












本文转载自微信公众号「程序喵大人」,作者程序喵大人。转载本文请联系程序喵大人公众号。
本专题将分析C++各种代码操作的效率,包括不同类型变量的存储效率,使用智能指针、循环、函数参数、虚函数、数组等的效率,以及如何做针对性优化,或选择更有效的替代方案。
详细目录看下图:
变量存储区域:
在C++中,变量存储在哪类内存,取决于开发者声明它们的方式。如果数据不连续,分成无数段分散在内存中,会降低数据的Cache命中率。因此,理解变量如何存储非常重要。
栈空间
栈空间,通常用于存储局部变量、函数参数、函数返回地址、函数返回前需要恢复的寄存器等。每次调用函数时,系统都会分配一段栈空间,用于存储这些东西,函数返回时,这段栈空间会被回收,下次调用函数时,程序还可以重用这段栈空间。
一般来说,程序每个线程有固定大小的栈空间,使用多少,回收多少,只是偏移量偏移多少的问题。栈空间特别高效是因为同一段内存空间可以被反复使用,内存很容易就加载到Cache中,Cache命中率更高。
我们可以多利用栈空间。所有的变量,最好都在使用它们的函数中声明。有些情况下可以在大括号{ }内声明变量,尽可能缩小变量的作用域。
全局或静态空间
全局变量,任何函数都可以访问,存储在内存的静态空间中。static关键字声明的变量、浮点常量、字符串常量、虚函数表等,都存储在静态空间中。
静态空间的优点是,可以在程序启动前就将其初始化为所需的值。缺点是,即使变量只使用一次,或者只在程序的一小部分中使用,它的内存,也会在程序整个运行过程中被占用,会降低Cache的效率。
尽量不要将变量声明为全局变量,一个变量如果被多个函数使用,可以考虑将其作为参数,但是参数传递是有开销的,如果我们想避免这类开销,难道就要声明为全局变量了吗?其实我们也可将变量存储在类对象中,多个函数都访问类对象中的变量成员。
某些情况下,可以考虑static和const共用,例如声明一个静态常量查询表:
- float SomeFunction(int x) {
- static const float list[] = {1.1, 2.2, 3.4, 4.4, 5.5};
- return list[x];
- }
这种方式的好处是,不需要在每次调用函数时对列表进行初始化。static声明意味着在第一次调用初始化后,后续就不再需要初始化,但这样效率较低,因为需要额外检查它是第一次调用,还是已经被调用过。加入const声明,可以告诉编译器,不需要对是否是第一次调用来进行检查。所以最好加上static和const声明,以便让编译器更好的优化。
字符串常量和浮点数常量,也经常保存在静态空间中,例如:
- a = b * 3.5;
- c = d + 3.5;
这里,常数3.5将存储在静态空间中,大多数编译器会识别出这两个常量是相同的,因此只需要存储一份常量。整个程序中所有相同的常量将被连接在一起,优化程序中常量的占用空间。
寄存器存储
寄存器是CPU中的一小块内存,用作临时存储。访问寄存器中的变量速度非常快,但是寄存器数量有限,存储的变量也有限。编译器优化时,会自动选择函数中的最常用变量,存到寄存器中。程序中的局部变量就很适合于存储在寄存器中。
寄存器数量有限,32位X86系统中,大约有6个整数寄存器用于通用目的,64位系统中有14个。而浮点变量使用不同的寄存器,32位系统中大约有8个可用的浮点寄存器,64位系统中有16个,当在64位系统中启用更高级的指令集时,可能会有更多可用的浮点寄存器。
volatile
这里需要特别关注下volatile关键字,该关键字表示其修饰的变量可以被另一个线程更改,防止编译器做一些过度优化。例如:
