













最近,来自阿里、华中科大、牛津等机构的研究者公开了一个针对强遮挡场景的大型视频实例分割数据集 OVIS。实验表明,该数据集非常适合用来衡量算法对于遮挡场景的处理能力。
对于被遮挡的物体,人类能够根据时序上下文来识别,定位和追踪被遮挡的物体,甚至能脑补出物体被遮住的部分,那么现有的深度学习方法对遮挡场景的处理能力如何呢?
为了探究这个问题,来自阿里、华中科大、牛津等多个机构的研究者构建了一个针对强遮挡场景的大型视频实例分割数据集 Occluded Video Instance Segmentation (OVIS)。
论文地址:https://arxiv.org/abs/2102.01558
项目主页:http://songbai.site/ovis/
视频实例分割 (Video Instance Segmentation, VIS) 要求算法能检测、分割、跟踪视频里的所有物体。与现有 VIS 数据集相比,OVIS最主要的特点就是视频里存在大量的多种多样的遮挡。因此,OVIS 很适合用来衡量算法对于遮挡场景的处理能力。
实验表明,现有方法并不能在强遮挡场景下取得令人满意的结果,相比于广泛使用的 YouTube-VIS 数据集,几乎所有算法在 OVIS 上的指标都下降了一半以上。
OVIS 数据集简介
研究者一共采集了近万段视频,并最终从中挑选出了 901 段遮挡严重、运动较多、场景复杂的片段,每段视频都至少有两个相互遮挡的目标对象。其中大部分视频分辨率为 1920x1080,时长在 5s 到 60s 之间。他们按每 5 帧标注一帧的密度进行了高质量标注,最终得到了 OVIS 数据集。
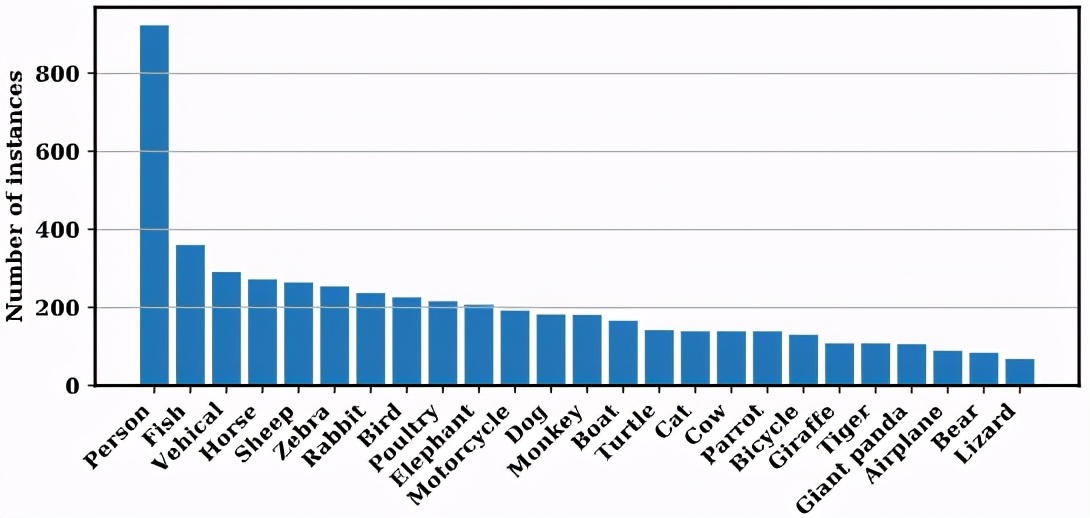
OVIS 共包含 25 种生活中常见的类别,如下图所示,其中包括人、交通工具以及动物。这些类别的目标往往处于运动状态,因而也更容易发生严重的遮挡。此外,OVIS 的 25 个类别都可以在大型的图片级实例分割数据集(MS COCO、LVIS、Pascal VOC 等)中找到,以方便研究人员进行模型的迁移和数据的复用。
OVIS 数据集特性
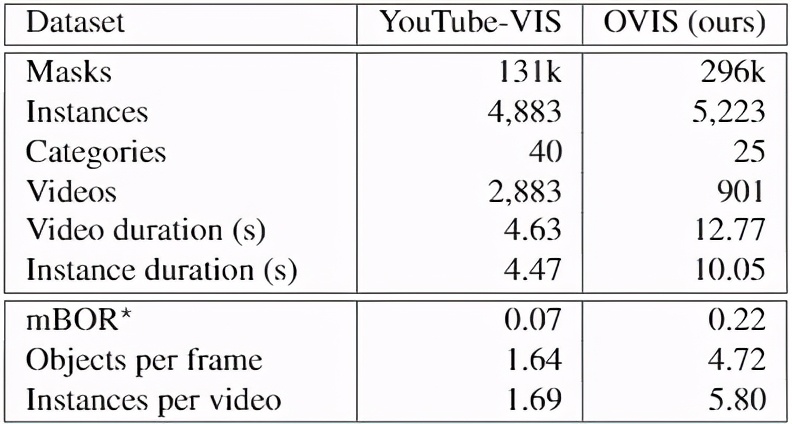
OVIS 包含 5223 个目标对象的 296k 个高质量 mask 标注。相比先前的 Youtube-VIS 数据集,OVIS 拥有更多的 mask 和更多的目标对象。研究者牺牲了一定的视频段数来标注更长更复杂的视频,以让它更具挑战性。
与先前其他 VIS 数据集相比,OVIS 最大的特点在于严重的遮挡。为了量化遮挡的严重程度,研究者提出了一个指标mean Bounding-box Overlap Rate (mBOR)来粗略地反映遮挡程度。mBOR 指图像中边界框重叠部分的面积占所有边界框面积的比例。从下表中可以看出,相比于 YouTube-VIS,OVIS 有着更严重的遮挡。
值得注意的是,除去上面提到的基础数据统计量,OVIS 在视频时长、物体可见时长、每帧物体数、每段视频物体数等统计量上都显著高于 YouTube-VIS,这与实际场景更为相近,同时也进一步提高了 OVIS 的难度。
可视化
OVIS 数据集中包含多种不同的遮挡类型,按遮挡程度可分为部分遮挡和完全遮挡;按被遮挡场景可分为被其他目标对象遮挡、被背景遮挡以及被图片边界遮挡。不同类型的遮挡可能同时存在,物体之间的遮挡关系也比较复杂。
如下图视频片段中,两只熊既互相部分遮挡,有时也会被树(背景)遮挡。

