最近,CV 研究者对 transformer 产生了极大的兴趣并取得了不少突破。这表明,transformer 有可能成为计算机视觉任务(如分类、检测和分割)的强大通用模型。
我们都很好奇:在计算机视觉领域,transformer 还能走多远?对于更加困难的视觉任务,比如生成对抗网络 (GAN),transformer 表现又如何?
在这种好奇心的驱使下,德州大学奥斯汀分校的 Yifan Jiang、Zhangyang Wang,IBM Research 的 Shiyu Chang 等研究者进行了第一次试验性研究,构建了一个只使用纯 transformer 架构、完全没有卷积的 GAN,并将其命名为 TransGAN。与其它基于 transformer 的视觉模型相比,仅使用 transformer 构建 GAN 似乎更具挑战性,这是因为与分类等任务相比,真实图像生成的门槛更高,而且 GAN 训练本身具有较高的不稳定性。

- 论文链接:https://arxiv.org/pdf/2102.07074.pdf
- 代码链接:https://github.com/VITA-Group/TransGAN
从结构上来看,TransGAN 包括两个部分:一个是内存友好的基于 transformer 的生成器,该生成器可以逐步提高特征分辨率,同时降低嵌入维数;另一个是基于 transformer 的 patch 级判别器。
研究者还发现,TransGAN 显著受益于数据增强(超过标准的 GAN)、生成器的多任务协同训练策略和强调自然图像邻域平滑的局部初始化自注意力。这些发现表明,TransGAN 可以有效地扩展至更大的模型和具有更高分辨率的图像数据集。
实验结果表明,与当前基于卷积骨干的 SOTA GAN 相比,表现最佳的 TransGAN 实现了极具竞争力的性能。具体来说,TransGAN 在 STL-10 上的 IS 评分为 10.10,FID 为 25.32,实现了新的 SOTA。
该研究表明,对于卷积骨干以及许多专用模块的依赖可能不是 GAN 所必需的,纯 transformer 有足够的能力生成图像。
在该论文的相关讨论中,有读者调侃道,「attention is really becoming『all you need』.」

不过,也有部分研究者表达了自己的担忧:在 transformer 席卷整个社区的大背景下,势单力薄的小实验室要怎么活下去?
如果 transformer 真的成为社区「刚需」,如何提升这类架构的计算效率将成为一个棘手的研究问题。