- volatile int seconds;
- void DelayFiveSeconds() {
- seconds = 0;
- while (seconds < 5) {
- // do nothing while seconds count to 5
- }
- }
在本例中,DelayFiveSeconds()将一直等待,直到另一个线程将seconds增加到5。
如果seconds没被声明为volatile,那么编译器可能会进行过度优化,将假定在while循环中seconds保持为0,循环内的任何内容都不能更改该值。循环将是while(0 < 5){},这将是个死循环。
关键字volatile的作用是,确保变量永远存储在内存中,而不是在寄存器中,并阻止对变量的所有优化。
注意volatile不保证原子性,它不会阻止两个线程同时尝试写操作。其他线程增加seconds的同时,试图将seconds设置为0,这样可能会失败。更安全的做法是,一个线程只读取seconds,并等待该值更改。
thread-local存储
C++11中可以使用thread_local关键字来声明线程本地变量,C++11前也有别的方式声明,被修饰的变量对于每个线程都有一份拷贝,保证了线程安全。thread-local存储效率较低,因为它是通过全局指针访问。我们应该尽量避免线程本地存储,可以更多将变量存储在线程自己的栈中,即在线程自己的函数中声明变量。
堆内存
堆内存主要通过操作符new和delete动态分配,或者使用函数malloc和free。如果以随机的顺序分配和释放不同大小的内存,很容易产生内存碎片,分散在堆内存的不同地方,而且频繁分配内存,开销也较大。尽量避免动态分配内存吧,或者用JeMalloc替换一波?或内存池?
整数变量和运算
整型大小
整数中,不同类型可能会有不同的大小,下图总结了不同整型的大小和最大最小值:
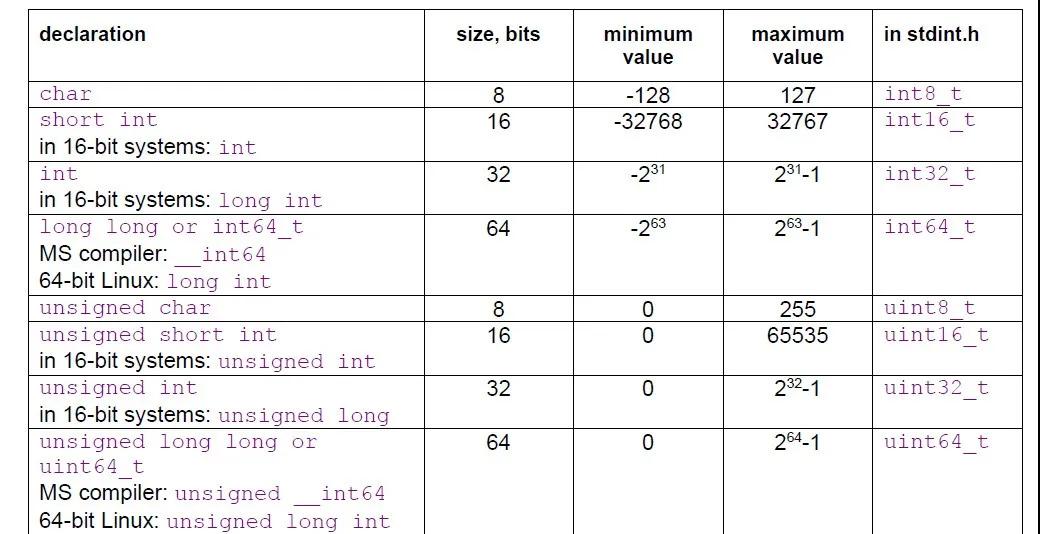
在不同的平台,声明特定大小整数的方法不同,我们可以使用标准头文件stdint.h,声明特定大小的整型,该方法还可以跨平台,可移植。
大多数情况下,整数运算非常快,但是,如果整数大于可用寄存器大小,效率就会低一些。例如,在32位系统中,使用64位整数效率低一些,特别是用于乘法或除法时。
如果声明了int类型,但是没有指定具体大小,编译器将始终选择最有效的整数大小。较小大小的整数如char、short int等,效率可能稍微低一些,在很多情况下,编译器在进行计算时,会将这些类型转换为默认大小的整数,然后只使用结果中的低8位或者低16位。在64位系统中,只要我们不做除法,使用32位整数和64位整数的效率其实没多大差别。
整数运算时,我们需要考虑中间计算的结果,看是否会导致溢出。例如表达式a=b+c+d,即使b、c、d都低于整数最大值,但是可能b+c就会导致整数溢出,我们需要时刻注意。
有符号整数和无符号整数
多数情况下,使用有符号整数和无符号整数,在速度上没有区别,但有一些特殊情况:
常量除法,当除以常量时,无符号整数比有符号整数效率更高,模运算类似。
对于大多数指令集,使用有符号整数到浮点数的转换,要比使用无符号整数转换更快。
有符号和无符号整数的溢出行为不同:无符号整数的溢出产生一个低正结果,有符号整数的溢出是官方未定义的。有符号整数,正常的行为是将正溢出转换为负值,但是编译器可能做一些优化,它会假设不会发生溢出。
有符号整数和无符号整数之间的转换,没有任何开销。这只不过是对同一符号位的不同解释而已。负整数在转换为无符号时,将被解释为一个非常大的正数。