又如下图视频片段中,绿车和蓝车分别逐渐被白车和紫车完全遮挡,后来又逐渐出现在视野中。

从下图可视化片段中也可以看出 OVIS 的标注质量很高,研究者对笼子网格、动物毛发都做了精细的标注。

更多可视化片段参见项目主页。
实验
研究者在 OVIS 上尝试了 5 种开源的现有算法,结果如下表所示。可以看到 OVIS 非常具有挑战性。使用同样的评价指标,MaskTrack R-CNN 在 Youtube-VIS 验证集上 mAP 能达到 30.3,在 OVIS 验证集上只有 10.9;SipMask 的 mAP 也从 Youtube-VIS 上的 32.5 下降到了 OVIS 上的 10.3。5 个现有算法中,STEm-Seg 在 OVIS 上效果最好,但也只得到了 13.8 的 mAP。

总结
研究者针对遮挡场景下的视频实例分割任务构建了一个大型数据集 OVIS。作为继 YouTube-VIS 之后的第二个视频实例分割 benchmark,OVIS 主要被设计用于衡量模型处理遮挡场景的能力。实验表明 OVIS 数据集给现有算法带来了巨大的挑战。未来还将把 OVIS 推广至视频物体分割 (VOS) 以及视频全景分割 (VPS) 等场景,期待 OVIS 能够启发更多研究人员进行复杂场景下视频理解的研究。
更多细节请见论文。






