基于纯 Transformer 的 GAN
作为基础块的 Transformer 编码器
研究者选择将 Transformer 编码器(Vaswani 等人,2017)作为基础块,并尽量进行最小程度的改变。编码器由两个部件组成,第一个部件由一个多头自注意力模块构造而成,第二个部件是具有 GELU 非线性的前馈 MLP(multiple-layer perceptron,多层感知器)。此外,研究者在两个部件之前均应用了层归一化(Ba 等人,2016)。两个部件也都使用了残差连接。
内存友好的生成器
NLP 中的 Transformer 将每个词作为输入(Devlin 等人,2018)。但是,如果以类似的方法通过堆叠 Transformer 编码器来逐像素地生成图像,则低分辨率图像(如 32×32)也可能导致长序列(1024)以及更高昂的自注意力开销。
所以,为了避免过高的开销,研究者受到了基于 CNN 的 GAN 中常见设计理念的启发,在多个阶段迭代地提升分辨率(Denton 等人,2015;Karras 等人,2017)。他们的策略是逐步增加输入序列,并降低嵌入维数。
如下图 1 左所示,研究者提出了包含多个阶段的内存友好、基于 Transformer 的生成器:
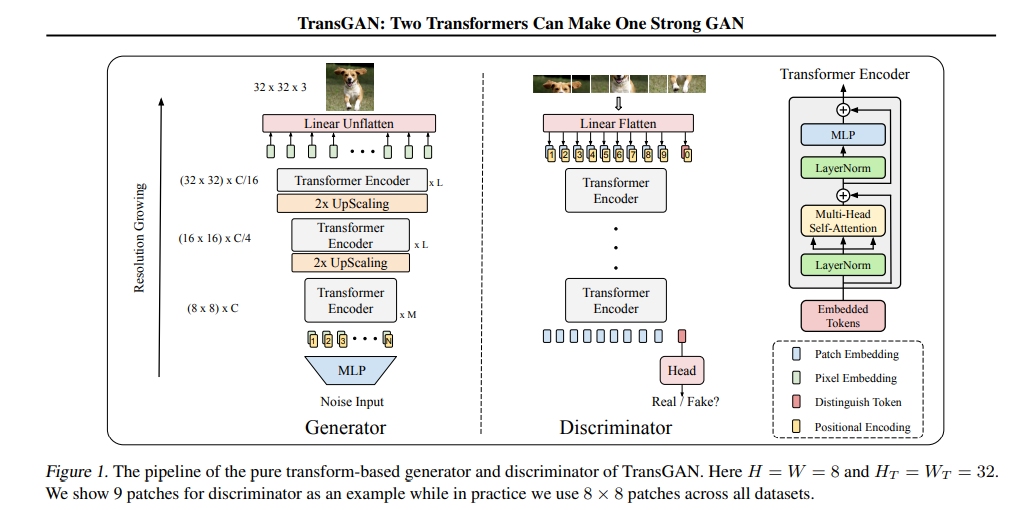
每个阶段堆叠了数个编码器块(默认为 5、2 和 2)。通过分段式设计,研究者逐步增加特征图分辨率,直到其达到目标分辨率 H_T×W_T。具体来说,该生成器以随机噪声作为其输入,并通过一个 MLP 将随机噪声传递给长度为 H×W×C 的向量。该向量又变形为分辨率为 H×W 的特征图(默认 H=W=8),每个点都是 C 维嵌入。然后,该特征图被视为长度为 64 的 C 维 token 序列,并与可学得的位置编码相结合。
与 BERT(Devlin 等人,2018)类似,该研究提出的 Transformer 编码器以嵌入 token 作为输入,并递归地计算每个 token 之间的匹配。为了合成分辨率更高的图像,研究者在每个阶段之后插入了一个由 reshaping 和 pixelshuffle 模块组成的上采样模块。
具体操作上,上采样模块首先将 1D 序列的 token 嵌入变形为 2D 特征图
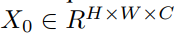
,然后采用 pixelshuffle 模块对 2D 特征图的分辨率进行上采样处理,并下采样嵌入维数,最终得到输出
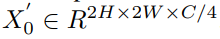