- int a, b;
- double c;
- b = (unsigned int)a / 10; // 转换成无符号整数做除法更快
- c = a * 2.5; // 有符号整数隐式转换为double型
在上例中,将a转换为unsigned,可以使除法更快。当然,只有当a绝对不会是负数的时候,才可以这么转换。最后一行,在与常数2.5相乘之前,会隐式地将a转换为double,因为后者是double,这里a作为有符号整数去转换,效率更高。
注意,在进行比较操作时,例如<操作,不要混用有符号整数和无符号整数。有符号整数和无符号整数的比较,可能会产生意想不到的结果。
整数运算
整数运算通常非常快。简单的整数运算,如加法、减法、比较、位运算等,在大多数微处理器上只需要一个时钟周期。乘法和除法需要更长的时间。整数乘法在奔腾4CPU上需要11个时钟周期,大多数情况乘法都需要3 - 4个时钟周期,整数除法需要40 - 80个时钟周期,具体取决于CPU。
自增和自减运算
++i和i++速度一样快,当仅用于递增变量时,使用++i和i++没有任何区别,效果完全相同,例如:
for(i=0;i
浮点数及其运算
现代x86家族的CPU,有两种不同类型的浮点寄存器,对应不同类型的浮点指令,每种类型都有优缺点。
x87寄存器
x87寄存器是浮点运算的传统方法,这些寄存器都有长双精度,多个寄存器组成了一组寄存器栈,使用寄存器栈的优点有:
所有的计算都是用双精度完成的不同精度之间的转换不需要额外的时间。
对于数学函数,如对数函数和三角函数,有一些内置的指令。
代码很紧凑,在代码缓存中占用的空间很小。
寄存器栈也有缺点:
由于寄存器栈的组织方式,编译器很难创建寄存器变量。
浮点数比较速度很慢,除非启用更高的指令集。
当使用双精度时,除法、平方根和数学函数,需要更多的时间来计算。
向量寄存器
也叫矢量寄存器,有XMM、YMM或ZMM等寄存器,是进行浮点运算的一种较新的方法,浮点运算以单精度或双精度完成,中间结果的计算精度始终与操作数相同,使用向量寄存器的优点有:
- 制作浮点寄存器变量很容易。
- 向量操作可用于对向量寄存器中的多个变量进行并行计算。
它也有缺点:
- 不支持长双精度。
- 混合不同精度的表达式计算,需要精度转换指令,这可能非常耗时。
- 数学函数必须使用函数库,但这通常也比内置的硬件函数快。
在几乎所有具有浮点运算能力的系统中,都可以使用x87浮点寄存器,而XMM、YMM和ZMM寄存器分别需要SSE、AVX和AVX512指令集。
现代编译器,更多情况下会使用向量寄存器,来进行浮点运算。很少有编译器可以混合两种不同类型的浮点运算,不能为每次运算选择最优类型。大多数情况下,当没有使用向量运算时,单精度浮点数运算和双精度浮点数运算速度大体相同,无论精度如何,加法、减法、乘法等运算的速度都是相同的。但如果开启向量运算,使用XMM等向量寄存器时,单精度除法、平方根和数学函数的计算速度要比双精度快。
如果真的对精度有高要求,可以使用双精度浮点数,不需要太担心速度。但如果我们可以利用好向量运算,或者有个大的浮点数数组,想要充分利用Cache,那可以考虑使用单精度浮点数。
浮点加法需要3 - 6个时钟周期,乘法操作需要4 - 8个时钟周期,除法需要14 - 45个时钟周期,这取决于CPU。当使用传统的x87浮点寄存器时,浮点数比较操作,和浮点数到整数的转换操作,效率较低。
注意:
同一个表达式中,不要混合使用单精度和双精度浮点数。
尽量避免整型和浮点型的转换。
向量寄存器支持多种模式,可以根据实际需要设置不同的模式,例如flush-to-zero模式、denormals-are-zero模式等。
