












本文转载自微信公众号「分布式点滴」,作者穆尼奥。转载本文请联系分布式点滴公众号。
本篇是实验一,管理文件系统的页在内存中的缓存 —— buffer pool manager。
概览
实验的目标系统 BusTub 是一个面向磁盘的 DBMS,但磁盘上的数据不支持字节粒度的访问。这就需要一个管理页的中间层,但 Andy Pavlo 教授坚持不使用 mmap 将页管理权力让渡给操作系统,因此实验一 的目标便在于主动管理磁盘中的页(page)在内存中的缓存,从而,最小化磁盘访问次数(时间上)、最大化相关数据连续(空间上)。
该实验可以分解为相对独立的两个子任务:
- 维护替换策略的:LRU replacement policy
- 管理缓冲池的:buffer pool manager
两个组件都要求线程安全。
本文首先从基本概念、核心数据流总体分析下实验内容,然后分别对两个子任务进行梳理。
作者:青藤木鸟 https://www.qtmuniao.com/2021/02/10/cmu15445-project1-buffer-pool/, 转载请注明出处
实验分析
刚开始写实验代码的时候,感觉细节很多,实现时很容易丢三落四。但随着实现和思考的深入,渐渐摸清了全貌,发现只要明确几个基本概念和核心数据流,便能够提纲挈领。
基本概念
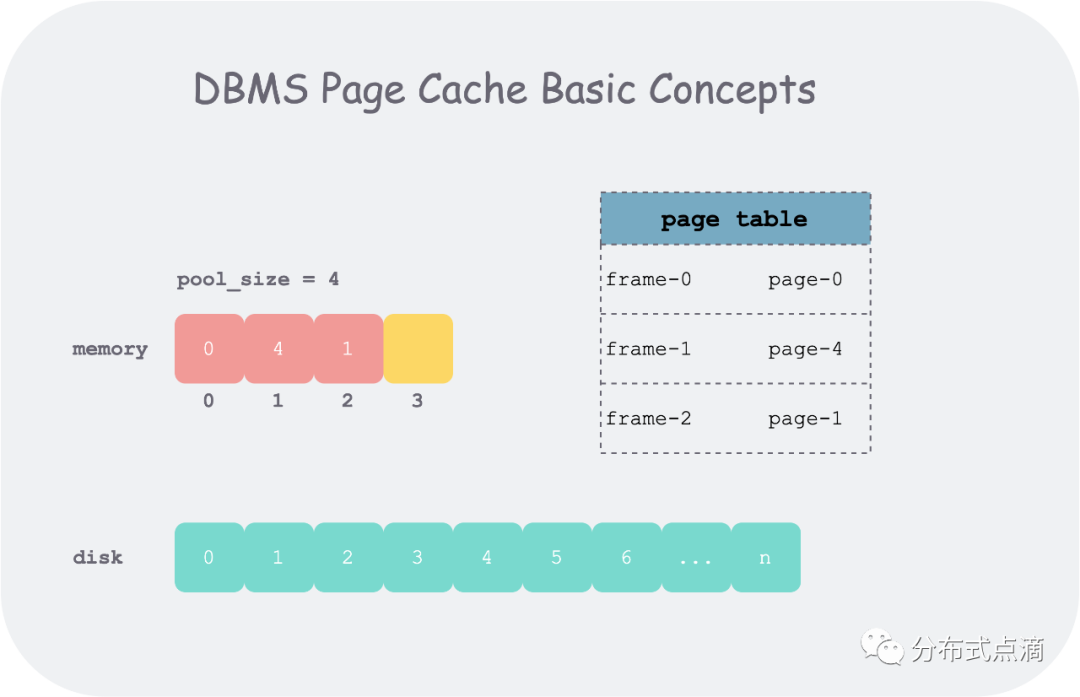
buffer pool 的操作的基本单位为一段逻辑连续的字节数组,在磁盘上表现为页(page),有唯一的标识 page_id;在内存中表现为帧(frame),有唯一的标识 frame_id。为了记下哪些 frame 存的哪些 page,需要使用一个页表(page table)。
下边行文可能会混用 page 和 frame,因为这两个概念都是 buffer pool 管理数据的基本单位,一般为 4k,其区别如下:
page id 是这一段单位数据的全局标识,而 frame id 只是在内存池(frame 数组)中索引某个 page 下标
page 在文件系统中是一段逻辑连续的字节数组;在内存中,我们会给其附加一些元信息:pin_count_,is_dirty_
基本概念
而管理帧的内存池大小一般来说是远小于磁盘的,因此在内存池满了后,再从磁盘加载新的页到内存池,需要 某种替换策略(replacer)将一些不再使用的页踢出内存池以腾出空间。
核心数据流
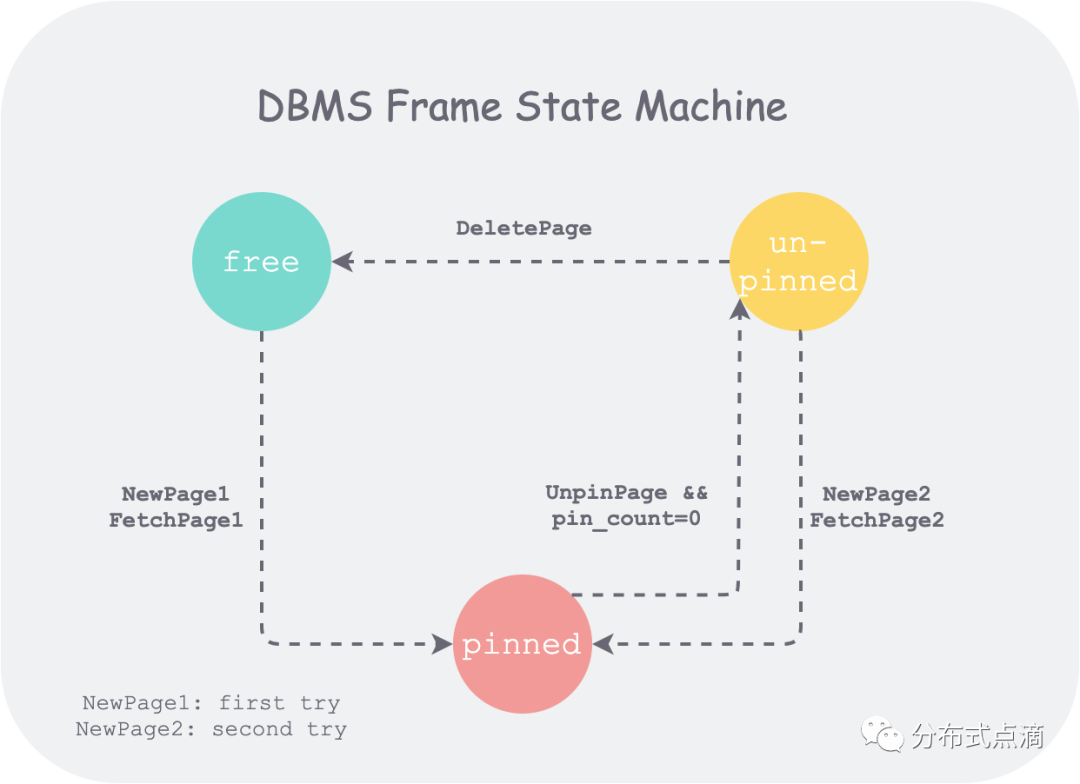
先说结论,buffer pool manager 的实现核心,在于对内存池中所有 frame 的状态的管理。因此,如果我们能梳理出 frame 的状态机,便可以把握好核心数据流。
buffer pool 维护了一个 frame 数组,每个 frame 有三种状态:
- free:初始状态,没有存放任何 page
- pinned:存放了 thread 正在使用的 page
- unpinned:存放了 page,但 page 已经不再为任何 thread 所使用
而待实现函数:
