












本文转载自微信公众号「猿天地」,作者尹吉欢。转载本文请联系猿天地公众号。
为什么要用 alertManager
alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持多种告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组等,超级好用。
其实 Grafana 也自带了告警功能,本来想直接用 Grafana 的告警功能,这样就不用多部署一个组件了,试用了一下 Grafana 的告警,不是很好用,然后就放弃了。
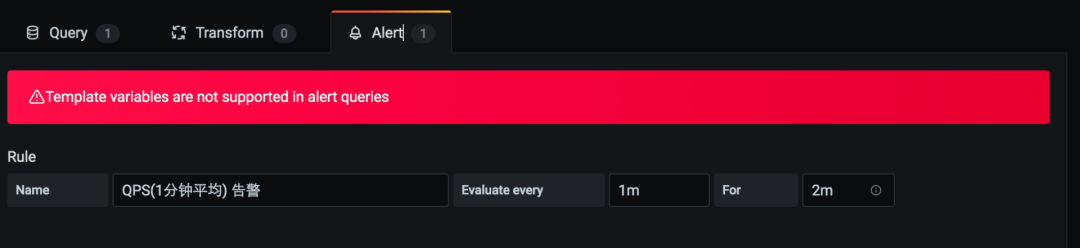
看上图,最难受的就是 Template variables are not supported in alert queries 这段话了,不能用于变量类型的模板。下面来解释下这个问题:
指标查询语句如下:
- sum(rate(http_server_requests_seconds_count{application="$application", instance="$instance"}[1m]))
其实是根据 application 和 instance 来查询的,也就是在查询的时候可以选择哪个应用,哪个实例进行数据的查看。

但是你如果要用 Grafana 的告警,就不能这么写,那要怎么写呢?把变量去掉。
假如我的 A 服务有 5 个实例,那么你就得配置 5 个查询语句,如下:
- sum(rate(http_server_requests_seconds_count{application="a-service", instance="10.11.11.12"}[1m]))
- sum(rate(http_server_requests_seconds_count{application="a-service", instance="10.11.11.13"}[1m]))
- sum(rate(http_server_requests_seconds_count{application="a-service", instance="10.11.11.14"}[1m]))
- sum(rate(http_server_requests_seconds_count{application="a-service", instance="10.11.11.15"}[1m]))
- sum(rate(http_server_requests_seconds_count{application="a-service", instance="10.11.11.16"}[1m]))
到了这一步我就直接放弃了,太难用了,不知道有没有其他的方式能够解决这个问题,反正我是投向了 alertmanager。
