













我们知道,在传递给机器学习模型的数据中,我们需要对数据进行归一化(normalization)处理。
在数据归一化之后,数据被「拍扁」到统一的区间内,输出范围被缩小至 0 到 1 之间。人们通常认为经过如此的操作,最优解的寻找过程明显会变得平缓,模型更容易正确的收敛到最佳水平。
然而这样的「刻板印象」最近受到了挑战,DeepMind 的研究人员提出了一种不需要归一化的深度学习模型 NFNet,其在大型图像分类任务上却又实现了业内最佳水平(SOTA)。
 前所未有的水平">
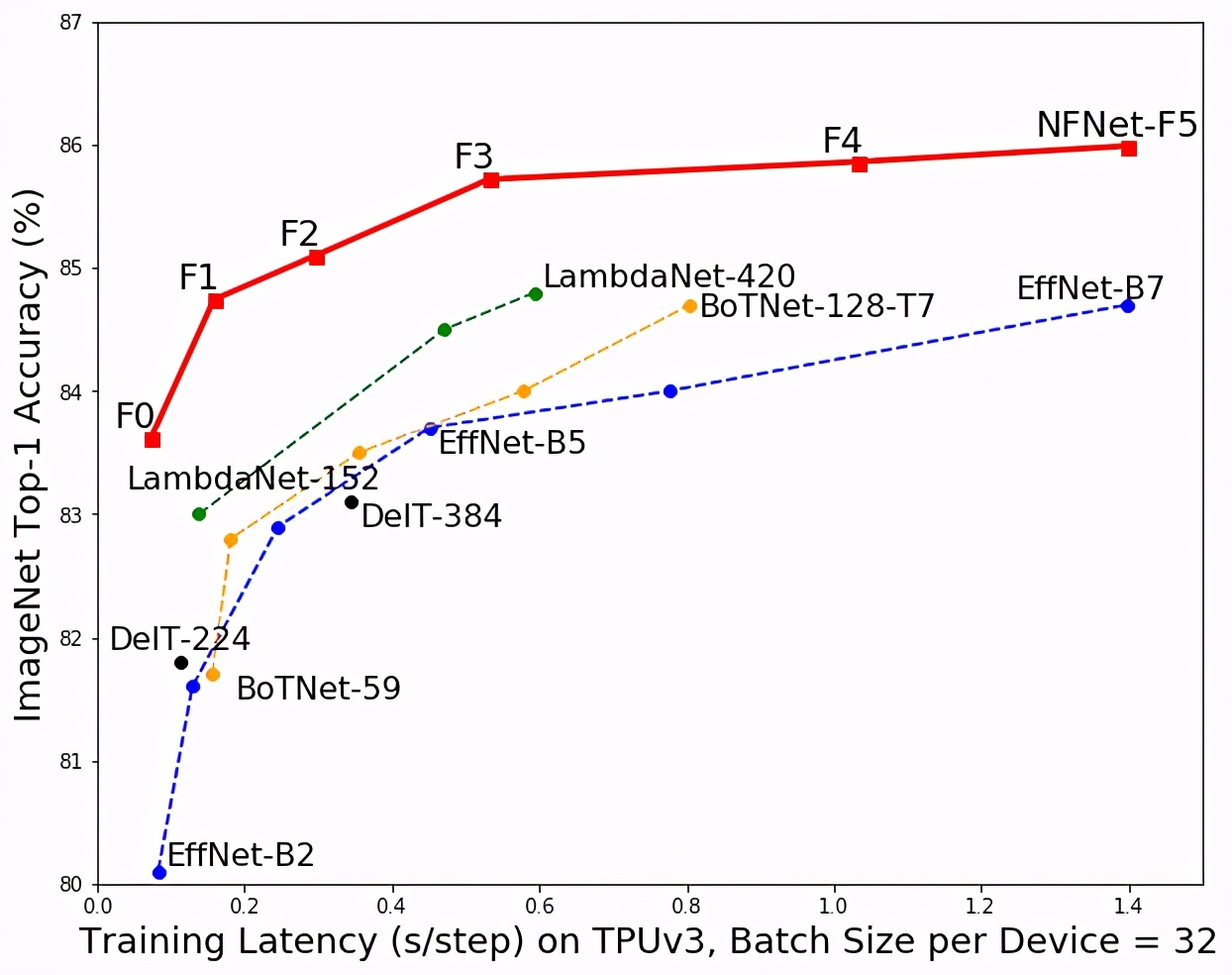
前所未有的水平">该模型(红色)与其他模型在 ImageNet 分类准确度和训练时间上的对比。
该论文的第一作者,DeepMind 研究科学家 Andrew Brock 表示:「我们专注于开发可快速训练的高性能体系架构,已经展示了一种简单的技术(自适应梯度裁剪,AGC),让我们可以训练大批量和大规模数据增强后的训练,同时达到 SOTA 水平。」
该研究一经提交,便吸引了人们的目光。
 前所未有的水平">
前所未有的水平">- 论文链接:https://arxiv.org/abs/2102.06171
- DeepMind 还放出了模型的实现:https://github.com/deepmind/deepmind-research/tree/master/nfnets
NFNet 是不做归一化的 ResNet 网络。具体而言,该研究贡献有以下几点:
- 提出了自适应梯度修剪(Adaptive Gradient Clipping,AGC)方法,基于梯度范数与参数范数的单位比例来剪切梯度,研究人员证明了 AGC 可以训练更大批次和大规模数据增强的非归一化网络。
- 设计出了被称为 Normalizer-Free ResNets 的新网络,该方法在 ImageNet 验证集上大范围训练等待时间上都获得了最高水平。NFNet-F1 模型达到了与 EfficientNet-B7 相似的准确率,同时训练速度提高了 8.7 倍,而 NFNet 模型的最大版本则树立了全新的 SOTA 水平,无需额外数据即达到了 86.5%的 top-1 准确率。
- 如果在对 3 亿张带有标签的大型私人数据集进行预训练,随后针对 ImageNet 进行微调,NFNet 可以比批归一化的模型获得更高的 Top-1 准确率:高达 89.2%。
研究方法
在没有归一化的情况下,许多研究者试图通过恢复批归一化的好处来训练深度 ResNet 以提升其准确率。这些研究大多数通过引入小常数或可学习的标量来抑制初始化时残差分支上的激活尺度。
DeepMind 的这项研究采用并建立在「Normalizer-Free ResNet(NF-ResNet)」上,这是一类可以在没有归一化层的情况下,被训练成具有训练和测试准确率的预激活 ResNet。
NF-ResNet 使用如下形式的残差块:
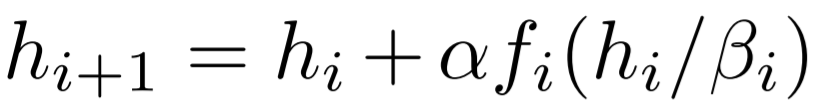 前所未有的水平">
前所未有的水平">其中,h_i 代表第 i 个残差块的输入,f_i 代表由第 i 个残差分支计算的函数。
用于高效大批量训练的自适应梯度裁剪