- FetchPageImpl(page_id)
- NewPageImpl(page_id)
- UnpinPageImpl(page_id, is_dirty)
- DeletePageImpl(page_id)
便是驱动状态机中上述状态发生改变的动作(action),状态机如下:
frame 状态机
对应到实现时数据结构上:
- 保存 page 数据的 frame 数组为 pages_
- 所有 free frame 的索引(frame_id)保存在 free_list_ 中
- 所有 unpinned frame 的索引保存在 replacer_ 中
- 所有 pinned frame 索引和 unpinned frame 的索引保存在 page_table_ 中,并通过 page 中 pin_count_ 字段来区分两个状态。
上图中,NewPage1 和 NewPage2 表示在 NewPage 函数中,每次获取空闲 frame 时,会先去空闲列表(freelist_)中取一个 free frame,如果取不到,才会去 replacer_ 中驱逐一个 unpinned 的 frame 后使用。这体现了 buffer pool manager 实现的一个目标:最小化磁盘访问,原因后面分析。
实验组件
把握了本实验的基本概念和核心数据流后,再来分析两个子任务。
TASK #1 - LRU REPLACEMENT POLICY
以前在 LeetCode 上写过相关实现,因此很自然的带入之前经验,但随后发现这两个接口有一些不同。
LeetCode 上提供的是 kv store 接口,在 get/set 的时候完成新老顺序的维护,并在内存池满后自动替换最老的 KV。
但本实验提供的是 replacer 接口,维护一个 unpinned 的 frame_id 列表 ,在调用 Unpin 时将 frame_id 加入列表并维护新老顺序、在调用 Pin 时将 frame_id 从列表中摘除、在调用Victim 的时候将最老的 frame_id 返回。
当然,本质上还是一样,因此本实验我也是采用 unordered_map 和 doubly linked list 的数据结构,实现细节不再赘述。需要注意的是,如果 Unpin 时发现 frame_id 已经在 replacer 中,则直接返回,并不改变列表的新老顺序。因为逻辑上来说,同一个 frame_id,并不能被 Unpin多次,因此我们只需要考虑 frame_id 第一次 Unpin。
放到更大的语境中,本质上,replacer 就是一个维护了回收顺序的回收站,即我们将所有 pin_count_ = 0 的 page 不直接从内存中删除,而是放入回收站中。根据数据访问的时间局部性原理,刚刚被访问的 page 很可能再次被访问,因此当我们不得不从回收站中真删(Victim)一个 frame 时,需要删最老的 frame。当之后我们想访问一个刚加入回收站的数据时, 只需要将 page 从这个回收站中捞出来,从而省去一次磁盘访问,这也就达到了最小化磁盘访问的目标。