枚举
枚举其实就是个伪装的整数,它的效率与整数相同。注意,枚举值名字可能与一些变量或函数的名字发生冲突,可以将头文件中的枚举设置成较长且唯一的名字,或者放入命名空间,也可以使用enum class声明枚举。
布尔
布尔操作的顺序优化
布尔操作符&&和||的操作数按以下方式计算。如果&&的第一个操作数为false,则根本不计算第二个操作数,因为无论第二个操作数的值是多少,结果都是false。同样,如果||的第一个操作数为true,则不计算第二个操作数,因为结果肯定是true。
所以,我们可以将通常为true的操作数放在&&表达式的最后,或放在||表达式的最开始。例如,假设a在50%的情况下为真,b在10%的情况下为真。当a为真时,表达式a && b需要计算b,这是50%的情况。等价的表达式b && a只需要在b为真时计算a,这只占10%的时间。
如果一个操作数比另一个操作数更可预测,那么将最可预测的操作数放在前面。
如果一个操作数比另一个操作数计算得快,那么将计算得最快的操作数放在前面。
但是,在改变布尔操作数的顺序必须要小心:如果操作数的计算有副作用,如果第一个操作数被用来确定第二个操作数是否有效,则不能交换操作数。例如:
- unsigned int i;
- const int ARRAYSIZE = 100;
- float list[ARRAYSIZE];
- if (i < ARRAYSIZE && list[i] > 3) {...}
这里我们不能交换顺序,因为当i>ARRAYSIZE时,list[i]操作是非法的,另一个例子:
- if (handle != INVALID_HANDLE_VALUE && WriteFile(handle, ...)) {...}
同样,这里我们也不可能交换顺序。
布尔值
布尔变量被存储为8位整数,值为0表示false, 1表示true。此种意义上,布尔变量由多种因素确定,即所有以布尔变量作为输入的操作符,有可能不只是0和1,而以布尔变量作为输出的操作符,只能产出0或1的值。这样可能布尔变量作为输入的操作效率较低。
举例来说,对于
- bool a, b, c, d;
- c = a && b;
- d = a || b;
而编译器可能是这么实现的:
- bool a, b, c, d;
- if (a != 0) {
- if (b != 0) {
- c = 1;
- } else {
- goto cfalse;
- }
- } else {
- cfalse:
- c = 0;
- }
- if (a == 0) {
- if (b == 0) {
- d = 0;
- } else {
- goto dtrue;
- }
- } else {
- dtrue:
- d = 1;
- }
当然,这不是最优方式。在错误预测的情况下,分支可能还需要很长时间。如果可以确定操作数除了0和1之外,没有其他值,那么布尔操作的效率会高得多。编译器没有做这样的假设的原因是,如果变量没有初始化,或者来源未知,那么它们可能有其它的值。如果a和b已经初始化为有效值,或者它们来自产生布尔输出的值,则可以优化上述代码。优化后的代码如下所示:
- char a = 0, b = 0, c, d;
- c = a & b;
- d = a | b;
这里,我们可以使用char(或int)代替bool,以便能够使用位操作符(&和|)而不是布尔操作符(&&和||)。按位操作符,是只占用一个时钟周期的单个指令。即使a和b的值不是0或1,OR操作符(|)也可以工作。但如果操作数的值不是0和1,则AND操作符(&)和异或操作符(^)可能会产生不一致的结果。