为了将 NF-ResNet 扩展到更大的批规模,研究者探索了一系列梯度裁剪策略。梯度裁剪通常被用于语言建模中以稳定训练。近来一些研究表明:与梯度下降相比,梯度裁剪允许以更高的学习率进行训练,从而加快收敛速度。这对于条件较差的 loss landscape 或大批量训练尤为重要。因为在这些情况下,最佳学习率受到最大稳定学习率的限制。因此该研究假设梯度裁剪应该有助于将 NF-ResNet 有效地扩展到大批量设置。
借助一种称为 AGC 的梯度裁剪方法,该研究探索设计了 Normalizer-Free 架构,该架构实现了 SOTA 的准确率和训练速度。
当前图像分类任务的 SOTA 大多是 EfficientNet 系列模型 (Tan & Le, 2019)取得的,该系列的模型经过优化以最大化测试准确率,同时最小化参数量和 FLOP 计数,但它们的低理论计算复杂度并没有转化为训练速度的提高。
 前所未有的水平">
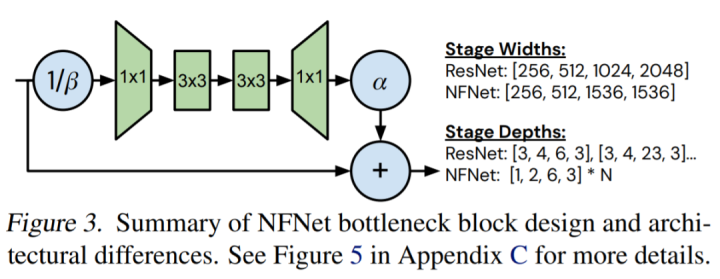
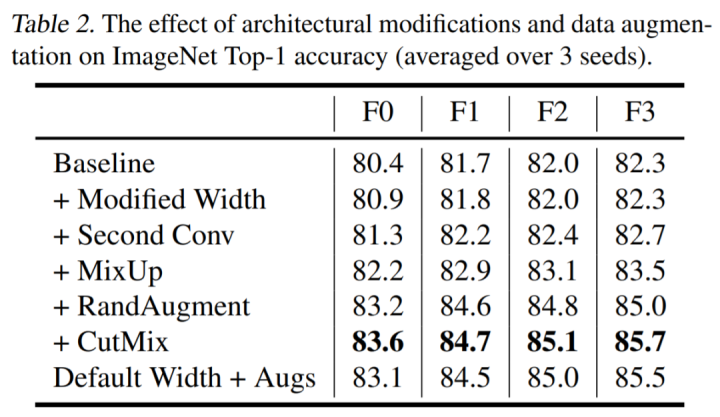
前所未有的水平">该研究通过手动搜索设计导向来探索模型设计的空间,这些导向对比设备上的实际训练延迟,可带来 ImageNet 上 holdout top-1 的帕累托前沿面的改进。它们对 holdout 准确率的影响如下表 2 所示:
 前所未有的水平">
前所未有的水平">实验
