Kubernetes是一个开源的容器编排引擎,用来对容器化应用进行自动化部署、 扩缩和管理。然而并非所有项目都需要微服务化,也并非所有项目需要Kubernetes,例如管理后台、定时任务服务、非分布式数据库等就没有必要容器化部署,Kubernetes更适合部署分布式微服务应用。
这两天笔者看完了《Kubernetes源码剖析》这本书,由于Kubernetes是用go语言编写,很多Java程序员可能没学过go语言,为了分享这本书,笔者摘录了书中的一些关键知识点整理成这篇文章,也希望通过这篇文章帮助大家理解Kubernetes。
(之前公司内部技术分享画的学习路线思维导图)
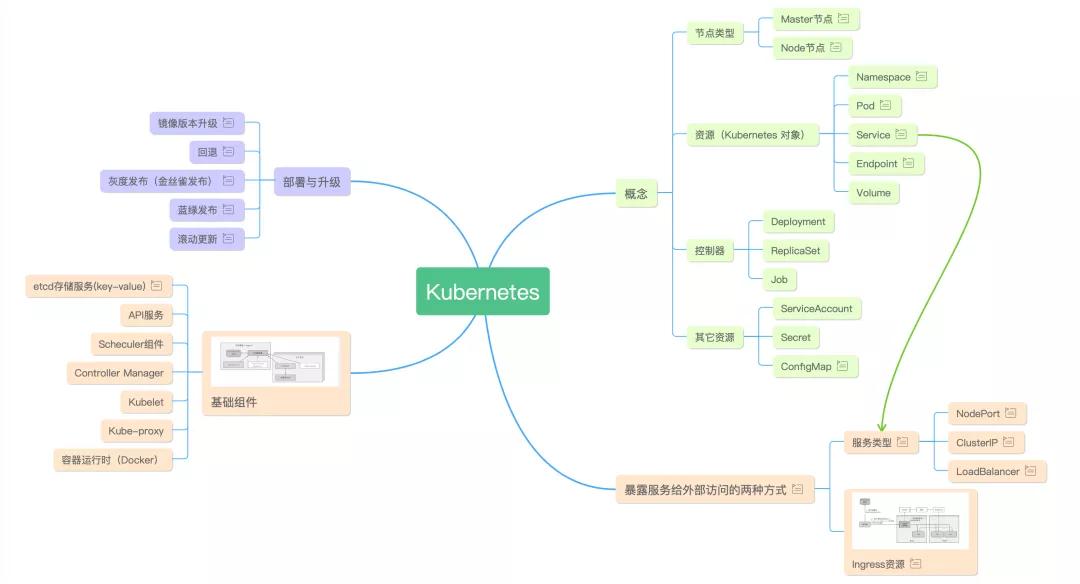
Kubernetes架构
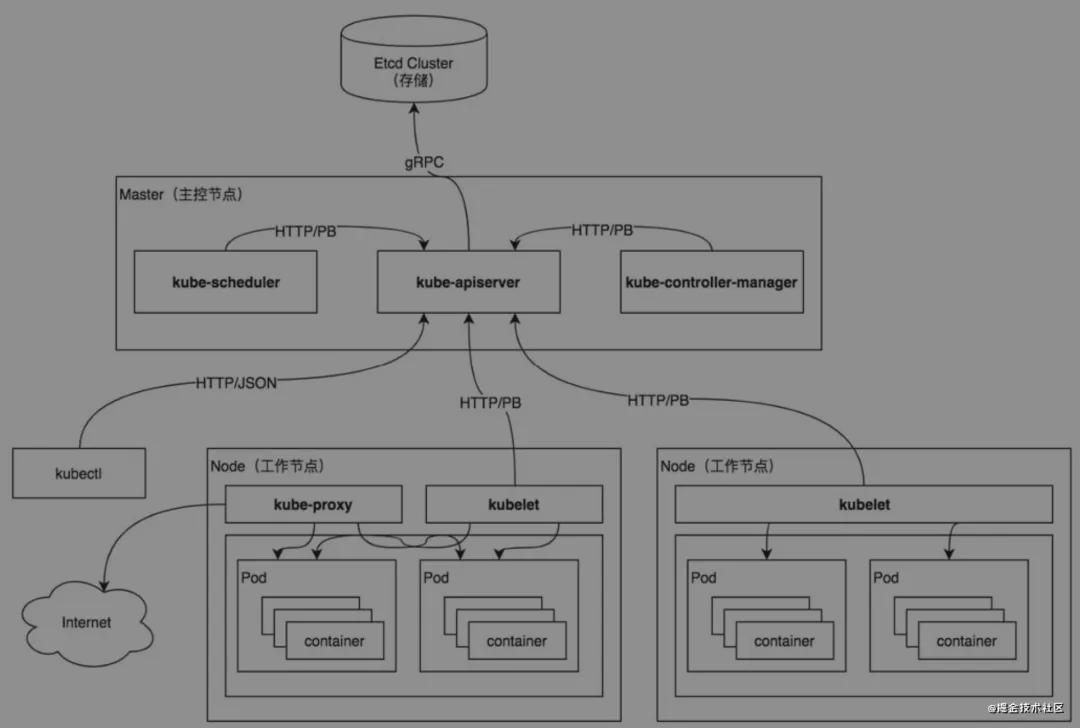
图片 (图片来源:《Kubernetes源码剖析》.Kubernetes架构图)
Kubernetes系统采用C/S架构设计,系统架构分为Master、Node两部分,Master为Server端(主控节点),Node为Client端(工作节点)。
Master主控节点作为集群的大脑负责管理所有工作节点(Node)、负责调度Pod运行在哪些工作节点上、负责控制集群运行过程中的所有状态,其中节点表示云虚拟服务器。
Node工作节点负责管理容器、监控和上报运行在本节点上的所有Pod的运行状态。
运行在Master主控节点上的组件有kube-apiserver、kube-controller-manager、kube-scheduler组件。
kube-apiserver负责将Kubernetes“资源组/资源版本/资源”以RESTful风格的形式对外暴露并提供服务。集群中的所有组件都通过kube-apiserver组件操作资源对象。kube-apiserver组件也是集群中唯一与Etcd集群进行交互的核心组件。
kube-controller-manager管理Kubernetes集群中的节点(Node)、Pod副本、服务、端点(Endpoint)、命名空间(Namespace)、服务账户(ServiceAccount)等。负责确保Kubernetes系统的实际状态收敛到所需状态,其默认提供了一些控制器(Controller),例如DeploymentControllers控制器、StatefulSet控制器、Namespace控制器及PersistentVolume控制器等,每个控制器通过kube-apiserver组件提供的接口实时监控整个集群每个资源对象的当前状态,当发生故障而导致系统状态出现变化时,尝试将系统状态修复到期望状态。
kube-scheduler调度器组件负责在Kubernetes集群中为一个Pod资源对象找到合适的节点并在该节点上运行。调度器每次只调度一个Pod资源对象,为每一个Pod资源对象寻找合适节点的过程是一个调度周期。调度器组件监控整个集群的Pod资源对象和Node资源对象,在监控到新的Pod资源对象时通过调度算法为其选择最优节点。
运行在Node工作节点上的组件有kubelet、kube-proxy、container组件。
kubelet负责接收、处理、上报kube-apiserver组件下发的任务。kubelet进程启动时会向kube-apiserver注册节点(Node)自身信息。它主要负责所在节点(Node)上的Pod资源对象的创建、修改、监控、删除、驱逐及Pod生命周期管理等。kubelet组件实现了3种开放接口,分别是CRI(容器运行时接口)、CNI(容器网络接口)和CSI(容器存储接口)。