TASK #2 - BUFFER POOL MANAGER
在实验分析部分已经把核心逻辑说的差不多了,这里简单罗列一下我实现中遇到的问题。
page_table_ 的范围。在最初实现时,画出 frame 的状态机之后,感觉 page_table_ 中只放 pinned frame id 很完美:可以使 frame id 按状态互斥的分布在 free_list_ 、 replacer_ 和 page_table_ 中。但后来发现,如果不将 unpinned frame id 保存在 page_table_ 中,就不能很好地复用 pin_count_ = 0 的 page 了,replacer 也就没有了意义。
dirty page 的刷盘时机。有两种策略,一种是每次 Unpin 的时候都刷,这样会刷比较频繁,但能保证异常掉电重启后内容不丢;一种是在 replacer victimized 的时候 lazily 的刷,这样能保证刷的次数最少。这是性能和可靠性取舍,仅考虑本实验,两者肯定都能过。
NewPage 不要读盘。这个就是我写的 bug 了,毕竟 NewPage 的时候,磁盘上根本没有对应 page 的内容,因此会报如下错误:
- 2021-02-18 16:53:47 [autograder/bustub/src/storage/disk/disk_manager.cpp:121:ReadPage] DEBUG - Read less than a page
- 2021-02-18 16:53:47 [autograder/bustub/src/storage/disk/disk_manager.cpp:108:ReadPage] DEBUG - I/O error reading past end of file
复用 frame 时清空元信息。在复用一个从 replacer 中驱逐的 frame 时尤其要注意,使用前一定要将 pin_count_\is_dirty_ 这些字段清空。当然,在 DeletePage 的时候,也需要注意将 page_id_ 置为 INVALID_PAGE_ID 、清空上述字段。否则,再次使用时, 如果 pin_count_ 在 Unpin 后,数值不为 0,会导致 DeletePage 时删不掉该 page。
锁的粒度。最粗暴的就是每个函数范围粒度加锁即可,后期如果需要优化,再将锁的粒度变细。
实验代码
以 FetchPageImpl 为例强调下一些实现的细节,注意到,实验已经通过注释给出了实现框架。
我使用中文注释注出了一些我认为需要注意的点。
- Page *BufferPoolManager::FetchPageImpl(page_id_t page_id) {
- // a. 使用自动获取和释放锁
- std::scoped_lock<std::mutex> lock(latch_);
- // 1. Search the page table for the requested page (P).
- // 1.1 If P exists, pin it and return it immediately.