部署 alertManager
部署 alertmanager 之前我们首先部署一个钉钉消息的转发服务,也就是当有告警的时候,alertmanager 会调用这个转发服务将告警内容发送至钉钉。
- docker run -d -p 8060:8060 --name webhook timonwong/prometheus-webhook-dingtalk --ding.profile="webhook1=
- https://oapi.dingtalk.com/robot/send?access_token=你的token"
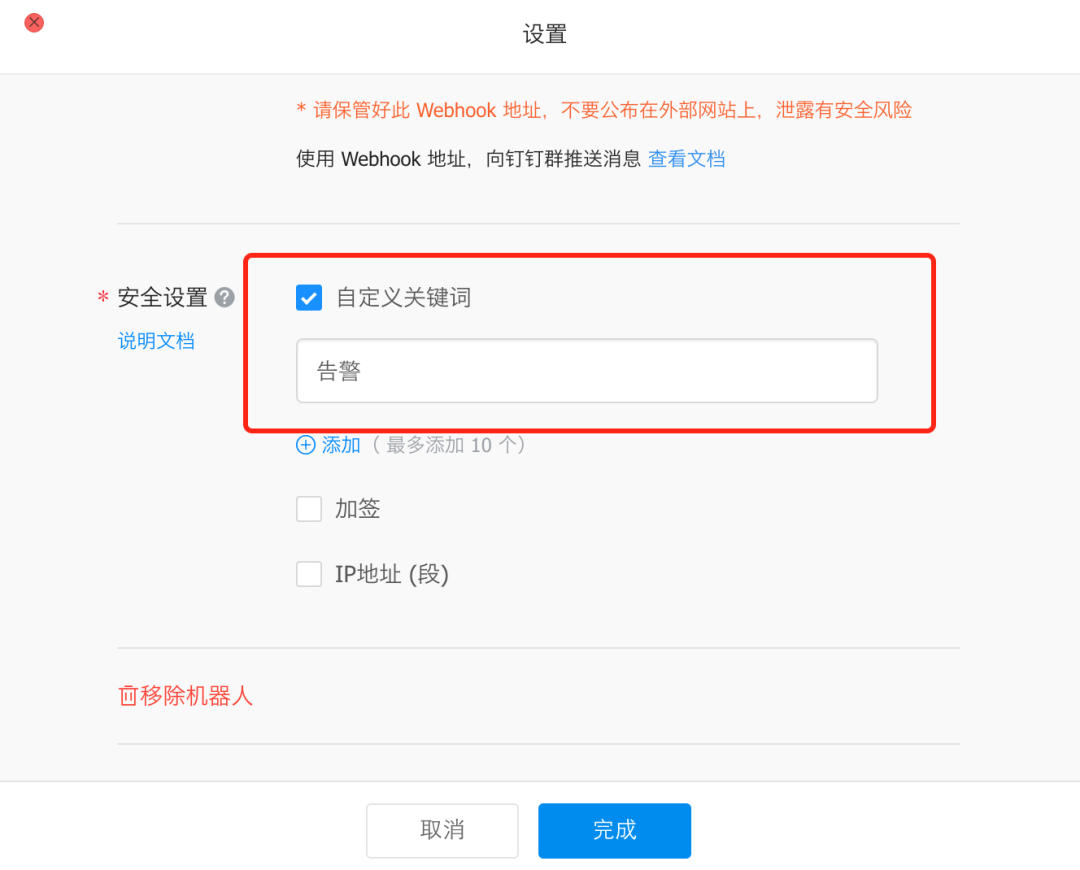
钉钉机器人需要自定义关键词来匹配告警信息,否则接收不到消息。
直接用 Docker 来部署 alertmanager,命令如下:
- docker run -d --name alertmanager -p 9093:9093 -v /opt/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager:latest
alertmanager.yml
- global:
- resolve_timeout: 5m
- route:
- receiver: webhook
- group_wait: 30s
- group_interval: 5m
- repeat_interval: 5m
- group_by: [alertname]
- routes:
- - receiver: webhook
- group_wait: 10s
- receivers:
- - name: webhook
- webhook_configs:
- - url: http://10.100.0.168:8060/dingtalk/webhook1/send
- send_resolved: true
webhook 的通知地址我们配置成上面我们部署的钉钉转发服务的 IP+Port 就可以了。
修改 prometheus 的配置文件,增加 alertmanager 的配置。
prometheus.yml
- # Alertmanager configuration
- alerting:
- alertmanagers:
- - static_configs:
- - targets: ["10.100.0.168:9093"]
- rule_files:
- - "/etc/prometheus/rules.yml"
配置告警规则
rules.yml
- groups:
- - name: qps
- rules:
- - alert: QPS告警
