本文转载自微信公众号「KK架构师」,作者wangkai。转载本文请联系KK架构师公众号。
一、Flink Api 的分层抽象
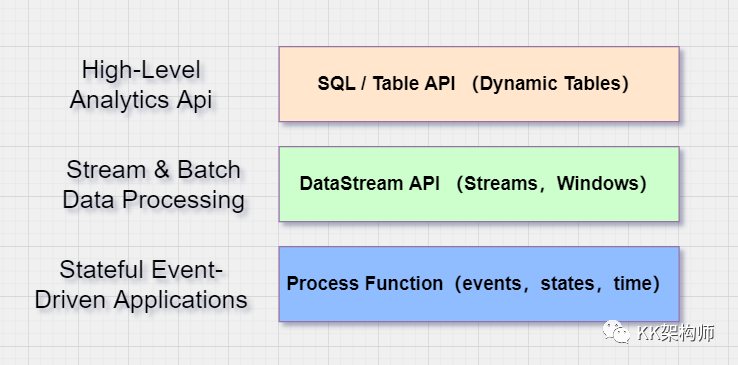
如上图,最下面一层是 Process Function ,可以去做一些有状态的计算,注册 Timer 定时器,可以做更复杂的操作,灵活性更高,可以做非常复杂的定制开发;
第二层是 DataStream Api,基于 Process Function,封装了很多的操作。比如可以方便做一个 KeyBy 操作 + Window 的聚合;
最上面一层是 关系型 Api,是在 DataStream Api 之上的更高级的抽象,我们可以借助 SQL 这种非常经典的稳定的语言,来构建实时流程序。
二、为什么要提供 Table Api 和 SQL?
1. 开发繁琐
DataStream Api / Process Function 更加面向的是开发者,想要开发出合理的 Flink 程序,至少需要具备以下技能:
- 具有 Java 、Scala 开发经验;
- 需要对 Time、State 以及 Window 等流式概念有非常深入的了解;
- 具有分布式处理的经验和知识;
- 具有作业调优的经验;
这样的话,对数据分析人员和业务人员很不友好,使用起来学习成本非常高,望尘莫及。
并且开发起来非常繁琐,开发应用需要使用 Function 接口,即使是一个简单的过滤也要实现一个 FilterFunction 匿名类,而使用 Table Api 则简单很多。
2. 代码不通用
Table Api 和 SQL 是流批通用的,代码完全可以复用。不必流式程序使用 DataStream Api,批处理使用 DataSet Api (注:社区未来可能会废弃 Dataset Api,统一使用 DataStream Api 来开发批流程序)。
3. 框架很难优化
在使用 DataStream Api 和 DataSet Api 开发应用的时候,Flink 框架只能进行非常有限的优化,需要开发者非常谨慎的编写高效的应用程序。
而使用 Table Api 或 SQL,则可以使用 Calcite 的 SQL 优化器,更容易写出执行效率高的应用。
二、Table Api / SQL 是如何转换为程序运行的?
