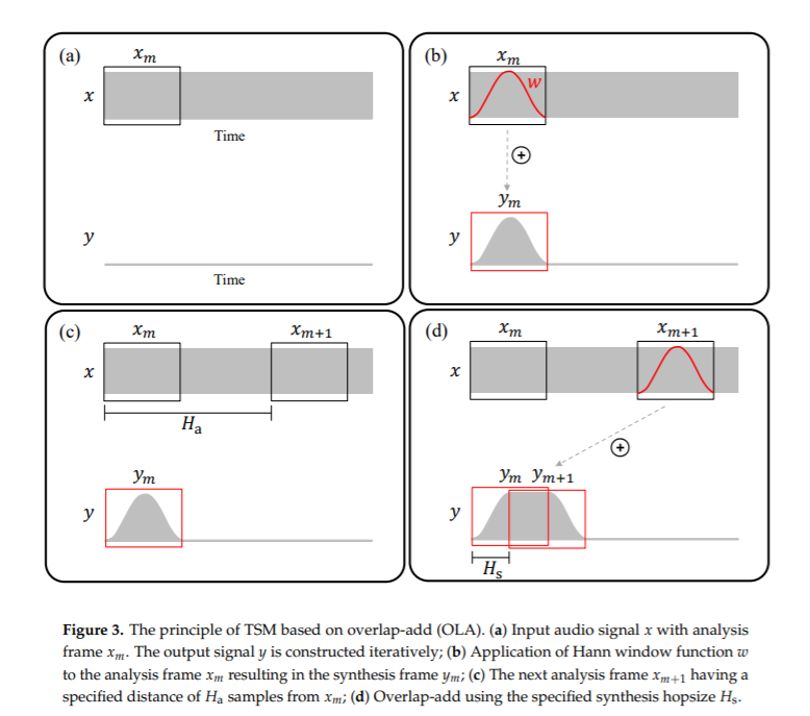
a.分帧,对时域音频进行分帧处理;
b.在输入信号X上加上一个汉宁窗;
c.在第一帧后间隔固定点数Ha取出第二帧;
d.把第二帧语音加窗后与第一帧overlap-add。
如此操作到语音结束就能重建一个新的变调语音。但是这算法存在一定的局限性,无法保证语音是连续的,可能会出现基音断裂的情况。这样的语音听起来会有咔吧声,造成了语音的失真。
2)波形相似叠加法(waveform similarity overlap-and-add, WSOLA)
了解了简单粗暴的OLA算法后,我们可以清晰的知道OLA算法的局限和缺陷。当然也知道造成这种缺陷的原因是什么:相位不连续导致的。为了减小基音断裂和相位不连续问题,Verhelst和Roelands提出了波形相似叠加法(WSOLA)。目前开源代码soundtouch使用的就是该算法。其原理如下图:
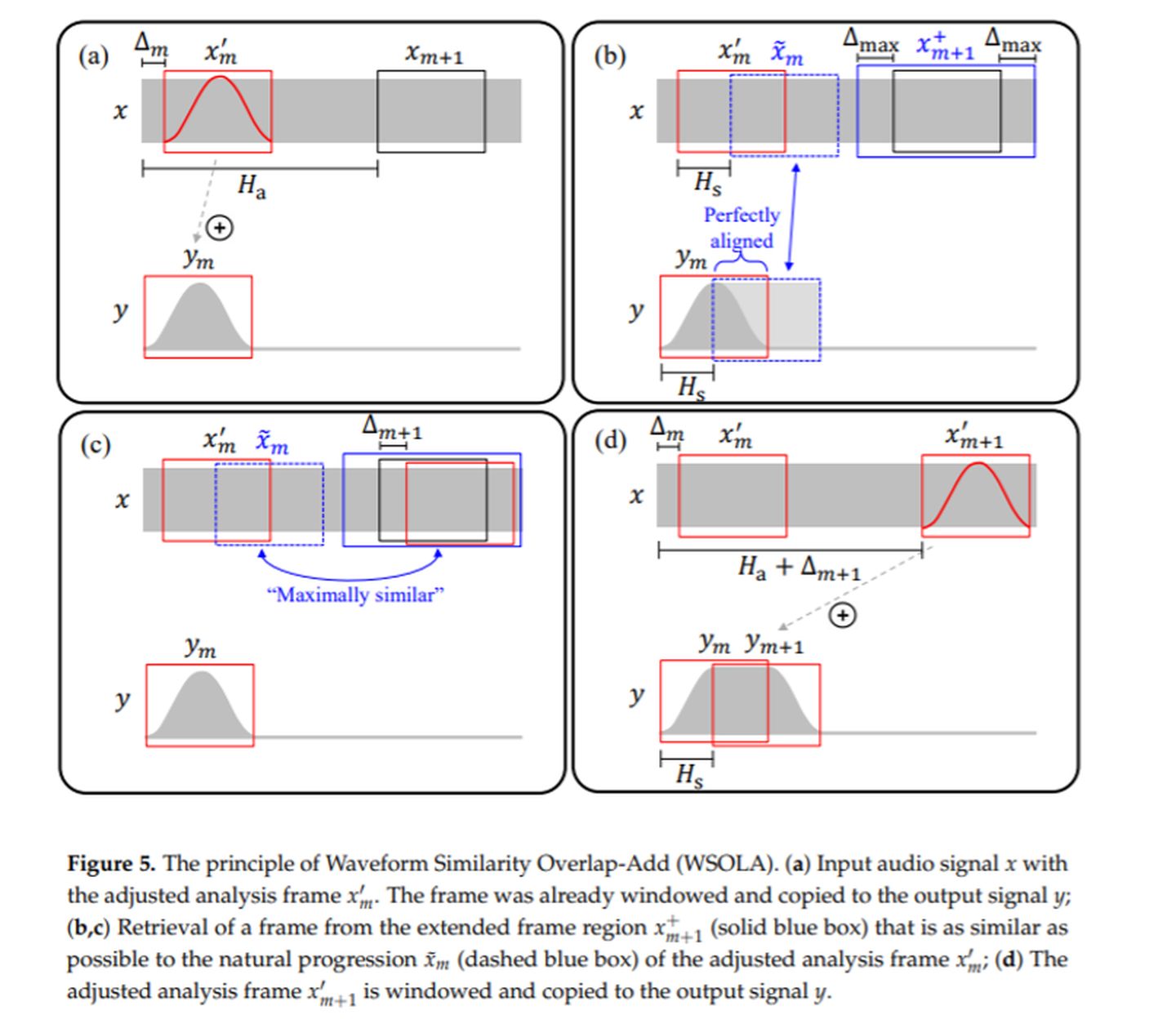
a.在原始音频中取出第一帧,让后对该帧进行加窗,输出到y信号上;
b+c. 在虚线蓝色范围内找到第二帧,第二帧相位参数应该和第一个帧相位对齐,在蓝色范围内寻找与第二帧最相似的帧作为输出帧,作为y信号的第二帧;
d. 最为相似的帧与第一帧overlap-add到y信号上
重点在b.c两步操作中,如何寻找最相似的帧。很多论文中给出了一种最直接的方法,计算“自相关”。虽然WSOLA能够解决基音断裂和相位不连续问题,但是它会影响音色,将WSOLA应用于打击乐乐器的音频时,这种现象将会更加的明显。