。然后,2D 特征图 X’_0 再次变形为嵌入 token 的 1D 序列,其中 token 数为 4HW,嵌入维数为 C/4。所以,在每个阶段,分辨率(H, W)提升到两倍,同时嵌入维数 C 减少至输入的四分之一。这一权衡(trade-off)策略缓和了内存和计算量需求的激增。
研究者在多个阶段重复上述流程,直到分辨率达到(H_T , W_T )。然后,他们将嵌入维数投影到 3,并得到 RGB 图像。
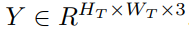
用于判别器的 tokenized 输入
与那些需要准确合成每个像素的生成器不同,该研究提出的判别器只需要分辨真假图像即可。这使得研究者可以在语义上将输入图像 tokenize 为更粗糙的 patch level(Dosovitskiy 等人,2020)。
如上图 1 右所示,判别器以图像的 patch 作为输入。研究者将输入图像
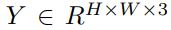
分解为 8 × 8 个 patch,其中每个 patch 可被视为一个「词」。然后,8 × 8 个 patch 通过一个线性 flatten 层转化为 token 嵌入的 1D 序列,其中 token 数 N = 8 × 8 = 64,嵌入维数为 C。再之后,研究者在 1D 序列的开头添加了可学得位置编码和一个 [cls] token。在通过 Transformer 编码器后,分类 head 只使用 [cls] token 来输出真假预测。
实验
CIFAR-10 上的结果
研究者在 CIFAR-10 数据集上对比了 TransGAN 和近来基于卷积的 GAN 的研究,结果如下表 5 所示:
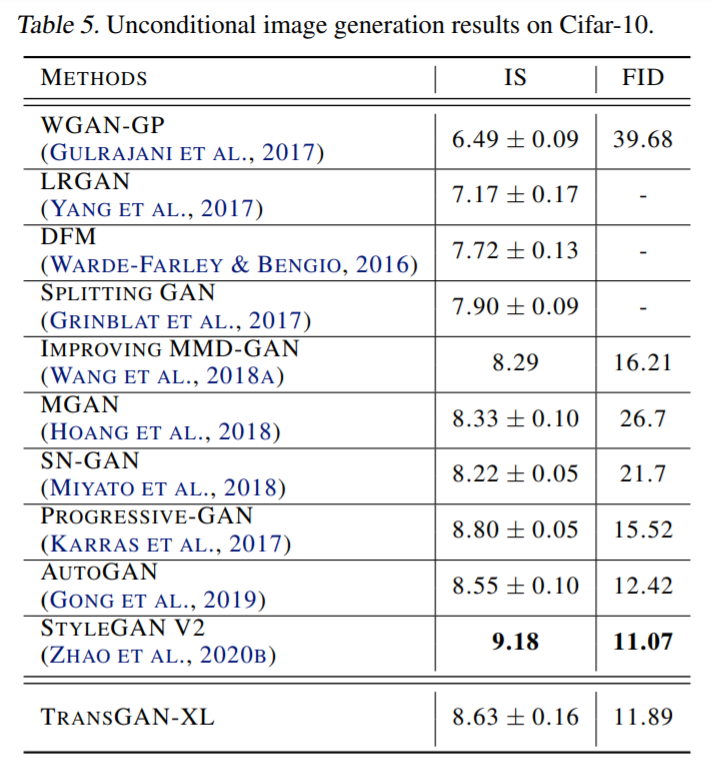
如上表 5 所示,TransGAN 优于 AutoGAN (Gong 等人,2019) ,在 IS 评分方面也优于许多竞争者,如 SN-GAN (Miyato 等人, 2018)、improving MMDGAN (Wang 等人,2018a)、MGAN (Hoang 等人,2018)。TransGAN 仅次于 Progressive GAN 和 StyleGAN v2。
对比 FID 结果,研究发现,TransGAN 甚至优于 Progressive GAN,而略低于 StyleGANv2 (Karras 等人,2020b)。在 CIFAR-10 上生成的可视化示例如下图 4 所示:

STL-10 上的结果
研究者将 TransGAN 应用于另一个流行的 48×48 分辨率的基准 STL-10。为了适应目标分辨率,该研究将第一阶段的输入特征图从(8×8)=64 增加到(12×12)=144,然后将提出的 TransGAN-XL 与自动搜索的 ConvNets 和手工制作的 ConvNets 进行了比较,结果下表 6 所示:
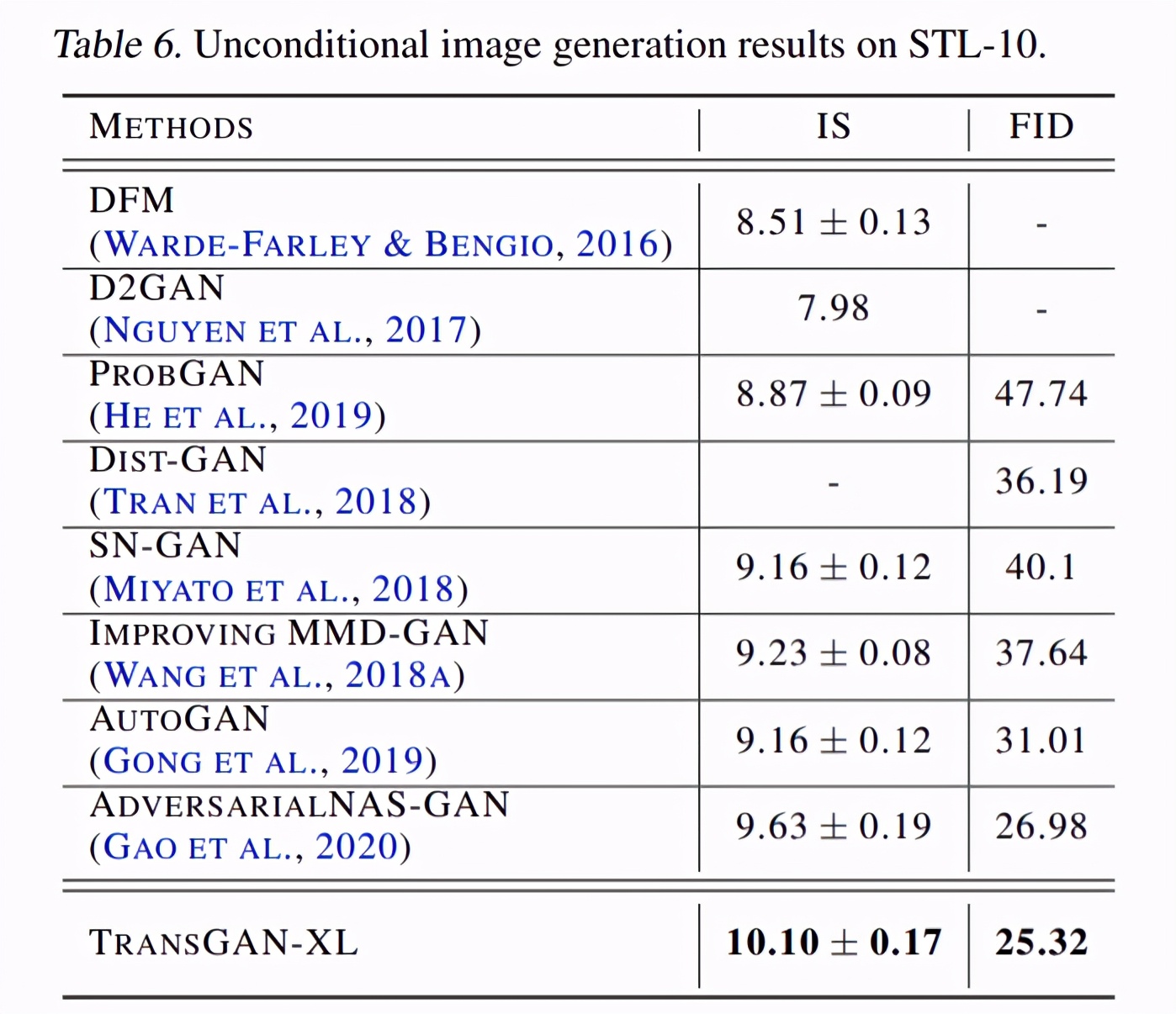
与 CIFAR-10 上的结果不同,该研究发现,TransGAN 优于所有当前的模型,并在 IS 和 FID 得分方面达到新的 SOTA 性能。
高分辨率生成
由于 TransGAN 在标准基准 CIFAR-10 和 STL-10 上取得不错的性能,研究者将 TransGAN 用于更具挑战性的数据集 CelebA 64 × 64,结果如下表 10 所示:
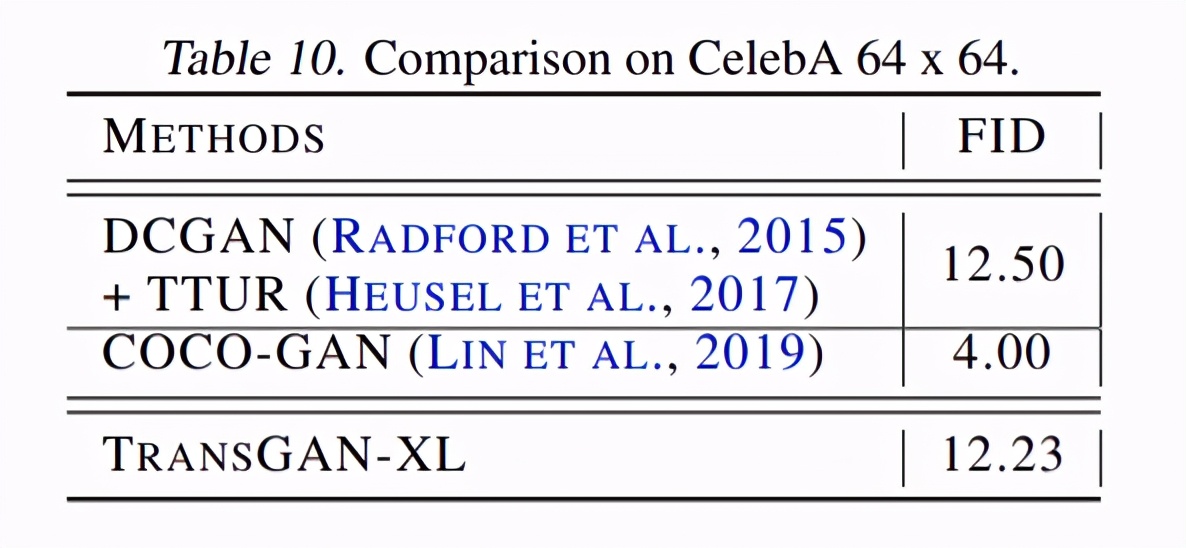
TransGAN-XL 的 FID 评分为 12.23,这表明 TransGAN-XL 可适用于高分辨率任务。可视化结果如图 4 所示。
局限性
虽然 TransGAN 已经取得了不错的成绩,但与最好的手工设计的 GAN 相比,它还有很大的改进空间。在论文的最后,作者指出了以下几个具体的改进方向:
- 对 G 和 D 进行更加复杂的 tokenize 操作,如利用一些语义分组 (Wu et al., 2020)。
- 使用代理任务(pretext task)预训练 Transformer,这样可能会改进该研究中现有的 MT-CT。
- 更加强大的注意力形式,如 (Zhu 等人,2020)。
- 更有效的自注意力形式 (Wang 等人,2020;Choromanski 等人,2020),这不仅有助于提升模型效率,还能节省内存开销,从而有助于生成分辨率更高的图像。
作者简介
本文一作 Yifan Jiang 是德州大学奥斯汀分校电子与计算机工程系的一年级博士生(此前在德克萨斯 A&M 大学学习过一年),本科毕业于华中科技大学,研究兴趣集中在计算机视觉、深度学习等方向。目前,Yifan Jiang 主要从事神经架构搜索、视频理解和高级表征学习领域的研究,师从德州大学奥斯汀分校电子与计算机工程系助理教授 Zhangyang Wang。
在本科期间,Yifan Jiang 曾在字节跳动 AI Lab 实习。今年夏天,他将进入 Google Research 实习。
一作主页:https://yifanjiang.net/