如下图所示
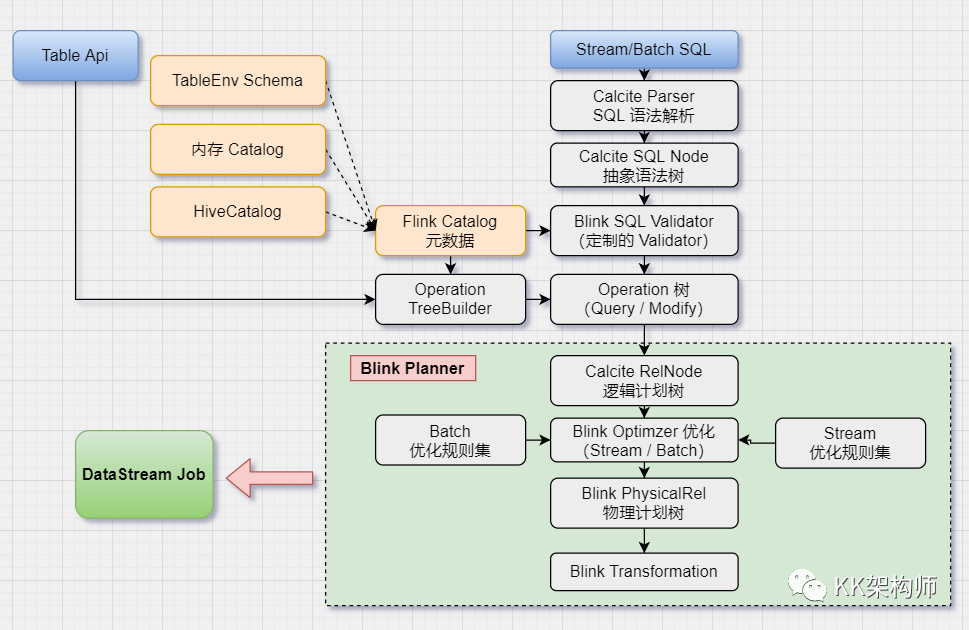
SQL 执行被分成两个大的阶段,从 SQL 语句到 Operation,从 Operation 到 Transformation,然后就进入分布式执行的阶段。
1. 前置知识:Apache Calcite
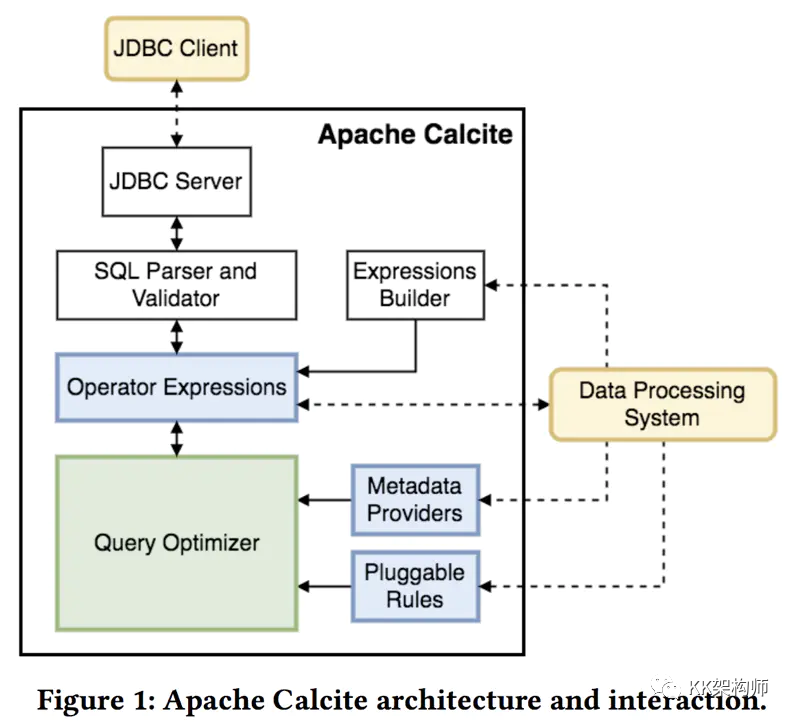
Apache Calcite 是个动态数据管理框架,具备很多数据库管理系统的功能,如 SQL 解析,SQL 校验,SQL 查询优化,SQL 生成以及数据连接查询等,但是并不存储元数据和基本数据,不包含处理数据的算法。
由于舍弃了这些功能,Calcite 可以在应用和数据存储,数据处理引擎之间很好的扮演中介的角色。
它不受上层编程语言的限制,前端可以使用 SQL、Pig、Cascading 等语言,只要通过 Calcite 提供的 SQL Api 将它们转化成关系代数的抽象语法树即可,并根据一定的规则和成本对抽象语法树进行优化,最后推给各个数据处理引擎来执行。
所以 Calcite 不涉及物理规划层,它通过扩展适配器来连接多种后端的数据源和数据处理引擎,如 Hive,Drill,Flink,Phoenix。
2. SQL 语句到 Operation 过程
首先使用 Calcite 对 SQL 语句进行解析,获取 SQL Node,再根据不同的 SQL 类型分别进行转换,校验语法的合法性,再根据语句类型(DQL、DML、DDL)转换成对应的算子树。
对于 SQL 查询语句而言,会转换为 QueryOperation 树。
3. Operation 到 Transformation 过程
首先 Operation 先转换为 Calcite 的逻辑计划树,再对应地转换为 Flink 的逻辑计划树,然后进行优化。
优化后的逻辑树转换为 Flink 的物理计划,然后物理计划通过代码生成算子、UDF、表达式等代码,包装到 Transformation 中,形成 Transformation 流水线,再转换为 StreamGraph ,最终就可以提交到 Flink 集群真正运行起来了。
