













本文转载自微信公众号「大数据DT」,作者刘宇 赵宏宇 等。转载本文请联系大数据DT公众号。
01 什么是知识图谱
我们可以从不同的视角去审视知识图谱的概念。
- 在Web视角下,知识图谱如同简单文本之间的超链接一样,通过建立数据之间的语义链接,支持语义搜索。
- 在自然语言处理视角下,知识图谱就是从文本中抽取语义和结构化的数据。
- 在知识表示视角下,知识图谱是采用计算机符号表示和处理知识的方法。
- 在人工智能视角下,知识图谱是利用知识库来辅助理解人类语言的工具。
- 在数据库视角下,知识图谱是利用图的方式去存储知识的方法。
目前,学术界还没有给知识图谱一个统一的定义。在谷歌发布的文档中有明确的描述,知识图谱是一种用图模型来描述知识和建模世界万物之间关联关系的技术方法。
知识图谱还是比较通用的语义知识的形式化描述框架,它用节点表示语义符号,用边表示语义之间的关系,如图3-1所示。在知识图谱中,人、事、物通常被称作实体或本体。
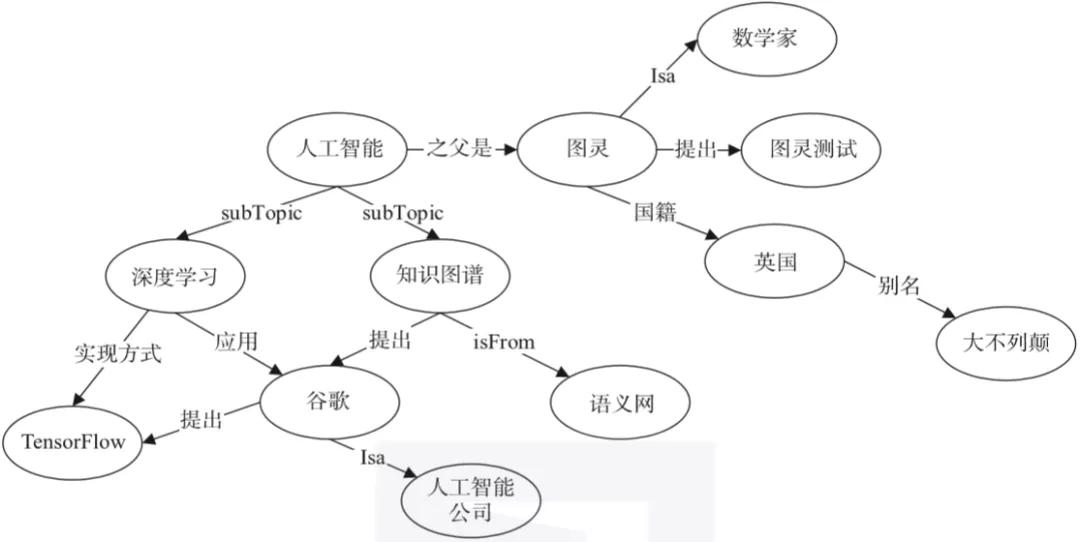
▲图3-1 知识图谱示例
知识图谱的组成三要素包括:实体、关系和属性。
- 实体:又叫作本体(Ontology),指客观存在并可相互区别的事物,可以是具体的人、事、物,也可以是抽象的概念或联系。实体是知识图谱中最基本的元素。
- 关系:在知识图谱中,边表示知识图谱中的关系,用来表示不同实体间的某种联系。如图3-1所示,图灵和人工智能之间的关系,知识图谱和谷歌之间的关系,谷歌和深度学习之间的关系。
- 属性:知识图谱中的实体和关系都可以有各自的属性,如图3-2所示。
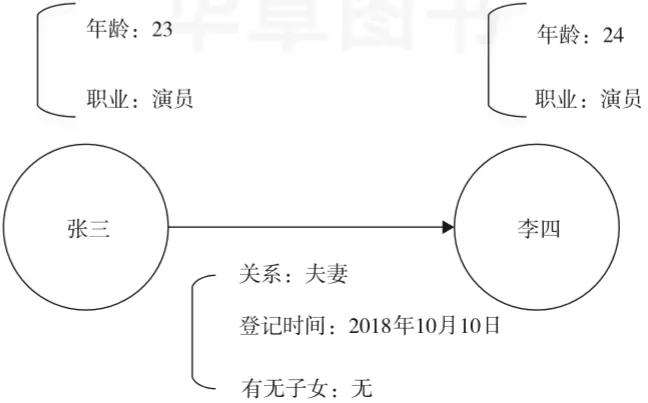
▲图3-2 知识图谱中的属性
知识图谱的构建涉及知识建模、关系抽取、图存储、关系推理、实体融合等多方面技术。知识图谱的应用则体现在语义搜索、智能问答、语言理解、决策分析等多个领域。
02 知识图谱的价值
知识图谱最早应用于搜索引擎,一方面通过推理实现概念检索,另一方面以图形化方式向用户展示经过分类整理的结构化知识,从而使人们从人工过滤网页寻找答案的模式中解脱出来,可应用到智能问答、自然语言理解、推荐等方面。
知识图谱的发展得益于Web技术的发展,受KR、NLP、Web以及AI等方面的影响。知识图谱的价值归根结底是为了让AI变得更智慧。
1. 助力搜索
搜索的目的是在万物互联的网络中,能够使人们方便、快速地找到某一事物。目前,我们的搜索习惯和搜索行为仍然是以关键词为搜索目的,知识图谱的出现可以彻底改变这种搜索行为模式。
在知识图谱还没有应用到搜索引擎上时,搜索的流程是:从海量的URL中找出与查询匹配度最高的URL,按照查询结果把排序分值最高的一些结果返回给用户。在整个过程中,搜索引擎可能并不需要知道用户输入的是什么,因为系统不具备推理能力,在精准搜索方面也略显不足。
而基于知识图谱的搜索,除了能够直接回答用户的问题外,还具有一定的语义推理能力,大大提高了搜索的精确度。图3-3所示是知识图谱助力搜索示意图。

