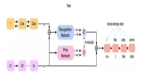
柏林工业大学深度学习方向博士生 Tilman Krokotsch 在多项任务中对比了 8 种自编码器的性能。

深度学习中的自编码器。图源:https://debuggercafe.com/autoencoders-in-deep-learning/
目前,很多研究者仍在使用堆叠自编码器进行无监督预训练。柏林工业大学深度学习方向博士生 Tilman Krokotsch 对此感到疑惑:堆叠自编码器难道不是算力低下时代训练深度模型的变通方案吗?现在算力相对充足了,为什么还要用?
于是,他决定在多项不同任务中对比原版深度自编码器(AE)和堆叠自编码器。
项目地址:https://github.com/tilman151/ae_bakeoff
Krokotsch 对比了原版深度自编码器所有改变潜在空间行为方式或有可能提升下游任务性能的变体,不包括应用特定的损失(如图像领域的 VGG19 损失)和编码器与解码器类型(如 LSTM vs. CNN)。最终,Krokotsch 选择了以下八种自编码器进行对比:
- 浅层自编码器
- 深度自编码器(原版 AE)
- 堆叠自编码器
- 稀疏自编码器
- 去噪自编码器
- 变分自编码器(VAE)
- Beta 变分自编码器(beta-VAE)
- 向量量化变分自编码器(vq-VAE)
Krokotsch 不仅介绍了这些自编码器的独特性,还在以下方面进行了对比:
- 重建质量
- 对来自潜在空间的样本的解码质量
- 潜在空间插值质量
- 利用 UMAP 可视化得到的潜在空间结构
- 利用重建误差的异常检测 ROC 曲线
- 拟合自编码器特征的线性层的分类准确率
所有自编码器均使用相同的简单架构,该架构使用全连接编解码器、批归一化和 ReLU 激活函数,输出层使用 sigmoid 激活函数。除了浅层自编码器以外,所有自编码器均具备三个编码器和解码器层。
潜在空间的维度和网络参数量基本恒定。这意味着变分自编码器比原版有更多参数,因为编码器为维度为 n 的潜在空间生成 2n 个输出。在测试过程中,每个自编码器执行两次训练运行:一次潜在空间的维度为 20,一次维度为 2。第二次训练的模型用于异常检测,第一次的模型用于其他任务。
对比测试使用的数据集为 MNIST。Krokotsch 从训练数据集中随机采样 5000 个样本作为验证集,将默认训练 / 测试分割进一步划分为训练 / 验证 / 测试分割。
接下来我们来看这些自编码器变体及其对比情况。
「参赛选手」:8 个自编码器
Krokotsch 介绍了这些自编码器的工作原理及独特性,并尝试对其性能做出一些假设。
浅层自编码器
浅层自编码器算不上真的竞争对手,因为它的能力远远落后于其他变体。在这里,它作为基线存在。

上式为浅层自编码器的重建公式,从中可以看出自编码器如何以半数学的方式重建样本 x。
浅层自编码器的特点是编码器和解码器中只有一个层。它与 PCA 的区别是在编码器中使用 ReLU 激活函数,在解码器中使用 sigmoid 函数,因此它是非线性的。
一般情况下,自编码器的默认重建损失是均方误差。而 Krokotsch 使用的是二值交叉熵 (binary cross-entropy, BCE),因为它能在初步实验中获得更美观的图像。所有自编码器均使用以下 BCE 版本:

其中 x^(i)_j 是第 i 个输入图像的第 j 个像素,x̂^(i)_j 是对应的重建。损失即汇总每张图像再基于 batch 求平均。这一决策对于变分自编码器非常重要。
深度自编码器
深度自编码器(原版自编码器)是浅层自编码器的扩大版。它们基本相同,只不过深度自编码器拥有更多层。它们的重建公式是一样的。
深度自编码器的潜在空间没有约束,因此应当能够编码最多信息。
堆叠自编码器
堆叠自编码器即通过仅训练浅层自编码器来得到深度自编码器。只不过训练方式不是端到端,而是逐层贪婪训练:首先,以第一个编码器和最后一个解码器形成一个浅层自编码器;训练完这些层之后,使用编码层编码整个数据集;然后基于第二个编码器和倒数第二个解码器层形成另一个浅层自编码器,使用编码得到的数据集训练第二个浅层自编码器;重复这一过程,直到到达最内层。最终得到的深度自编码器由许多个浅层自编码器堆叠而成。
堆叠自编码器与深度自编码器只在训练过程上存在区别,因此它们也具备相同的重建函数。堆叠自编码器的潜在空间没有约束,但是由于贪婪训练,其编码能力略差。
稀疏自编码器
稀疏自编码器在潜码方面存在稀疏约束,潜码中每个元素的活跃概率为 p。为此在训练过程中需要为其添加辅助损失:

其中 z¯(i) 是潜码中第 i 个元素基于 batch 的平均激活值。这一损失函数对应于 p 和 z¯(i) 二项式分布之间的 KL 散度 |z| 的总和。可能存在其他实现,可以满足该稀疏约束。
为了使该稀疏损失成为可能,我们需要将潜码的范围缩放至 [0,1],以便将其理解为概率。这通过 sigmoid 激活函数完成,重建公式如下:

稀疏自编码器的完整损失结合了重建损失和稀疏损失:

在所有实验中,p 值设置为 0.25,β 值设置为 1。
去噪自编码器
去噪自编码器的潜在空间没有约束,它旨在通过对输入数据应用噪声来学习更高效的编码。去噪自编码器并未将输入数据直接馈入网络,而是添加了高斯噪声:

其中 clip 表示将输入裁剪为 [0,1],标量 β 表示噪声的方差。因此,去噪自编码器的训练方式是基于噪声输入数据重建干净样本,重建公式如下:

不过,噪声输入仅在训练过程中使用。在评估该自编码器时,使用的是原始输入数据。去噪自编码器使用的损失函数与之前的自编码器相同。在所有实验中, β 值被设置为 0.5。
变分自编码器
理论上,变分自编码器 (VAE) 与原版 AE 关联不大。但在实践中,其实现和训练均很类似。VAE 将重建解释为随机过程,使之具备不确定性。编码器不输出潜码,而是输出表示潜码概率分布的参数;然后,解码器从这一分布中接收样本。默认的分布族选择是高斯 N(μ;diag(Σ))。其重建公式如下:

其中 enc_μ(x) 和 enc_Σ(x) 将 x 编码为μ 和 Σ,两个编码器共享大部分参数。在实践中,单个编码器获得两个输出层而不是一个。问题在于,从分布中采样必须要具备梯度和从解码器到编码器的反向传播。解决方法叫做「重参数化」,将来自标准高斯分布的样本转换为来自被 μ 和 Σ 参数化的高斯分布的样本:

该公式的梯度与 μ 和 Σ 有关,也可以实现反向传播。
变分自编码器要求高斯分布类似于标准高斯,从而进一步约束其潜在空间。其分布参数接受 KL 散度的惩罚:

KL 散度基于 batch 求平均值。重建损失按照上文方式求平均,以保留重建损失和散度损失之间正确的比率。完整训练损失如下:

我们尽量使编码器输出标准高斯,这样就可以直接解码来自标准高斯分布的样本。这种无条件采样是 VAE 的一种独特属性,使其成为类似 GAN 的生成模型。无条件采样的公式如下:

Beta 变分自编码器(beta-VAE)
beta-VAE 是 VAE 的泛化,只改变了重建损失和散度损失之间的比率。散度损失的影响因子用标量 β 来表示,因此损失函数如下所示:

β<1 放松了对潜在空间的约束,而 β>1 则加剧了这一约束。前者会得到更好的重建结果,后者则得到更好的无条件采样。Krokotsc 在严格版本中使用了 β=2,在宽松版本中使用了 β=0.5。
向量量化变分自编码器(vq-VAE)
vq-VAE 使用均匀的类别分布来生成潜码。编码器输出中的每个元素都被该分布中的类别值取代,后者是其最近邻。这是一种量化,意味着潜在空间不再是连续的,而是离散的。

类别本身可以通过将误差平方和最小化为编码器输出来学得:

其中 z 表示编码器的输出,ẑ 表示对应的量化后潜码,sg 表示停止梯度算子(stop gradient operator)。另外,编码器输出的编码结果类似于通过误差平方和得到的类别:

这叫做 commitment 损失。KL 散度损失并非必要,因为 KL 散度是均匀类别分布的的常量。将这种损失与重建损失结合起来,得到:

实验中将 β 的值设置为 1。
由于 vq-VAE 是生成模型,我们也可以执行无条件采样。
自编码器「大乱斗」
重建质量
首先,我们来看每种自编码器对输入的重建质量。以下是不同自编码器在 MNIST 测试集中 16 张图像上的结果:


浅层自编码器无法准确重建一些测试样本。4 和 9 勉强可以辨认,一些数字则完全看不出来。其他自编码器的效果要好一些,但也并不完美:去噪自编码器会使一些细线消失;稀疏和堆叠自编码器则在重建笔画异常的数字(如 5 和第一个 9)。整体的重建结果都有一点模糊,这对于自编码器而言是正常的。vq-VAE 的重建结果没有那么模糊,其作者认为这是离散潜在空间的缘故。
不同自编码器的重建质量区别不大。下表列举了基于样本集合的二值交叉熵平均值:

不出所料,表现最差的是浅层自编码器,它缺乏捕捉 MNIST 结构的能力。原版自编码器表现不错,与稀疏自编码器和 vq-VAE 名列前茅。但稀疏自编码器和 vq-VAE 似乎并未经历潜在空间约束,而 VAE 和 beta-VAE 由于潜在空间约束获得了更高的误差。此外,VAE 中的采样过程引入了损害重建误差的噪声。
采样
该试验仅包括四个可执行无条件采样的自编码器:VAE、宽松和严格版本的 beta-VAE、vq-VAE。对每个自编码器,采样 16 个潜码并解码。对于 VAE 和 beta-VAE,从标准高斯分布中采样。而 vq-VAE 的潜码则从其学得类别中均匀采样得到。

上图中最有意义的生成样本来自严格版 beta-VAE。这是因为其训练重点放在了高斯先验上,编码器输出最接近来自标准高斯的样本,从而使得解码器成功解码采样自真正标准高斯的潜码。另外,其生成图像的变化较小,例如右侧数字既像 5 又像 6。
宽松版 beta-VAE 生成图像则更多样化,尽管可识别的图像较少。标准 VAE 的表现在二者之间。令人略感失望的是 vq-VAE,它采样的图像完全不像 MNIST 数字。
插值
插值任务展示了潜在空间区域的密集程度。Krokotsch 从测试集中编码了两个图像 2 和 7,并执行线性插值。然后将插值解码以接收新图像。如果来自插值潜码的图像能够显示有意义的数字,则类别区域之间的潜码可被自编码器高效利用。

对于所有 VAE 类型,Krokotsch 在瓶颈操作之前即执行插值。这意味着对于 VAE 和 beta-VAE,先插值高斯参数,再进行采样;对于 vq-VAE,则先插值再量化。
从上图中可以看到 VAE 和 beta-VAE 可以生成相对有意义的插值。其他自编码器则完全不行。
潜在空间结构
Krokotsch 利用 UMAP 算法可视化潜在空间结构,该算法可以将潜在空间缩减至二维,并保留潜码的近邻。下图展示了自编码器每个自编码器潜在空间的散点图,每个点表示测试集中一个图像的潜码,颜色表示图像中的数字。

这些图之间存在一些明显的相似性。首先,原版、堆叠、稀疏、去噪自编码器和 vq-VAE 很相似。0(蓝色)、1(橙色)、2(绿色)和 6(粉色)的簇总能得到很好地分割,因此它们与其他数字看起来区别较大。还有 4-7-9 和 3-5-8 的簇,这表明这些数字之间存在连接,如在 3 上添加两个直线可以得到 8。这些自编码器可以编码数字之间的结构相似性。
但浅层自编码器很难将数字分类为簇。VAE 和 beta-VAE 与其他不同,我们可以从中看到散度损失的影响。
分类
潜在空间图表明很多自编码器擅长将 MNIST 数字分簇,尽管它们并未接收到任何标签。那么如何利用这一点来执行 MNIST 数字分类呢?
Krokotsch 使用 20 维潜码拟合稠密分类层,该层仅在来自训练集的 550 个标注样本训练。也就是说,使用这些自编码器做半监督学习。从头训练原版编码器和分类层获得的准确率是 0.4364。下表展示了这些自编码器的改进效果:

几乎所有自编码器都基于基线有所改进,除了稀疏自编码器。去噪自编码器获得最优结果,其次是原版自编码器和 vq-VAE。去噪自编码器添加的输入噪声似乎产生了最适合分类任务的特征。
最有趣的一点是,即使浅层自编码器也能稍微提升准确率,即使它只有一层,参数也更少。这再一次表明,智能数据使用往往胜过大模型。
VAE 和 beta-VAE 再一次表明,散度损失对潜在空间的约束。稀疏自编码器的结果比基线还差,似乎是因为稀疏特征完全不适合用于分类 MNIST 数字。对于其效果,还需要在其他数据集上再进行测试。
异常检测
使用自编码器执行异常检测任务相对直接。使用训练好的模型,为测试样本计算重建损失,得到异常分数。如果样本的重建结果较好,则它可能类似于训练数据;如果重建结果较差,则样本被认为是异常值。自编码器可以利用训练数据之间的关联来学习有效的低维表示。只要这些关联出现,则测试样本就可以得到不错地重建。反之,则自编码器无法进行很好地重建。
该任务的一大挑战是找出异常分数的最优阈值。下图展示了 ROC 曲线图和曲线下面积:

浅层自编码器以 0.91 的 AUC 将其他自编码器甩在身后,紧随其后的是堆叠自编码器。而且对于不同数字和潜在空间维度而言,不同自编码器的排序是不变的。
为什么这两个在其他任务中拖后腿的自编码器如此擅长异常检测呢?原因似乎在于其他任务依赖潜在空间的泛化能力。而异常检测无需泛化,至少不需要太好的泛化能力。
结论
经过对比实验后,Krokotsch 并未找出自编码器中的王者,他认为选择哪种自编码器取决于任务本身。想要基于噪声生成人脸?使用变分自编码器。图像过于模糊?试试 vq-VAE。分类任务?选择去噪自编码器。如果要做异常检测任务,或许可以尝试浅层自编码器或 PCA。有时,少即是多。