注意这里有个坑,我们不能使用~代替!,相反,如果确定输入是0或1,可以通过与1做异或来得到!的值。
举例:
- bool a, b;
- b = !a;
可以被优化成:
- char a = 0, b;
- b = a ^ 1;
指针和引用
看代码:
- void FuncA(int *p) {
- *p = *p + 2;
- }
- void FuncB(int &r) {
- r = r + 2;
- }
这两段分别使用指针和引用的代码,它们实际上做的是相同的事情,具体我们可以看它们编译后生成的代码,其实它们的汇编代码完全相同,区别仅仅是编程风格的问题。
指针优于引用的理由是:
直接看上面的函数体,很明显看出p是一个指针,但不清楚r是一个引用,还是一个简单的变量,使用指针让阅读代码的人更清楚地知道发生了什么。
指针的指向可以更改,使用更灵活,还可以用指针做算术运算。
引用优于指针的理由是:
引用比指针更安全,因为在大多数情况下,引用肯定指向一个有效的地址,而且引用的指向不可更改。而对于指针,如果没有初始化,那指针算术计算超出了有效地址的范围,或者指针类型转换为错误的类型,那么指针可能是无效的,并导致致命错误。
引用对于复制构造函数和重载运算符很有用。
声明为常量引用的函数形参,可接受表达式作为实参,而指针和非常量引用需要变量。
使用指针或引用访问变量,可能与直接访问一样快。函数中声明的所有非静态变量,都存储在栈上,实际上它们也是通过栈指针进行寻址。同样的,类中声明的所有非静态变量,也是通过隐式的this指针访问,所以,大多数变量实际上都是通过指针访问。
使用指针或引用也有缺点,它需要一个额外的寄存器来保存指针或引用的值,而寄存器是一种稀缺资源,特别是在32位模式下。如果寄存器数量不足,那么每次使用指针时都必须从内存中加载,速度就会变慢。
注意指针这里有个坑:即指针的算数运算:
- struct A {
- int a;
- int b;
- };
- A *a;
- a = ++a;
- a = ++(char*)a;
++a和++(void*)a,它们的运算结果是不同的,++a里其实加的值是8,因为A大小是8,++(void*)a里其实加的值是1,因为(char)大小是1。
函数指针
如果目标地址可以预测,通过函数指针调用函数,相比于直接调用函数,要多花几个时钟周期。如果函数指针的值,与上次执行语句时相同,则目标地址会被预测成功,而如果函数指针的值发生变化,目标地址很可能会被错误预测,预测失败会导致有多个时钟周期的延迟。
智能指针
智能指针是一种行为与指针类似的对象。C++11后基本上有两种智能指针,unique_ptr和shared_ptr,unique_ptr的特点是有且只有一个指针拥有所分配的对象,只有一个对象指针拥有对象的所有权,而shared_ptr的特点是可以有多个指针共同指向同一个对象,显然shared_ptr比unique_ptr的开销更大一些。选择智能指针时可以更多的选择unique_ptr,编译器可以做优化,能够在简单情况下剥离掉unique_ptr的大部分或者全部开销,这样效率就和直接使用new和delete基本相同。一般一个函数内new,需要另一个函数内delete的场景下,可以考虑使用智能指针。但如果在同一个函数内new和delete,且函数体没有过多的分支,或许就不需要使用智能指针啦。
有时候程序可能需要很多动态分配的小对象,每个对象都有自己的智能指针,这种成本是否较高?你有什么解决方案吗?可以在留言板里留言哦!



