- expr: (sum by(instance,application)(rate(http_server_requests_seconds_count[1m]))) > 100
- for: 1m
- labels:
- severity: warning
- annotations:
- description: "应用:{{ $labels.application }} 实例:{{ $labels.instance }} QPS超过100 (当前值: {{ $value }})"
- summary: ""
- - alert: 应用下线告警
- expr: up == 0
- for: 0m
- labels:
- severity: warning
- annotations:
- description: "应用:{{ $labels.job }} 实例:{{ $labels.instance }} 已下线"
- summary: ""
上面配置了 QPS 告警和应用下线的告警,关于告警规则不做详细讲解,大家可以自己去学习下,当然也有一些可以参考的规则配置,具体可以查看这个网站:https://awesome-prometheus-alerts.grep.to/rules
配置好了后可以在 prometheus 的 Web 控制台 Alerts 中进行查看。
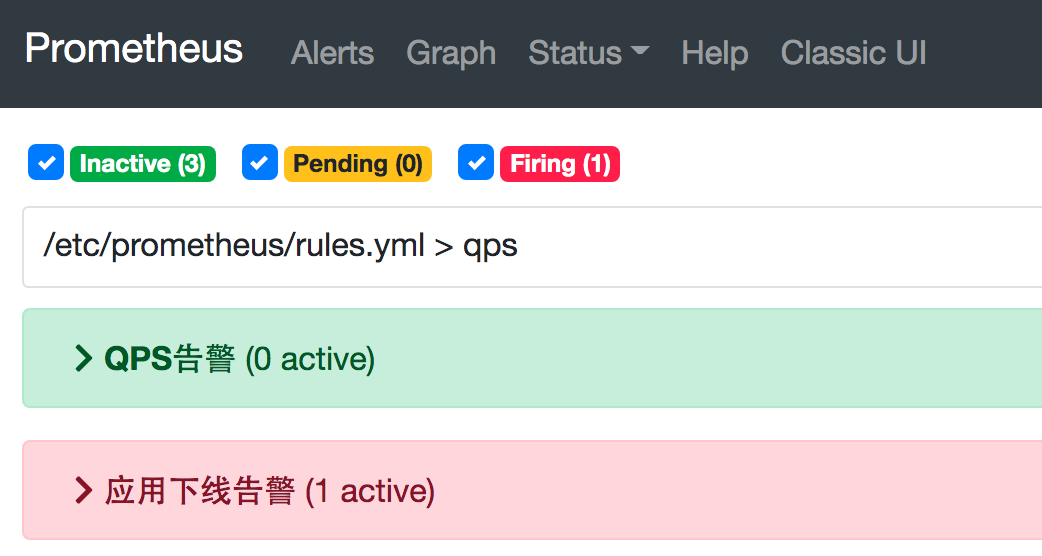
告警效果
遇到的问题
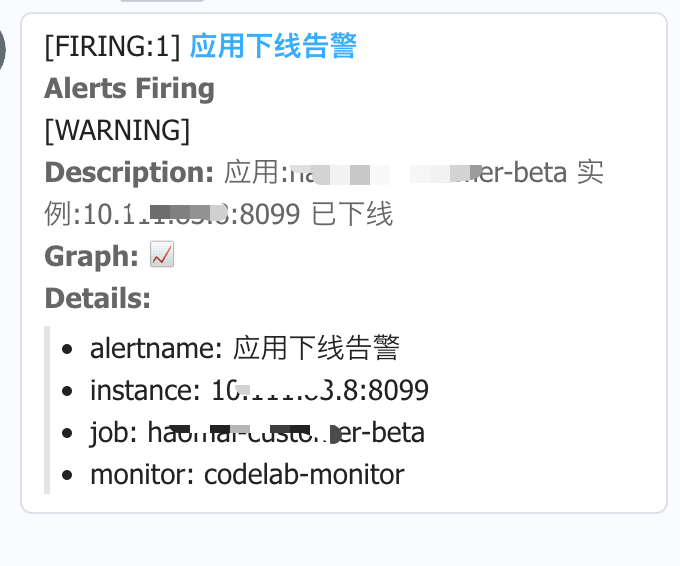
在告警内容显示这块遇到了一个问题,研究了挺长时间的。上面有贴钉钉告警后的消息接入,在描述信息中有写哪个应用,哪个实例出问题了,就是这 2 个具体的信息,在我一开始配置告警规则的时候没有获取到值。

没有获取到值的原因是我的告警规则是这样写的:
- sum (rate(http_server_requests_seconds_count[1m])) > 100
规则本身没问题,也能执行,就是实例值获取不到,后面研究了网上一些其他的规则,发现想要获取具体的值,就得在规则里面包含这些内容才行。
然后就改用下面的方式了,在 sum 后接上要显示的指标名称,就可以在告警信息中显示了。跟 Sql 中的 select 一样,没有写清要哪个字段就不会查询出来。
- (sum by(instance,application)(rate(http_server_requests_seconds_count[1m]))) > 100
关于作者:尹吉欢,简单的技术爱好者,《Spring Cloud 微服务-全栈技术与案例解析》, 《Spring Cloud 微服务 入门 实战与进阶》作者, 公众号猿天地发起人。