表 3 展示了六个不同的 NFNets(F0-F5)与其他模型在模型大小、训练延迟和 ImageNet 验证准确率方面的对比情况。NFNets-F5 达到了 86.0%的 SOTA top-1 准确率,相比 EfficientNet-B8 有了一定提升;NFNet-F1 的测试准确率与 EfficientNet-B7 相媲美,同时训练速度提升了 8.7 倍;NFNet-F6+SAM 达到了 86.5%的 top-1 准确率。
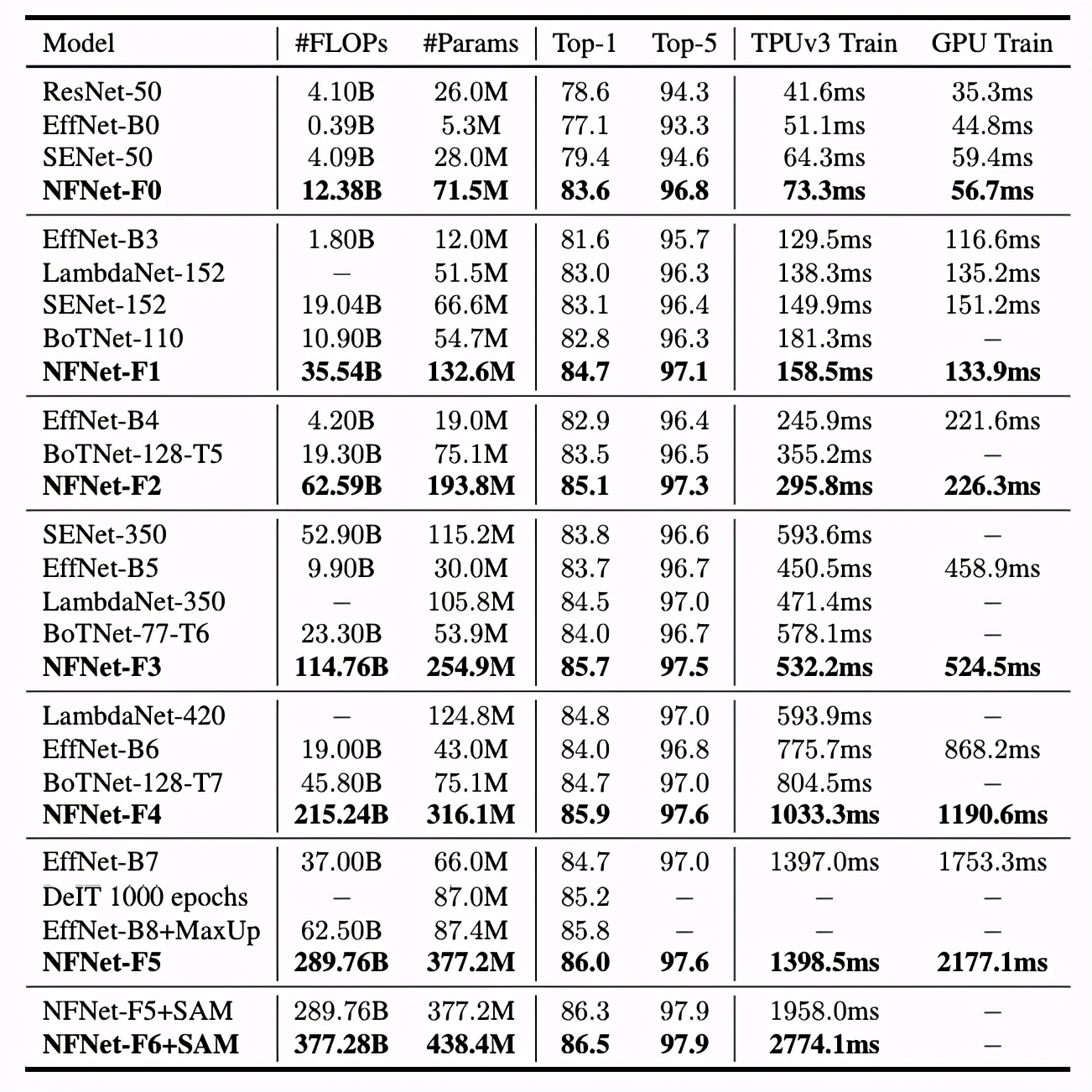 前所未有的水平">
前所未有的水平">NFNets 和其他模型在 ImageNet 数据集上的准确率对比。延迟是指在 TPU 或 GPU(V100)上运行单个完整训练步骤所需要的毫秒时间。
此外,研究者使用了一个 3 亿标注图像的数据集对 NFNet 的变体进行了预训练,并针对 ImageNet 进行微调。最终,NFNet-F4 + 在 ImageNet 上获得了 89.2% 的 top-1 准确率。这是迄今为止通过额外训练数据达到的第二高的验证准确率,仅次于目前最强大的半监督学习基线 (Pham et al., 2020) 和通过迁移学习达到的最高准确率。
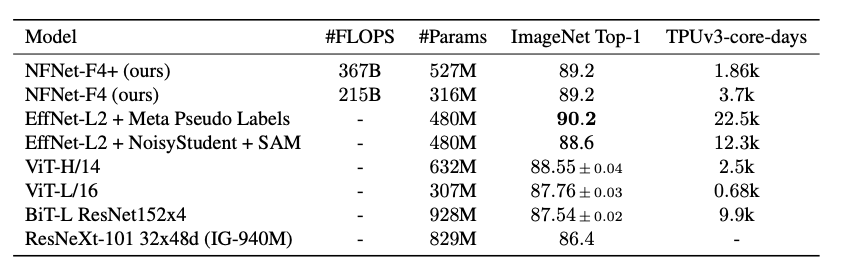 前所未有的水平">
前所未有的水平">表 5:使用额外数据进行大规模预训练后,ImageNet 模型迁移性能对比。
Andrew Brock 表示,虽然我们对于神经网络信号传递、训练规律的理解还有很多需要探索的方向,但无归一化的方法已经为人们提供了一个强有力的参考,并证明了发展这种深度理解能力可以有效地在生产环境中提升效率。

