kube-proxy作为节点上的网络代理,运行在每个Kubernetes节点上。它监控kube-apiserver的服务和端点资源变化,并通过iptables/ipvs等配置负载均衡器,为一组Pod提供统一的TCP/UDP流量转发和负载均衡功能,但只会向Kubernetes服务及其后端Pod发出请求。
资源概念
在kubernetes中,资源是最核心的概念,整个生态系统都围绕资源运作。Kubernetes本质上是一个资源控制系统,负责注册、管理、调度资源并维护资源的状态。
Kubernetes将资源分组和版本化:
- Group:资源组
- Version:资源版本
- Resource:资源
- Kind:资源种类(分类)
资源对象与资源操作方法:
- 资源对象(Resource Object):一个资源对象包含的字段有资源组、资源版本、资源种类;
- 资源操作方法(Verbs):每一个资源都拥有资源操作方法,实现对Etcd的CURD操作,kubernetes支持的8种资源操作方法是create、delete、deletecollection、get、list、patch、update、watch。
Kubernetes支持两类资源组,分别是拥有组名的资源组和没有组名的资源组:
拥有组名的资源组:其表现形式为
没有组名的资源组:核心资源组,其表现形式为
Kubernetes提供的Restful API使用GVR(资源分组/资源版本/资源)生成path,如下表格示例:
| PATH | 资源 | 资源操作方法 |
|---|---|---|
| /api/v1/configmaps | ConfigMap | create,delete,deletecollection,get,list,patch,update,watch |
| /api/v1/pods | Pod | create,delete,deletecollection,get,list,patch,update,watch |
| /api/v1/services | Service | create,delete,deletecollection,get,list,patch,update,watch |
拥有组名的资源组的path以/apis为前缀,没有组名的资源组的path以/api为前缀。以/api/v1/configmaps为例,v1为资源版本号、configmaps为资源名称。
资源还可以拥有子资源,例如pods有logs子资源。用kubectl查询日记则命令为kubectl logs [pod],对应API的path为:/api/v1/pods/logs。
kubernetes支持8种资源操作方法,但并非每种资源都需要支持8种资源操作方法。如pods/logs子资源就只拥有get操作方法,因为日志只需要执行查看操作。
Kubernetes系统支持命名空间(Namespace),每个命名空间相当于一个“虚拟集群”,不同命名空间之间可以进行隔离。命名空间常用于划分不同的环境,例如生产环境、测试环境、开发环境等使用不同的命名空间进行划分,也可用于划分无关联的项目,如用于划分项目A、项目B。
资源对象描述文件定义
Kubernetes资源可分为内置资源和自定义资源,它们都通过资源对象描述文件进行定义。一个资源对象需要用5个字段来描述,分别是Group/Version、Kind、MetaData、Spec、Status。
以Service资源描述文件为例,配置如下:
apiVersion: v1
kind: Service
metadata:
name: test-service
namespace: default
spec:
....