- auto target = page_table_.find(page_id); // b. 判断存在与访问数据只用一次查找
- if (target != page_table_.end()) {
- frame_id_t frame_id = target->second;
- // c. 通过指针运算获取 frame_id 处存放的 Page 结构体
- Page *p = pages_ + frame_id;
- p->pin_count_++;
- replacer_->Pin(frame_id); // d. 将对应 page 从“回收站”中捞出
- return p;
- }
- // 1.2 If P does not exist, find a replacement page (R) from either the free list or the replacer.
- // Note that pages are always found from the free list first.
- frame_id_t frame_id = -1;
- Page *p = nullptr;
- if (!free_list_.empty()) {
- frame_id = free_list_.back(); // e. 在结尾处操作效率高一点
- free_list_.pop_back();
- assert(frame_id >= 0 && frame_id < static_cast<int>(pool_size_));
- p = pages_ + frame_id;
- // f. 从 freelist 中获取的 dirty page 已经在 delete 时写回了
- } else {
- bool victimized = replacer_->Victim(&frame_id);
- if (!victimized) {
- return nullptr;
- }
- assert(frame_id >= 0 && frame_id < static_cast<int>(pool_size_));
- p = pages_ + frame_id;
- // 2. If R is dirty, write it back to the disk.
- if (p->IsDirty()) {
- disk_manager_->WritePage(p->GetPageId(), p->GetData());
- p->is_dirty_ = false;
- }
- p->pin_count_ = 0; // g. 将元信息 pin_count_ 清空
- }
- // 3. Delete R from the page table and insert P.
- page_table_.erase(p->GetPageId()); // h. 时刻注意区分 p->GetPageId() 与 page_id 是否相等,别混用
- page_table_[page_id] = frame_id;
- // 4. Update P's metadata, read in the page content from disk, and then return a pointer to P.
- p->page_id_ = page_id;
- p->ResetMemory();
- disk_manager_->ReadPage(page_id, p->GetData());
- p->pin_count_++;
- return p;
- }
实验相关 autograder 可以在 FAQ 中找到注册地址和邀请码,提交代码的时候最好不要提交 github 仓库地址,会有很多格式问题。可以每次按照实验页面的指示,将相关文件按目录结构达成 zip 包提交即可。
提交事项
仔细阅读实验描述,提交前需要注意的事项:
- 在 build 目录运行 make format ,自动格式化。
- 在 build 目录运行 make check-lint,检查一些语法问题。
- 自己针对每个函数在本地设计一些测试,写到相关文件(本实验 buffer_pool_manager_test.cpp )中,并且打开测试开关,在 build 文件夹下,编译 make buffer_pool_manager_test,运行 ./test/buffer_pool_manager_test
贴一个 project1 autograder 的实验结果:
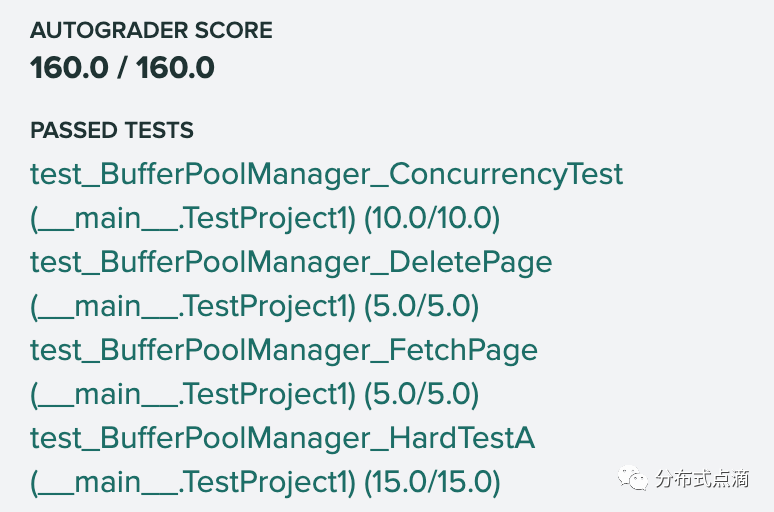
autograder 结果
小结
这是 cmu15445 第一个实验,实现了在磁盘和内存间按需搬运页(page)的 buffer pool manager。本实验的关键之处在于把握基本概念,梳理出核心数据流,在此基础上注意一些实现的细节即可。



















