本篇文章则介绍如何使用Python进行数据驱动。这里以pytest测试框架为例,重点讲解pytest参数化相关知识。(关于pytest的环境配置以及基础使用不在本文的讨论范围)
pytest中使用标签@pytest.mark.parametrize 实现参数化功能,在执行用例的时候该标签迭代中的每组数据都会作为一个用例执行。
一组参数化数据
定义参数化数据,代码如下:
- class TestDemo1:
- @pytest.mark.parametrize('actual_string, expect_string', [(1, 1), ('BB', 'BB'),('AA', 'BB')])
- def test_1(self, actual_string, expect_string):
- assert (expect_string == actual_string)
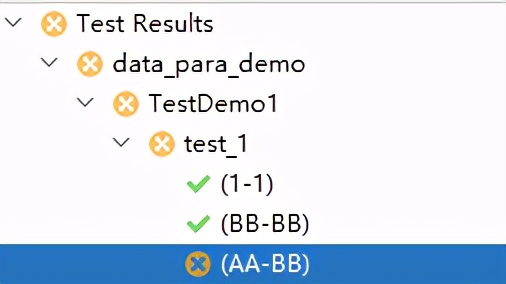
运行结果如下,三组数据在三条测试用例中运行,其中数据('AA', 'BB')运行失败!
多组参数化数据
在一个测试类中,可以定义多组参数化数据(参数化数据个数不同,test_1二个,test_2三个),代码如下:
- class TestDemo1:
- @pytest.mark.parametrize('actual_string, expect_string', [(1, 1), ('BB', 'BB'),('AA', 'BB')])
- def test_1(self, actual_string, expect_string):
- assert (expect_string == actual_string)
- @pytest.mark.parametrize('result, a,b', [(1, 1,0),(2, 1,0) ])
- def test_2(self, result, a,b):
- assert (result == a+b)
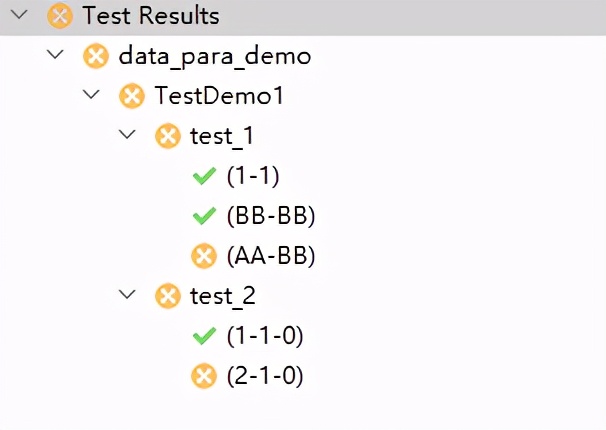
运行结果如下,二组数据分别在test_1和test_2中运行!
从excel中读取数据作为参数
我们可以自定义一些方法,对外部文件进行读取,然后把读取的数据作为参数在pytest
中引用。把测试数据保存在excel中,如下图
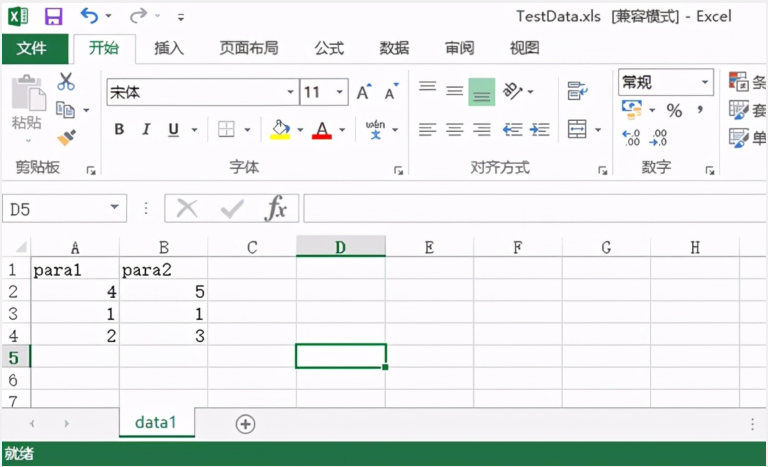
写一个读取excel类文件的方法,使用模块pandas ,使用命令pip install pandas 安装模块,源码如下:
- import pandas as pd
- # 读取Excel文件 -- Pandas
- def read_data_from_pandas(excel_file, sheet_name):
- if not os.path.exists(excel_file):
- raise ValueError("File not exists")
- s = pd.ExcelFile(excel_file)
- df = s.parse(sheet_name)#解析sheet页的数据
- return df.values.tolist()#数据返回为list
从excel中读取数据,并赋值给变量进行参数化,代码如下:
- @pytest.mark.parametrize('actual_string, expect_string', read_data_from_pandas('E:/TestData.xls', 'data1'))
- def test_3(self, actual_string, expect_string):
- assert (expect_string == actual_string)
运行结果如下,三组数据在三条测试用例中运行!
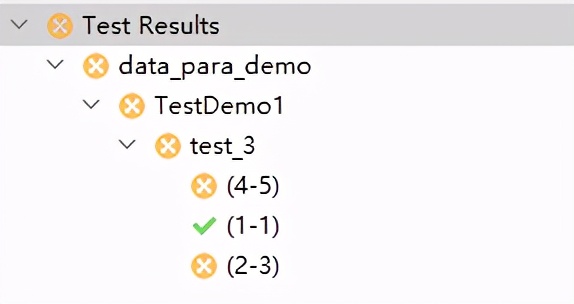
注意:excel中的首行,默认不会作为测试数据处理。