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- apiVersion:即Group/Version,Service在核心资源组,所以没有资源组名,v1为资源版本;
- Kind:资源种类;
- MetaData:定义元数据信息,如资源名称、命名空间;
- Spec:描述Service的期望状态;
- Status:描述资源对象的实际状态,隐藏的,不需要配置,由Kubernetes系统提供和更新。
Pod调度
Pod资源对象支持优先级与抢占机制。当kube-scheduler调度器运行时,根据Pod资源对象的优先级进行调度,高优先级的Pod资源对象排在调度队列的前面,优先获得合适的节点(Node),再为低优先级的Pod资源对象选择合适的节点。
当高优先级的Pod资源对象没有找到合适的节点时,调度器会尝试抢占低优先级的Pod资源对象的节点,抢占过程是将低优先级的Pod资源对象从所在的节点上驱逐走,使高优先级的Pod资源对象运行在该节点上,被驱逐走的低优先级的Pod资源对象会重新进入调度队列并等待再次选择合适的节点。
在默认的情况下,若不启用优先级功能,则现有Pod资源对象的优先级都为0。为Pod资源配置优先级的步骤如下:
1、通过PriorityClass资源对象描述文件创建PriorityClass资源对象,配置文件如下:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: MainResourceHighPriority
value: 10000
globalDefault: false
description: "highest priority"
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- value:表示优先级,值越高优先级越高;
- globalDefault:是否为全局默认,当Pod没有指定使用的优先级时默认使用此优先级。
- 2、修改Pod资源对象描述文件,为Pod指定优先级
通过Deployment配置Pod资源时,只需要在Deployment描述文件的Spec下的Spec添加一项名为priorityClassName的配置,如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-server
namespace: default
spec:
replicas: 1
# 配置pod
spec:
containers:
- name: test-server-pod
image: test-server:latest
imagePullPolicy: IfNotPresent
ports:
- name: http-port
containerPort: 8080
envFrom:
- configMapRef:
name: common-config
serviceAccountName: admin-sa
priorityClassName: MainResourceHighPriority
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
亲和性调度
与调度相关的还有亲和性调度。kube-scheduler调度器自动为Pod资源对象选择全局最优或局部最优节点(即节点的硬件资源足够多、节点负载足够小等)。在生产环境中,一般希望能够更多地干预Pod资源对象的调度,例如,将不需要依赖GPU硬件资源的Pod资源对象分配给没有GPU硬件资源的节点,将需要依赖GPU硬件资源的Pod资源对象分配给具有GPU硬件资源的节点。开发者只需要在这些节点上打上相应的标签,然后调度器就可以通过标签进行Pod资源对象的调度,这种调度策略被称为亲和性和反亲和性调度。
- 亲和性(Affinity):用于多业务就近部署,例如允许将两个业务(如广告点击服务与IP查询服务)的Pod资源对象尽可能地调度到同一个节点上,减少网络开销;
- 反亲和性(Anti-Affinity):允许将一个业务的Pod资源对象的多副本实例调度到不同的节点上,以实现高可用性,例如订单服务的POD期望有三个副本,将三个副本部署在不同的节点上。
Pod资源对象目前支持两种亲和性和一种反亲和性:
- NodeAffinity:节点亲和性,将某个Pod资源对象调度到特定的节点上,如需要GPU的POD调度到有GPU的节点上;
- PodAffinity:Pod资源对象亲和性,将某个Pod资源对象调度到与另一个Pod资源对象相邻的位置,例如调度到同一主机,调度到同一硬件集群,调度到同一机房,以缩短网络传输延时;
- PodAntiAffinity:Pod资源对象反亲和性,将一个Pod资源对象的多副本实例调度到不同的节点上,调度到不同的硬件集群上等,这样可以降低风险并提升Pod资源对象的可用性。
内置调度算法
kube-scheduler调度器默认提供了两类调度算法,分别是预选调度算法和优选调度算法。
- 预选调度算法:检查节点是否符合运行“待调度Pod资源对象”的条件,如果符合条件,则将其加入可用节点列表;
- 优选调度算法:为每一个可用节点计算出一个最终分数,kube-scheduler调度器会将分数最高的节点作为最优运行“待调度Pod资源对象”的节点。
本文转载自微信公众号「Java艺术」,可以通过以下二维码关注。转载本文请联系Java艺术公众号。