(后面会专门写源码分析的文章,来重点讲述这两部分的内容,持续关注我)
4. 元数据
元数据是是 Flink SQL 处理数据非常重要的一个部分,元数据描述了 Flink 处理的读取和写出的数据的结构以及数据的访问方法等信息,没有元数据,Flink 就无法对 SQL 进行校验和优化了。
元数据包含以下信息:
- 库
- 表
- 视图
- UDF
- 表字段
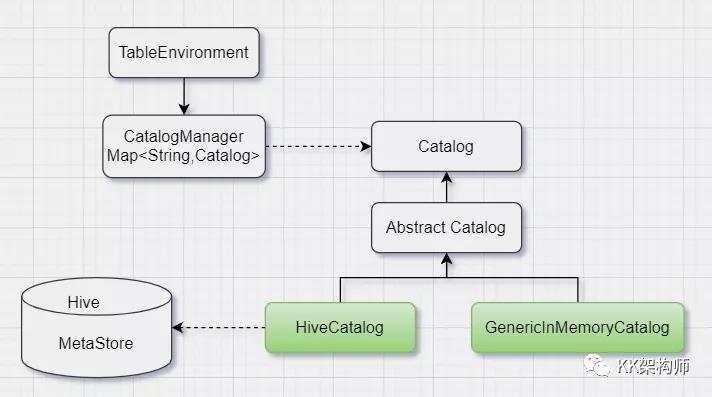
如上图所示,在 Flink 中,Catalog 是元数据的核心抽象,目前 Flink 实现了内存小 GenericMemoryCatalog 和 HiveCatalog 两种 Catalog。
5. 优化器
SQL 查询优化是来自数据库系统的概念,查询优化器是关系型数据库管理系统的核心之一,决定对特定的查询使用哪些索引、哪些关联算法,从而使 SQL 高效运行。
SQL 优化器很大程度上决定了一个系统的执行性能。
查询优化器分成两类,基于规则的优化器(Rule-Based Optimizer,RBO)和基于代价的优化器(Cost-Based Optimizer,CBO)。
RBO 规则优化,主要就是等价改变查询语句的形式,以便产生更好的逻辑执行计划,比如重写用户的查询(谓词推进,物化视图重写,视图合并等),然后还需要将逻辑执行计划变成物理执行计划。
CBO 代价优化,除了做上述 RBO 的规则优化外,还会通过复杂的算法统计信息,统计各个执行计划的执行成本,从不同的执行计划中选择出执行代价最小的一个计划,转换为 Flink 的执行计划。
三、总结
Flink Table Api / SQL 提供了对用户友好的接口来更高效的完成实时流式程序的开发。
Flink 依托 Apache Calcite 提供的 SQL 解析、优化框架,解析构建为逻辑计划树,通过 Planner 层层优化为 Flink 可以运行的内部结构,最终提交到 Flink 集群上运行。