3)基音同步波形叠加算法(Pitch-Synchronized OLA, PSOLA)
PSOLA的算法原理与WSOLA有所不同,PSOLA在频域处理的,它能进一步达到基音同步的目的。在该算法中,变速和变调是两个独立的过程,由不同的参数控制。先对基音进行检测,标记基音周期。通过标记的基音周期将语音划分为多个合成单元。通过重复或者丢失合成单元来实现语速的控制。通过改变相邻合成单元的重叠长度或者重采样结合变速来改变语音的基频。
PSOLA是对基频进行修改的,因此很好的保护了共振峰,不会对音色有太大的影响。不过该算法在频域中进行处理的,计算量大,很难满足实时的变速与变调处理。
03 结束语
以上是拍乐云Pano简单介绍的三种常见的变声算法,这三种算法可以粗略实现大叔音、萝莉音以及怪兽声等。但是想要做到变声后的声音听起来更加真实自然,就需要进一步的优化调试了。除了这些算法外,还有其他的变声音效,比如常见的“惊悚声”,运用了vibrato或者tremolo算法,还有“山谷空灵音”运用了echo算法等等,这些算法都是基于传统的信号处理实现的。在传统的信号处理变声方法外,还有更高级的变声算法:AI变声。AI变声相比于传统的信号处理方法,会让变声后的声音更加真实自然。
注:文中图片来源于《A Review of Time-Scale Modification of Music Signals》论文