▲图3-3 知识图谱助力搜索
2. 助力推荐
推荐技术和搜索技术非常相似,但是稍有区别。搜索技术采用信息拉取的方式,而推荐技术采用信息推送的方式,所以在推荐技术中有一些问题,比如冷启动和数据稀疏问题。
以电商推荐为例介绍知识图谱在推荐上的应用。假设我买了手机,手机的强下位关系是手机壳,这样系统就可以给我推荐手机壳,同时也可以推荐相似或互补的实体。图3-4为知识图谱助力推荐示意图。
▲图3-4 知识图谱助力推荐
3. 助力问答
问答与对话系统一直是NLP在人工智能实现领域的关键标志之一。知识图谱相当于是给问答与对话系统挂载了一个背景知识库。
对于问答与对话系统或者聊天机器人来说,其除了需要实体知识图谱和兴趣知识图谱等开放领域的稀疏大图外,还需要针对机器人和用户个性化的稠密小图。同时,知识图谱是需要动态更新的。图3-5是知识图谱助力问答示意图。
▲图3-5 知识图谱助力问答
03 知识图谱的架构
知识图谱的架构涉及知识表示、知识获取、知识处理和知识利用等多个方面。
一般情况下,知识图谱构建流程如下:首先确定知识表示模型,然后根据不同的数据来源选择不同的知识获取手段并导入相关的知识,接着利用知识推理、知识融合、知识挖掘等技术构建相应的知识图谱,最后根据不同应用场景设计知识图谱的表现方式,比如:语义搜索、智能推荐、智能问答等。
从逻辑上,我们可以将知识图谱划分为两个层次:数据层和模式层。数据层可以是以事实为单位存储的数据库,可以选用的图数据库有RDF4j、Virtuoso、Neo4j等三元组。
<实体,关系,实体>或者<实体,属性,属性值>可以作为基本的表达方式,存储在图数据库中。模式层建立在数据层之上,是知识图谱的核心。通常,通过本体库来管理数据层,本体库的概念相当于对象中“类”的概念。借助本体库,我们可以管理公理、规则和约束条件,规范实体、关系、属性这些具体对象间的关系。
知识图谱有自顶向下和自底向上两种构建方式。自顶向下构建是指借助百科类数据源,提取本体和模式信息,并加入知识库中。自底向上构建是指借助一定的技术手段,从公开的数据中提取资源,选择其中置信度较高的信息,经人工审核后,加入知识库中。
在知识图谱发展初期,多数企业和机构采用自顶向下的方式构建知识图谱,目前大多企业采用自底向上的方式构建知识图谱。
知识图谱的架构如图3-6所示。

▲图3-6 知识图谱的架构
- 知识源:包括结构化数据、非结构化数据和半结构化数据。
- 信息抽取:就是从各种类型的数据源中提取实体、属性以及实体间的相互关系,在此基础上形成本体的知识表述。知识图谱的构建过程中存在大量的非结构化或者是半结构化数据,这些数据在知识图谱的构建过程中需要通过自然语言处理的方法进行信息抽取。从这些数据中,我们可以提取出实体、关系和属性。
- 知识融合:主要工作是把结构化的数据以及信息抽取提炼到的实体信息,甚至第三方知识库进行实体对齐和实体消歧。这一阶段的输出应该是从各个数据源融合的各种本体信息。
- 知识加工:知识加工阶段如图3-6所示,其中知识推理中重要的工作就是知识图谱的补全。常用的知识图谱的补全方法包括:基于本体推理的补全方法、相关的推理机制实现以及基于图结构和关系路径特征的补全方法。
关于作者:刘宇,清华大学硕士,现就职于一家跨境电商公司,任技术总监,主要负责该公司搜索推荐业务以及广告的相关技术开发。目前工作的重点是落地算法在搜索系统、推荐系统、对话系统等具体业务场景下的应用。对机器学习、深度学习、大数据应用与开发等颇有研究。合著有《聊天机器人:入门、进阶与实战》一书。
赵宏宇,本科毕业于东北大学;研究生毕业于RIT,主修AI方向。现就职于猎聘网,主要负责猎聘网推荐排序相关的工作。
刘书斌,本科毕业于东北大学,现就职于美团,资深系统开发工程师。曾在唯品会任职,主要负责搜索工程的架构设计与实现等相关工作,在Elasticsearch方面有丰富的工程实践经验。
孙明珠,硕士毕业于南京航空航天大学,现就职于猎聘网,担任高级算法工程师,负责查询理解、解析、扩展等NLP相关的工作。
本文摘编自《智能搜索和推荐系统:原理、算法与应用》,经出版方授权发布。





















